Python之密度聚类
# -*- coding: utf-8 -*-
"""
Created on Tue Sep 25 10:48:34 2018 @author: zhen
""" import numpy as np
import matplotlib.pyplot as plt
import sklearn.datasets as ds
import matplotlib.colors
from sklearn.cluster import DBSCAN
from sklearn.preprocessing import StandardScaler def expand(a, b):
d = (b - a) * 0.1
return a-d, b+d if __name__ == "__main__":
N = 1000
centers = [[1, 2], [-1, -1], [1, -1], [-1, 1]]
data, y = ds.make_blobs(N, n_features=2, centers=centers, cluster_std=[0.5, 0.25, 0.7, 0.5], random_state=0)
# 归一化数据
data = StandardScaler().fit_transform(data)
# 数据的参数
params = ((0.2, 5), (0.2, 10), (0.2, 15), (0.3, 5), (0.3, 10), (0.3, 15)) # 设置中文样式
matplotlib.rcParams['font.sans-serif'] = [u'SimHei']
matplotlib.rcParams['axes.unicode_minus'] = False
# 设置颜色
cm = matplotlib.colors.ListedColormap(list('rgbm'))
plt.figure(figsize=(12, 8), facecolor='w')
plt.suptitle(u'DBSCAN聚类', fontsize=20) for i in range(6):
eps, min_samples = params[i]
# 创建密度聚类模型
model = DBSCAN(eps=eps, min_samples=min_samples)
# 训练模型
model.fit(data)
y_hat = model.labels_ core_indices = np.zeros_like(y_hat, dtype=bool)
core_indices[model.core_sample_indices_] = True y_unique = np.unique(y_hat)
n_clusters = y_unique.size - (1 if -1 in y_hat else 0)
# print(y_unique, '聚类簇的个数:', n_clusters) plt.subplot(2, 3, i+1)
clrs = plt.cm.Spectral(np.linspace(0, 0.8, y_unique.size))
# print(clrs) x1_min, x2_min = np.min(data, axis=0)
x1_max, x2_max = np.max(data, axis=0)
x1_min, x1_max = expand(x1_min, x1_max)
x2_min, x2_max = expand(x2_min, x2_max) for k, clr in zip(y_unique, clrs):
cur = (y_hat == k)
if k == -1:
plt.scatter(data[cur, 0], data[cur, 1], s=20, c='k')
# 设置散点图数据
plt.scatter(data[cur, 0], data[cur, 1], s=20, cmap=cm, edgecolors='k')
plt.scatter(data[cur & core_indices][:, 0], data[cur & core_indices][:, 1],
s=20, cmap=cm, marker='o', edgecolors='k')
# 设置x,y轴
plt.xlim((x1_min, x1_max))
plt.ylim((x2_min, x2_max))
plt.grid(True)
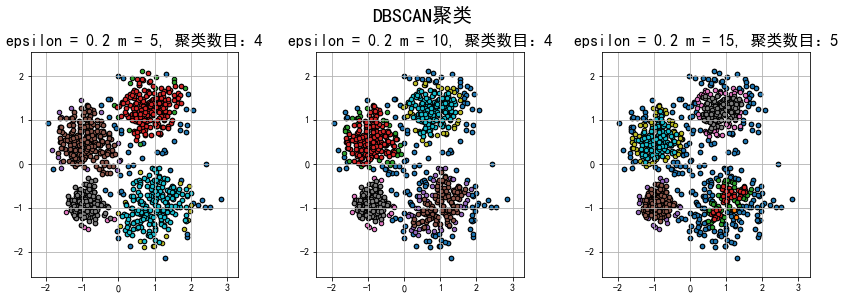
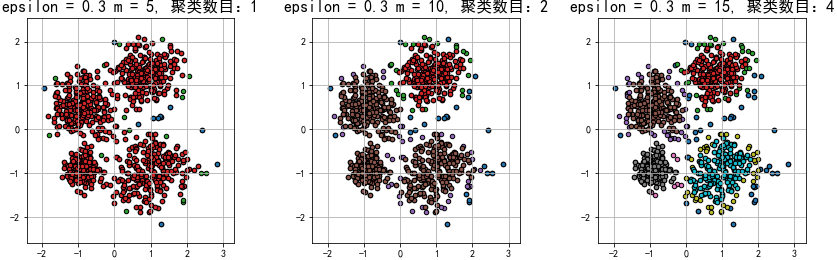
plt.title(u'epsilon = %.1f m = %d, 聚类数目:%d' % (eps, min_samples, n_clusters), fontsize=16)
plt.tight_layout()
plt.subplots_adjust(top=0.9)
plt.show()
结果:
总结:
1.在epsilon(半径)相同的情况下,m(数量)越大,划分的聚类数目就可能越多,异常的数据就会划分的越多。在m(数量)相同的情况下,epsilon(半径)越大,划分的聚类数目就可能越少,异常的数据就会划分的越少。因此,epsilon和m是相互牵制的,合适的epsilon和m有利于更好的聚类,减少欠拟合或过拟合的情况。
2.和KMeans聚类相比,DBSCAN密度聚类更擅长聚不规则形状的数据,因此在数据不是接近圆形的方式分布的情况下,建议使用密度聚类!
Python之密度聚类的更多相关文章
- 吴裕雄 python 机器学习——密度聚类DBSCAN模型
import numpy as np import matplotlib.pyplot as plt from sklearn import cluster from sklearn.metrics ...
- (数据科学学习手札15)DBSCAN密度聚类法原理简介&Python与R的实现
DBSCAN算法是一种很典型的密度聚类法,它与K-means等只能对凸样本集进行聚类的算法不同,它也可以处理非凸集. 关于DBSCAN算法的原理,笔者觉得下面这篇写的甚是清楚练达,推荐大家阅读: ht ...
- 基于密度聚类的DBSCAN和kmeans算法比较
根据各行业特性,人们提出了多种聚类算法,简单分为:基于层次.划分.密度.图论.网格和模型的几大类. 其中,基于密度的聚类算法以DBSCAN最具有代表性. 场景 一 假设有如下图的一组数据, 生成数据 ...
- DBSCAN密度聚类
1. 密度聚类概念 DBSCAN(Density-Based Spatial Clustering of Applications with Noise,具有噪声的基于密度的聚类方法)是一种很典型的密 ...
- Python机器学习——DBSCAN聚类
密度聚类(Density-based Clustering)假设聚类结构能够通过样本分布的紧密程度来确定.DBSCAN是常用的密度聚类算法,它通过一组邻域参数(ϵϵ,MinPtsMinPts)来描述样 ...
- 密度聚类 - DBSCAN算法
参考资料:python机器学习库sklearn——DBSCAN密度聚类, Python实现DBScan import numpy as np from sklearn.cluster impo ...
- DBSCAN密度聚类算法
DBSCAN(Density-Based Spatial Clustering of Applications with Noise,具有噪声的基于密度的聚类方法)是一种很典型的密度聚类算法,和K-M ...
- 机器学习(六)K-means聚类、密度聚类、层次聚类、谱聚类
本文主要简述聚类算法族.聚类算法与前面文章的算法不同,它们属于非监督学习. 1.K-means聚类 记k个簇中心,为\(\mu_{1}\),\(\mu_{2}\),...,\(\mu_{k}\),每个 ...
- 机器学习算法总结(五)——聚类算法(K-means,密度聚类,层次聚类)
本文介绍无监督学习算法,无监督学习是在样本的标签未知的情况下,根据样本的内在规律对样本进行分类,常见的无监督学习就是聚类算法. 在监督学习中我们常根据模型的误差来衡量模型的好坏,通过优化损失函数来改善 ...
随机推荐
- Sharding-jdbc(一)分库分表理解
1.什么是分库分表 所谓的分库分表就是数据的分片(Sharding). 2.为什么需要分库分表 因为随着公司的业务越来越大,对于现成单机单个应用瓶颈问题,对数据持久化硬盘如何进行扩容. 可以从4个方面 ...
- MySql中插入乱码问题解决
今天在使用Java写入数据库时候,发现Insert语句和Update语句在执行过后,数据库中中文显示的是“??”,经过一番查阅,其中关键的问题在于编码格式是否统一. 其中创建表时候,每个关键字的格式都 ...
- kafka 日志结构
1.kafka日志结构 直接举例子: 例如kafka有个名字叫 haha 的topic,那么kafka日志下面有kafka-0,kafka-1,kafka-2...,kafka-n,具体多少个,创建分 ...
- [Golang] 第三方包应该如何安装--在线和离线
一 在线安装 采用go get的方式安装import 的时候找不到对应的包看看pkg里面有没有 二 离线安装 redis客户端采用git clone的方法安装的话可以用以下方法 cd src git ...
- SHA-1退休:数千万用户通向加密网站之路被阻
Facebook和Cloudflare警告道:上千万用户将无法访问只使用SHA-2签名证书的HTTPS网站.2016年-2017年是SHA-1算法的缓冲期.2017年开始CA机构将不能颁发含有sh ...
- Vue源码之 virtual-dom 实现简析
发现两篇写得特别好的博文,仔细通读,发现豁然开朗. 浅析Vue 中的patch和diff Vue 2.0 的 virtual-dom 实现简析
- Git学习笔记4
现在,远程库已经准备好了,下一步是用命令git clone克隆一个本地库: $ git clone git@github.com:michaelliao/gitskills.git 要克隆一个仓库,首 ...
- Spring基础(2):bean顺序创建
public class Person{ public Person(){ System.out.println("Person person person ..."); } } ...
- 本地SQL数据库执行作业定时修改其他数据库内容
--exec sp_addlinkedserver 'xkp', ' ', 'SQLOLEDB', '192.168.66.66' 定义链接--exec sp_addlinkedsrvlogin ' ...
- input点击链接另一个页面,各种操作。
1.链接到某页<input type="button" name="Submit" value="确 定" class="b ...