自研、好用的ORM 读写分离功能使用
Fast Framework
作者 Mr-zhong
代码改变世界....
一、前言
Fast Framework 基于NET6.0 封装的轻量级 ORM 框架 支持多种数据库 SqlServer Oracle MySql PostgreSql Sqlite
优点: 体积小、原生支持微软特性、流畅API、使用简单、性能高、模型数据绑定采用 Expression、强大的表达式解析、支持多种子查询可实现较为复杂查询、源代码可读性强、支持AOT 编译。
缺点:目前仅支持Db Frist
开源地址:https://github.com/China-Mr-zhong/Fast.Framework (唯一)
ps:权重随机算法、支持故障转移、故障回调(可做日志记录或通知)
一、appsettings.json 配置
{
"DbOptions": [
{
"DbId": "db_01",
"DbType": "MySQL",
"IsDefault": true,
"ConnectionStrings": "server=localhost;database=Test;user=root;pwd=123456789;port=3306;min pool size=0;max pool size=100;connect timeout=120;AllowLoadLocalInfile=true;",
"UseMasterSlaveSeparation": true, //使用主从分离 注意所有事务将强制走主库
"SlaveItems": [
{
"DbId": "A",
"Weight": 60,
"ConnectionStrings": "server=localhost;database=Test1;user=root;pwd=123456789;port=3306;min pool size=0;max pool size=100;connect timeout=120;AllowLoadLocalInfile=true;",
"Description": "A数据库"
},
{
"DbId": "B",
"Weight": 40,
"ConnectionStrings": "server=localhost;database=Test2;user=root;pwd=123456789;port=3306;min pool size=0;max pool size=100;connect timeout=120;AllowLoadLocalInfile=true;",
"Description": "B数据库"
}
],
"Description": "主库连接配置"
}
]
}
二、 Program (入口配置)
builder.Services.Configure<List<DbOptions>>(builder.Configuration.GetSection("DbOptions"));//注册Options接口
builder.Services.AddFastDbContext();//添加上下文
四、使用示例
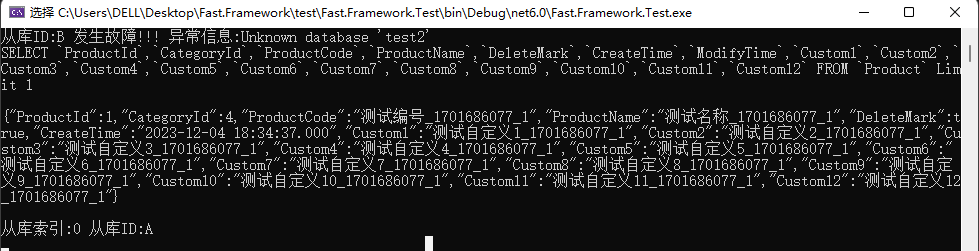
db.Aop.SlaveDbFault = (options, ex) =>
{
//故障回调
Console.WriteLine($"从库ID:{options.DbId} 发生故障!!! 异常信息:{ex.Message}");
};
var data = db.Query<Product>().First();
Console.WriteLine(Json.Serialize(data));
Console.WriteLine();
Console.WriteLine($"从库索引:{db.Ado.CurrentSlaveDbIndex} 从库ID:{db.Ado.SlaveDbOptions.DbId}");
其它很棒的功能(原创基于作用域概念设计的子查询)
Join子查询
示例代码
var subQuery1 = db.Query<Product>().Select(s => new
{
s.ProductId,
s.CategoryId,
s.ProductCode,
s.ProductName,
s.DeleteMark
});
var data = db.Query<Category>().InnerJoin(subQuery1, (a, b) => a.CategoryId == b.CategoryId).ToList();
执行后Sql
SELECT p1.`CategoryId`,p1.`CategoryName`,p2.`ProductId`,p2.`ProductCode`,p2.`ProductName`,p2.`DeleteMark` FROM `Category` `p1`
INNER JOIN ( SELECT `ProductId` AS `ProductId`,`CategoryId` AS `CategoryId`,`ProductCode` AS `ProductCode`,`ProductName` AS `ProductName`,`DeleteMark` AS `DeleteMark` FROM `Product` ) `p2` ON ( `p1`.`CategoryId` = `p2`.`CategoryId` )
From子查询
示例代码
var subQuery2 = db.Query<Product>().Select(s=>new
{
s.ProductId,
s.CategoryId,
s.ProductCode,
s.ProductName,
s.DeleteMark
});
var data = db.Query(subQuery2).ToList();
执行后Sql
SELECT * FROM ( SELECT `ProductId` AS `ProductId`,`CategoryId` AS `CategoryId`,`ProductCode` AS `ProductCode`,`ProductName` AS `ProductName`,`DeleteMark` AS `DeleteMark` FROM `Product` ) x
Select子查询
示例代码
var data = db.Query<Product>().Select(s => new
{
CategoryName = db.Query<Category>().Where(w => w.CategoryId == 1).Select(s => s.CategoryName).First()
}).First();
执行后Sql
SELECT ( SELECT `p2`.`CategoryName` FROM `Category` `p2`
WHERE ( `p2`.`CategoryId` = 1 ) Limit 1 ) AS `CategoryName` FROM `Product` `p1` Limit 1
Select嵌套查询
示例代码
var data1 = db.Query<Product>().Select(s => new
{
NestedQuery = db.Query<Category>().Where(w => w.CategoryId == s.CategoryId).ToList()
}).First(); var data2 = db.Query<Product>().Where(w => w.ProductId == 1).Select(s => new
{
NestedQuery = db.Query<Category>().Where(w => w.CategoryId == s.CategoryId).ToList()
}).First();
执行后Sql
//内部机制主查询有结果才执行嵌套查询,懒加载实现 SELECT 0 AS `fast_args_index_0` FROM `Product` `p1` Limit 1 -------------------------------------------------------------------------- SELECT p2.`CategoryId`,p2.`CategoryName`,p1.`ProductId`,p1.`ProductCode`,p1.`ProductName`,p1.`DeleteMark`,p1.`CreateTime`,p1.`ModifyTime`,p1.`Custom1`,p1.`Custom2`,p1.`Custom3`,p1.`Custom4`,p1.`Custom5`,p1.`Custom6`,p1.`Custom7`,p1.`Custom8`,p1.`Custom9`,p1.`Custom10`,p1.`Custom11`,p1.`Custom12` FROM `Category` `p2`
RIGHT JOIN `Product` `p1` ON ( `p2`.`CategoryId` = `p1`.`CategoryId` ) SELECT 0 AS `fast_args_index_0` FROM `Product` `p1`
WHERE ( `p1`.`ProductId` = 1 ) Limit 1
Where子查询
示例代码
var data = db.Query<Category>().Where(w => w.CategoryId == 1 && db.Query<Product>().Where(w => w.CategoryId == 1).Select(s => 1).Any()).First();//Any支持取反
执行后Sql
SELECT p1.`CategoryId`,p1.`CategoryName` FROM `Category` `p1`
WHERE ( ( `p1`.`CategoryId` = 1 ) AND EXISTS ( SELECT 1 FROM `Product` `p2`
WHERE ( `p2`.`CategoryId` = 1 ) ) ) Limit 1
更多示例 https://www.cnblogs.com/China-Mr-zhong/p/17852177.html
自研、好用的ORM 读写分离功能使用的更多相关文章
- DBPack 读写分离功能发布公告
在 v0.1.0 版本我们发布了分布式事务功能,并提供了读写分离功能预览.在 v0.2.0 这个版本,我们加入了通过 UseDB hint 自定义查询请求路由的功能,并修复了一些 bug.另外,在这个 ...
- CYQ.Data V5 数据库读写分离功能介绍
前言 好多年没写关于此框架的新功能的介绍了,这些年一直在默默地更新,从Nuget上的记录就可以看出来: 这几天在看Java的一些东西,除了觉的Java和.NET的相似度实在太高之外,就是Java太原始 ...
- SpringBoot 玩转读写分离
环境概览 前言介绍 Sharding-JDBC是当当网的一个开源项目,只需引入jar即可轻松实现读写分离与分库分表.与MyCat不同的是,Sharding-JDBC致力于提供轻量级的服务框架,无需额外 ...
- TDSQL MySQL版基本原理-水平分表 读写分离 弹性扩展 强同步
TDSQL MySQL版(TDSQL for MySQL)是部署在腾讯云上的一种支持自动水平拆分.Shared Nothing 架构的分布式数据库.TDSQL MySQL版 即业务获取的是完整的逻辑库 ...
- MySQL+Amoeba实现数据库主从复制和读写分离
MySQL读写分离是在主从复制的基础上进一步通过在master上执行写操作,在slave上执行读操作来实现的.通过主从复制,master上的数据改动能够同步到slave上,从而保持了数据的一致性.实现 ...
- Nginx 反向代理、负载均衡、页面缓存、URL重写及读写分离详解
转载:http://freeloda.blog.51cto.com/2033581/1288553 大纲 一.前言 二.环境准备 三.安装与配置Nginx 四.Nginx之反向代理 五.Nginx之负 ...
- MyCAT实现MySQL的读写分离
在MySQL中间件出现之前,对于MySQL主从集群,如果要实现其读写分离,一般是在程序端实现,这样就带来一个问题,即数据库和程序的耦合度太高,如果我数据库的地址发生改变了,那么我程序端也要进行相应的修 ...
- Amoeba+Mysql实现数据库读写分离
一.Amoeba 是什么 Amoeba(变形虫)项目,专注 分布式数据库 proxy 开发.座落与Client.DB Server(s)之间.对客户端透明.具有负载均衡.高可用性.sql过滤.读写分离 ...
- Nginx反向代理、负载均衡、页面缓存、URL重写及读写分离详解
大纲 一.前言 二.环境准备 三.安装与配置Nginx 四.Nginx之反向代理 五.Nginx之负载均衡 六.Nginx之页面缓存 七.Nginx之URL重写 八.Nginx之读写分离 注,操作系统 ...
- Nginx 反向代理、负载均衡、页面缓存、URL重写、读写分离及简单双机热备详解
大纲 一.前言 二.环境准备 三.安装与配置Nginx (windows下nginx安装.配置与使用) 四.Nginx之反向代理 五.Nginx之负载均衡 (负载均衡算法:nginx负载算法 up ...
随机推荐
- 从壹开始前后端开发【.Net6+Vue3】
项目名称:KeepGoing(继续前进) 1.1介绍 工作后,学习的脚步一直停停走走,希望可以以此项目为基础,可以不断的迫使自己不断的学习以及成长 将以Girvs框架为基础,从壹开始二次开发一个前后端 ...
- 接到一个新需求应该怎么做?(V1.0)
接到一个新需求应该怎么做?(V1.0) 1 背景 在做业务研发的时候,经常会接到一些 产品需求/技术需求, 无论需求大小,都需要一套可以重复使用的方法论,来保证整个项目的正常交付,这篇思考就是总结梳理 ...
- Ubuntu虚拟机安装以及在Ubuntu上安装pycharm
一.在VMware上安装Ubuntu操作系统 1.下载Ubuntu镜像文件 下载地址:清华大学开源软件镜像站 | Tsinghua Open Source Mirror 参考文章:Ubuntu系统下载 ...
- LR性能分析
如何模拟真实用户的行为 真实用户的操作是否可预期,比如考试 用户一般会先打开考试页面,然后答题 那么会有多种题型,用户是不是有可能答不同的题型 性能的拐点
- 【matplotlib基础】--3D图形
matplotlib 在1.0版本之前其实是不支持3D图形绘制的. 后来的版本中,matplotlib加入了3D图形的支持,不仅仅是为了使数据的展示更加生动和有趣.更重要的是,由于多了一个维度,扩展了 ...
- Biwen.QuickApi代码生成器功能上线
[QuickApi("hello/world")] public class MyApi : BaseQuickApi<Req,Rsp>{} 使用方式 : dotnet ...
- 04-Shell字符串变量
1. 字符串变量的三种方式 字符串(String)就是一系列字符的组合.字符串是 Shell 编程中最常用的数据类型之一(除了数字和字符串,也没有其他类型了) 单引号方式 双引号方式, 推荐 不用引号 ...
- java实现朴素rpc
五层协议中,RPC在第几层? 五层协议 应用层 传输层 网络层 链路层 物理层 我不知道,我要去大气层! 远程过程调用(RPC),比较朴素的说法就是,从某台机器调用另一台机器的一段代码,并获取返回结果 ...
- Vue之for循环
Vue中for循环的用法总结如下: 1.基本用法 v-for <!DOCTYPE html> <html lang="en"> <head> & ...
- NOI 2023 游记
Day0=2023.7.23. Day -?? 订了 30 个徽章.很快认识到可能不够,又自己买了 30 个. Day -? UNR,完全没有精神状态于是两天都考半场睡半场.0+10+55,成功 Fe ...