KL散度和交叉熵的对比介绍
KL散度(Kullback-Leibler Divergence)和交叉熵(Cross Entropy)是在机器学习中广泛使用的概念。这两者都用于比较两个概率分布之间的相似性,但在一些方面,它们也有所不同。本文将对KL散度和交叉熵的详细解释和比较。
KL散度和交叉熵
KL散度,也称为相对熵(Relative Entropy),是用来衡量两个概率分布之间的差异的一种度量方式。它衡量的是当用一个分布Q来拟合真实分布P时所需要的额外信息的平均量。KL散度的公式如下
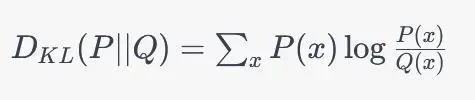
x是概率分布中的一个可能的事件或状态。P(x)和Q(x)分别表示真实概率分布和模型预测的概率分布中事件x的概率。
KL散度具有以下性质:
KL散度是非负的,即 KLD(P||Q) >= 0,当且仅当P和Q是完全相同的分布时等号成立。
KL散度不满足交换律,即 KLD(P||Q) != KLD(Q||P)。
KL散度通常不是对称的,即 KLD(P||Q) != KLD(Q||P)。
KL散度不是度量,因为它不具有对称性和三角不等式。
在机器学习中,KL散度通常用于比较两个概率分布之间的差异,例如在无监督学习中用于评估生成模型的性能。
交叉熵是另一种比较两个概率分布之间的相似性的方法。它的公式如下:
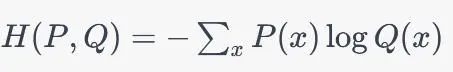
x是概率分布中的一个可能的事件或状态。P(x)和Q(x)分别表示真实概率分布和模型预测的概率分布中事件x的概率。交叉熵衡量了模型预测的概率分布与真实概率分布之间的差异,即模型在预测上的不确定性与真实情况的不确定性之间的差距。
与KL散度不同,交叉熵具有以下性质:
交叉熵是非负的,即CE(P, Q) >= 0,当且仅当P和Q是完全相同的分布时等号成立。
交叉熵满足交换律,即CE(P, Q) = CE(Q, P)。
交叉熵是对称的,即CE(P, Q) = CE(Q, P)。
交叉熵不是度量,因为它不具有三角不等式。
在机器学习中,交叉熵通常用于衡量模型预测和真实标签之间的差异。例如,在分类任务中,交叉熵被用作损失函数,以衡量模型预测的类别分布和真实标签之间的差。
KL散度与交叉熵的关系
L散度和交叉熵有一定的联系。在概率论中,KL散度可以被定义为两个概率分布之间的交叉熵与真实分布的熵的差值。具体地说,KL散度的公式如下
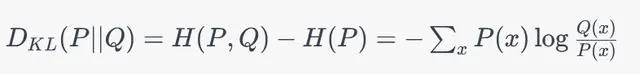
H(P, Q)表示P和Q的交叉熵,H(P)表示P的熵。可以看到,KL散度包含了交叉熵和熵的概念,因此它们之间有着密切的联系。
KL散度与交叉熵的应用
交叉熵通常用于监督学习任务中,如分类和回归等。在这些任务中,我们有一组输入样本和相应的标签。我们希望训练一个模型,使得模型能够将输入样本映射到正确的标签上。
在这种情况下,我们可以使用交叉熵作为损失函数。假设我们有一个模型预测的输出分布为p,真实标签的分布为q。那么交叉熵的公式如下
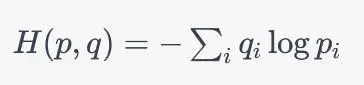
i表示可能的类别或事件,p_i和q_i分别表示真实概率分布和模型预测的概率分布中类别i的概率。
KL散度通常用于无监督学习任务中,如聚类、降维和生成模型等。在这些任务中,我们没有相应的标签信息,因此无法使用交叉熵来评估模型的性能,所以需要一种方法来衡量模型预测的分布和真实分布之间的差异,这时就可以使用KL散度来衡量模型预测的分布和真实分布之间的差异。KL散度的公式如下:
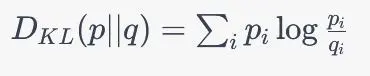
i表示概率分布中的一个可能的事件或状态。p_i和q_i分别表示真实概率分布和模型预测的概率分布中事件i的概率。KL散度衡量了模型预测的概率分布与真实概率分布之间的差异,即模型在预测上的不确定性与真实情况的不确定性之间的差距。
一般情况下:交叉熵通常用于监督学习任务中,KL散度通常用于无监督学习任务中。当我们有相应的标签信息时,应该使用交叉熵来评估模型的性能;当我们没有相应的标签信息时,使用KL散度可以衡量模型预测的分布和真实分布之间的差异。
总结
在本文中,我们介绍了KL散度和交叉熵这两个概念,并比较了它们之间的异同。KL散度用于比较两个概率分布之间的差异,而交叉熵用于衡量模型预测和真实标签之间的差异。尽管它们有一定的联系,但它们在使用和应用上还是有所区别。在机器学习中,KL散度和交叉熵都有着广泛的应用,可以用来评估模型的性能和更新模型参数。
KL散度和交叉熵的对比介绍的更多相关文章
- 损失函数--KL散度与交叉熵
损失函数 在逻辑回归建立过程中,我们需要一个关于模型参数的可导函数,并且它能够以某种方式衡量模型的效果.这种函数称为损失函数(loss function). 损失函数越小,则模型的预测效果越优.所以我 ...
- 【机器学习基础】熵、KL散度、交叉熵
熵(entropy).KL 散度(Kullback-Leibler (KL) divergence)和交叉熵(cross-entropy)在机器学习的很多地方会用到.比如在决策树模型使用信息增益来选择 ...
- KL散度=交叉熵-熵
熵:可以表示一个事件A的自信息量,也就是A包含多少信息. KL散度:可以用来表示从事件A的角度来看,事件B有多大不同. 交叉熵:可以用来表示从事件A的角度来看,如何描述事件B. 一种信息论的解释是: ...
- 信息论相关概念:熵 交叉熵 KL散度 JS散度
目录 机器学习基础--信息论相关概念总结以及理解 1. 信息量(熵) 2. KL散度 3. 交叉熵 4. JS散度 机器学习基础--信息论相关概念总结以及理解 摘要: 熵(entropy).KL 散度 ...
- 从香农熵到手推KL散度
信息论与信息熵是 AI 或机器学习中非常重要的概念,我们经常需要使用它的关键思想来描述概率分布或者量化概率分布之间的相似性.在本文中,我们从最基本的自信息和信息熵到交叉熵讨论了信息论的基础,再由最大似 ...
- 最大似然估计 (Maximum Likelihood Estimation), 交叉熵 (Cross Entropy) 与深度神经网络
最近在看深度学习的"花书" (也就是Ian Goodfellow那本了),第五章机器学习基础部分的解释很精华,对比PRML少了很多复杂的推理,比较适合闲暇的时候翻开看看.今天准备写 ...
- 【深度学习】K-L 散度,JS散度,Wasserstein距离
度量两个分布之间的差异 (一)K-L 散度 K-L 散度在信息系统中称为相对熵,可以用来量化两种概率分布 P 和 Q 之间的差异,它是非对称性的度量.在概率学和统计学上,我们经常会使用一种更简单的.近 ...
- BP神经网络——交叉熵作代价函数
Sigmoid函数 当神经元的输出接近 1时,曲线变得相当平,即σ′(z)的值会很小,进而也就使∂C/∂w和∂C/∂b会非常小.造成学习缓慢,下面有一个二次代价函数的cost变化图,epoch从15到 ...
- 机器学习:Kullback-Leibler Divergence (KL 散度)
今天,我们介绍机器学习里非常常用的一个概念,KL 散度,这是一个用来衡量两个概率分布的相似性的一个度量指标.我们知道,现实世界里的任何观察都可以看成表示成信息和数据,一般来说,我们无法获取数据的总体, ...
- 熵(Entropy),交叉熵(Cross-Entropy),KL-松散度(KL Divergence)
1.介绍: 当我们开发一个分类模型的时候,我们的目标是把输入映射到预测的概率上,当我们训练模型的时候就不停地调整参数使得我们预测出来的概率和真是的概率更加接近. 这篇文章我们关注在我们的模型假设这些类 ...
随机推荐
- 【Azure 应用服务】记一次Azure Spring Cloud 的部署错误 (az spring-cloud app deploy -g dev -s testdemo -n demo -p ./hellospring-0.0.1-SNAPSHOT.jar --->>> Failed to wait for deployment instances to be ready)
问题描述 使用Azure Spring Cloud服务,在部署时候失败,收到错误消息为: c:\project\hellospring>az spring-cloud app deploy -g ...
- C++ //常用算术生成算法 //#include<numeric> accumulate //fill //向容器中填充指定的元素
1 //常用算术生成算法 //#include<numeric> accumulate 2 //fill //向容器中填充指定的元素 3 #include<iostream> ...
- 本地部署FastGPT使用在线大语言模型
FastGPT 是一个基于 LLM 大语言模型的知识库问答系统,提供开箱即用的数据处理.模型调用等能力,它背后依赖OneApi开源项目来访问各种大语言模型提供的能力.各大语言模型提供的访问接口规范不尽 ...
- 统一身份认证系统 OpenLDAP 完整部署
0)LDAP 介绍 LDAP 是什么?在那些地方用会用到 LDAP? LDAP英文名称:Lightweight Directory Access Protocol 轻型目录访问协议. 常用在单点登录, ...
- 制作B站直播简介
本文只用于个人总结备份,如果对你有帮助就更好了. 准备工作 准备好简介要用的的背景图.头像图,上传到图床生成图片链接. 简介的内容可分为主播简介.直播时间.直播内容.联系方式,内容根据实际需要修改,需 ...
- 日常办公——Word中重复标题的设置
在Word中,遇到表格分页时,可以设置重复标题,如下图所示:
- 在后台运行 django的基本方法
在后台运行 django: nohup python manage.py runserver 0.0.0.0:9000 &ps:&可以不写,这样启动测试服务器后,就可以常驻后台运行了. ...
- 新服务器搭建docker跑mysql+java项目
参考:https://js.work/posts/1362ba443b35d(yum安装java17) 踩了两个坑,一个前面的conf文件里监听80的配置没有删除掉,一个项目配置里面的路径还在用服务器 ...
- Deeplink实践原理分析
目录介绍 01.先看一个场景 02.什么是DeepLink 03.什么是Deferred DeepLink 04.什么是AppLink 05.DeepLink和AppLink核心技术 06.DeepL ...
- 「AntV」Vue3与TS框架下使用L7
1. 引言 Vue是常用的前端框架,TypeScript(简称TS) 是 JavaScript 的超集,可以提高代码的可维护性和可读性 本文基于Vite.Vue3和TypeScript搭建L7开发环境 ...