SVM的代码实现-python
隔了好久木有更新了,因为发现自己numpy的很多操作都忘记了,加上最近有点忙.。。
接着上次
我们得到的迭代函数为
首先j != yi
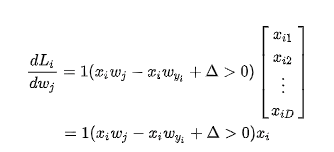
j = yi
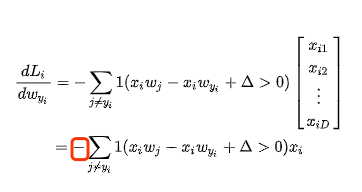
import numpy as np
def svm_loss_naive(W, X, y, reg):
"""
Inputs:
- W: A numpy array of shape (D, C) containing weights.
- X: A numpy array of shape (N, D) containing a minibatch of data.
- y: A numpy array of shape (N,) containing training labels; y[i] = c means
that X[i] has label c, where 0 <= c < C.
- reg: (float) regularization strength Returns a tuple of:
- loss as single float
- gradient with respect to weights W; an array of same shape as W
"""
dW = np.zeros(W.shape) # initialize the gradient as zero
# compute the loss and the gradient
num_classes = W.shape[1]
num_train = X.shape[0]
loss = 0.0
for i in xrange(num_train):
scores = X[i].dot(W)
correct_class_score = scores[y[i]]
for j in xrange(num_classes):
if j == y[i]: #根据公式,正确的那个不用算
continue
# 叠加margin
margin = scores[j] - correct_class_score + 1 # note delta = 1
if margin > 0:
loss += margin
dW[:, y[i]] += -X[i, :] # 根据公式:∇Wyi Li = - xiT(∑j≠yi1(xiWj - xiWyi +1>0)) + 2λWyi
dW[:, j] += X[i, :] # 根据公式: ∇Wj Li = xiT 1(xiWj - xiWyi +1>0) + 2λWj , (j≠yi)
# Right now the loss is a sum over all training examples, but we want it
# to be an average instead so we divide by num_train.
loss /= num_train
dW /= num_train
# Add regularization to the loss.
loss += 0.5 * reg * np.sum(W * W)
dW += reg * W
return loss, dW def svm_loss_vectorized(W, X, y, reg):
"""
Structured SVM loss function, vectorized implementation.Inputs and outputs
are the same as svm_loss_naive.
"""
loss = 0.0
dW = np.zeros(W.shape) # initialize the gradient as zero
scores = X.dot(W) # N by C
num_train = X.shape[0]
num_classes = W.shape[1]
scores_correct = scores[np.arange(num_train), y] # 1 by N
scores_correct = np.reshape(scores_correct, (num_train, 1)) # N by 1
margins = scores - scores_correct + 1.0 # N by C
margins[np.arange(num_train), y] = 0.0
margins[margins <= 0] = 0.0
loss += np.sum(margins) / num_train
loss += 0.5 * reg * np.sum(W * W)
# compute the gradient
margins[margins > 0] = 1.0
row_sum = np.sum(margins, axis=1) # 1 by N
margins[np.arange(num_train), y] = -row_sum
dW += np.dot(X.T, margins)/num_train + reg * W # D by C return loss, dW
还没试一下,近期试一下这个的结果
SVM的代码实现-python的更多相关文章
- 编写高质量代码--改善python程序的建议(六)
原文发表在我的博客主页,转载请注明出处! 建议二十八:区别对待可变对象和不可变对象 python中一切皆对象,每一个对象都有一个唯一的标识符(id()).类型(type())以及值,对象根据其值能否修 ...
- 编写高质量代码--改善python程序的建议(八)
原文发表在我的博客主页,转载请注明出处! 建议四十一:一般情况下使用ElementTree解析XML python中解析XML文件最广为人知的两个模块是xml.dom.minidom和xml.sax, ...
- 抓取oschina上面的代码分享python块区下的 标题和对应URL
# -*- coding=utf-8 -*- import requests,re from lxml import etree import sys reload(sys) sys.setdefau ...
- 编写高质量代码改善python程序91个建议学习01
编写高质量代码改善python程序91个建议学习 第一章 建议1:理解pythonic的相关概念 狭隘的理解:它是高级动态的脚本编程语言,拥有很多强大的库,是解释从上往下执行的 特点: 美胜丑,显胜隐 ...
- 机器学习之支持向量机—SVM原理代码实现
支持向量机—SVM原理代码实现 本文系作者原创,转载请注明出处:https://www.cnblogs.com/further-further-further/p/9596898.html 1. 解决 ...
- 代码块: 以冒号作为开始,用缩进来划分作用域,这个整体叫做代码块,python的代码块可以提升整体的整齐度,提高开发效率
# ### 代码块: 以冒号作为开始,用缩进来划分作用域,这个整体叫做代码块 if 5 == 5: print(1) print(2) if True: print(3) print(4) if Fa ...
- 一行代码让python的运行速度提高100倍
python一直被病垢运行速度太慢,但是实际上python的执行效率并不慢,慢的是python用的解释器Cpython运行效率太差. “一行代码让python的运行速度提高100倍”这绝不是哗众取宠的 ...
- 编写高质量代码--改善python程序的建议(七)
原文发表在我的博客主页,转载请注明出处! 建议三十四:掌握字符串的基本用法 编程有两件事,一件是处理数值,另一件是处理字符串,在商业应用编程来说,处理字符串的代码超过八成,所以需要重点掌握. 首先有个 ...
- 编写高质量代码–改善python程序的建议(五)
原文发表在我的博客主页,转载请注明出处! 建议二十三:遵循异常处理的几点基本原则 python中常用的异常处理语法是try.except.else.finally,它们可以有多种组合,语法形式如下: ...
随机推荐
- 20170531动手实践MyOD——20155312
实践题目 编写MyOD.java 用java MyOD XXX实现Linux下od -tx -tc XXX的功能 对题目分析如下 od的功能(参考Linux od命令详细介绍及用法实例): od命令用 ...
- 9月list
开学了,我已经是大三的老学姐了,难受! 哇,时间过得好快啊,感觉自己快毕业了,肿么办!!! 9月了,快一年了,其实很多东西都变了,比如你. 9月4日的list:
- jquery中ajax处理跨域的三大方式
一.处理跨域的方式: 1.代理 2.XHR2 HTML5中提供的XMLHTTPREQUEST Level2(及XHR2)已经实现了跨域访问.但ie10以下不支持 只需要在服务端填上响应头: ? 1 2 ...
- 2018.11.02 洛谷P2661 信息传递(拓扑排序+搜索)
传送门 按照题意模拟就行了. 先拓扑排序去掉不在环上面的点. 剩下的都是简单环了. 于是都dfsdfsdfs一遍求出最短的环就行. 代码: #include<bits/stdc++.h> ...
- C++中各种时间类型的转换(包括MFC中的时间类型)
平时写代码会经常遇到时间类型转换的问题,如时间戳转为格式化时间,或者反过来等,时间类型有的为time_t,还有FILETIME一堆,在这里记录下他们之间是如何转换的. 时间类型及其意义 FILETIM ...
- java正则表达式笔记
import java.util.regex.Matcher; import java.util.regex.Pattern; import java.util.regex.PatternSyntax ...
- 黑白二值图像周长测量--C#实现
假设是单像素线白色用1(对应RGB(255,0,0))表示,背景用0(对应RBG(0,0,0))表示. 考虑3种类型的边界 水平方向 0->1 1->0 类似垂直方向也是0-> ...
- dj 模型层orm-1
ORM简介 MVC或者MVC框架中包括一个重要的部分,就是ORM,它实现了数据模型与数据库的解耦,即数据模型的设计不需要依赖于特定的数据库,通过简单的配置就可以轻松更换数据库,这极大的减轻了开发人员的 ...
- ID、句柄、指针、对象互相转换
/*************************************************************************************************** ...
- Ng第十二课:支持向量机(Support Vector Machines)(三)
11 SMO优化算法(Sequential minimal optimization) SMO算法由Microsoft Research的John C. Platt在1998年提出,并成为最快的二次规 ...