论文解读(TAMEPT)《A Two-Stage Framework with Self-Supervised Distillation For Cross-Domain Text Classification》
论文信息
论文标题:A Two-Stage Framework with Self-Supervised Distillation For Cross-Domain Text Classification
论文作者:Yunlong Feng, Bohan Li, Libo Qin, Xiao Xu, Wanxiang Che
论文来源:2023 aRxiv
论文地址:download
论文代码:download
视屏讲解:click
1 介绍
动机:以前的工作主要集中于提取 域不变特征 或 任务不可知特征,而忽略了存在于目标域中可能对下游任务有用的域感知特征;
贡献:
- 提出一个两阶段的学习框架,使现有的分类模型能够有效地适应目标领域;
- 引入自监督蒸馏,可以帮助模型更好地从目标领域的未标记数据中捕获域感知特征;
- 在 Amazon 跨域分类基准上的实验表明,取得了 SOTA ;
2 相关
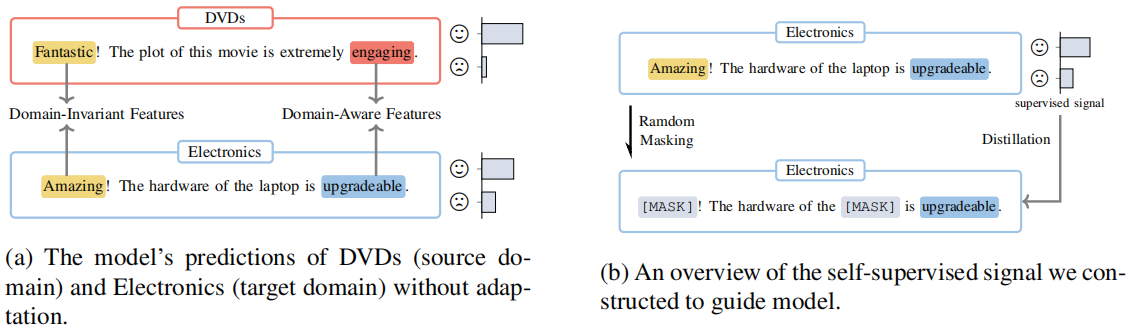
Figure 1(a):阐述域不变特征和域感知特征与任务的关系;
Figure 1(b):阐述遮蔽域不变特征和域感知特征与预测的关系:
- 通过掩盖域不变特征,模型建立预测和域感知特征的相关性;
- 通过掩盖域感知特征,模型加强了预测和域不变特征的关系;
一个文本提示组成如下:
$\boldsymbol{x}_{\mathrm{p}}=\text { "[CLS] } \boldsymbol{x} \text {. It is [MASK]. [SEP]"} \quad\quad(1)$
$\text{PLM}$ 将 $\boldsymbol{x}_{\mathrm{p}}$ 作为输入,并利用上下文信息用词汇表中的一个单词填充 $\text{[MASK]}$ 作为输出,输出单词随后被映射到一个标签 $\mathcal{Y}$。
PT 的目标:
$\mathcal{L}_{p m t}\left(\mathcal{D}^{\mathcal{T}} ; \theta_{\mathcal{M}}\right)=-\sum_{\boldsymbol{x}, y \in \mathcal{D}} y \log p_{\theta_{\mathcal{M}}}\left(\hat{y} \mid \boldsymbol{x}_{\mathrm{p}}\right)$
使用 $\text{MLM }$ 来避免快捷学习($\text{shortcut learning}$),并适应目标域分布。具体来说,构造了一个掩蔽文本提示符 $\boldsymbol{x}_{\mathrm{pm}}$:
$\boldsymbol{x}_{\mathrm{pm}}=\text { "[CLS] } \boldsymbol{x}_{\mathrm{m}} \text {. It is [MASK]. [SEP]"}$
其中,$m\left(y_{\mathrm{m}}\right)$ 和 $\operatorname{len}_{m\left(\boldsymbol{x}_{\mathrm{m}}\right)}$ 分别表示 $x_{\mathrm{m}}$ 中的掩码词和计数;
SSKD
核心:使模型能够在预测和目标域的域感知特征之间建立联系;
具体:模型迫使 $x_{\mathrm{p}}$ 的预测和 $\boldsymbol{x}_{\mathrm{pm}}$ 的未掩蔽词之间联系起来,本文在 $p_{\theta}\left(y \mid \boldsymbol{x}_{\mathrm{pm}}\right)$ 和 $p_{\theta}\left(y \mid \boldsymbol{x}_{\mathrm{p}}\right)$ 的预测之间进行 $\text{KD}$:
$\mathcal{L}_{s s d}\left(\mathcal{D} ; \theta_{\mathcal{M}}\right)=\sum_{\boldsymbol{x} \in \mathcal{D}} K L\left(p_{\theta_{\mathcal{M}}}\left(y \mid \boldsymbol{x}_{\mathrm{pm}}\right)|| p_{\theta_{\mathcal{M}}}\left(y \mid \boldsymbol{x}_{\mathrm{p}}\right)\right)$
注意:$\boldsymbol{x}_{\mathrm{pm}}$ 可能包含域不变、域感知特征,或两者都包含;
2 方法
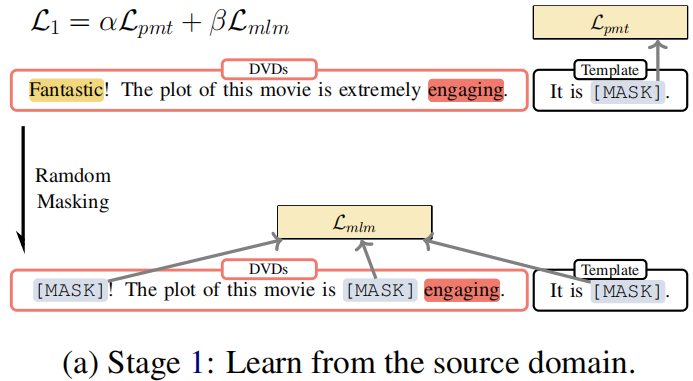
Procedure:
- Firstly, we calculate the classification loss of those sentences and update the parameters with the loss, as shown in line 5 of Algorithm 1.
- Then we mask the same sentence and calculate mask language modeling loss to update the parameters, as depicted in line 8 of Algorithm 1. The parameters of the model will be updated together by these two losses.
Objective:
$\begin{array}{l}\mathcal{L}_{1}^{\prime}\left(\mathcal{D}^{\mathcal{T}} ; \theta_{\mathcal{M}}\right)=\alpha \mathcal{L}_{p m t}\left(\mathcal{D}^{\mathcal{T}} ; \theta_{\mathcal{M}}\right) \\\mathcal{L}_{1}^{\prime \prime}\left(\mathcal{D}^{\mathcal{T}} ; \theta_{\mathcal{M}}\right)=\beta \mathcal{L}_{m l m}\left(\mathcal{D} ; \theta_{\mathcal{M}}\right)\end{array}$
Stage 2: Adapt to the target domain
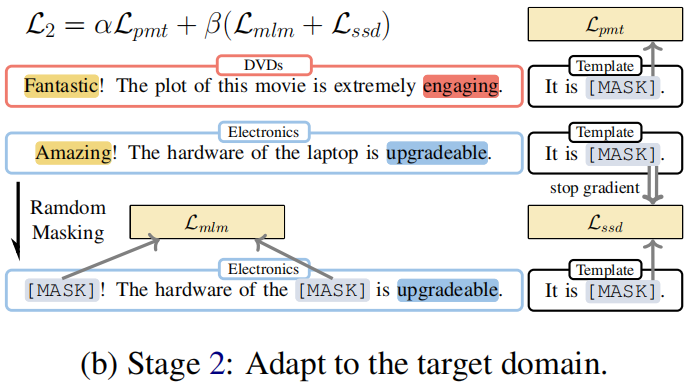
Procedure:
- Firstly, we sample labeled data from the source domain $\mathcal{D}_{S}^{\mathcal{T}} $ and calculate sentiment classification loss. The model parameters are updated using this loss in line 5 of Algorithm 2.
- Next, we sample unlabeled data from the target domain $\mathcal{D}_{T} $ and mask the unlabeled data to do a masking language model and selfsupervised distillation with the previous prediction.
Objective:
$\begin{aligned}\mathcal{L}_{2}^{\prime}\left(\mathcal{D}_{S}^{\mathcal{T}}, \mathcal{D}_{T} ; \theta_{\mathcal{M}}\right) & =\alpha \mathcal{L}_{p m t}\left(\mathcal{D}_{S}^{\mathcal{T}} ; \theta_{\mathcal{M}}\right) \\\mathcal{L}_{2}^{\prime \prime}\left(\mathcal{D}_{S}^{\mathcal{T}}, \mathcal{D}_{T} ; \theta_{\mathcal{M}}\right) & =\beta\left(\mathcal{L}_{m l m}\left(\mathcal{D}_{T} ; \theta_{\mathcal{M}}\right)\right. \left.+\mathcal{L}_{s s d}\left(\mathcal{D}_{T} ; \theta_{\mathcal{M}}\right)\right)\end{aligned}$
Algorithm

3 实验
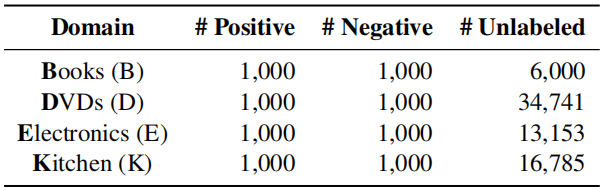
Dataset
Amazon reviews dataset
- $\text{R-PERL }$(2020): Use BERT for cross-domain text classification with pivot-based fine-tuning.
- $\text{DAAT}$ (2020): Use BERT post training for cross-domain text classification with adversarial training.
- $\text{p+CFd}$ (2020): Use XLM-R for cross-domain text classification with class-aware feature self-distillation (CFd).
- $\text{SENTIX}_{\text{Fix}}$ (2020): Pre-train a sentiment-aware language model by several pretraining tasks.
- $\text{UDALM}$ (2021): Fine-tuning with a mixed classification and MLM loss on domain-adapted PLMs.
- $\text{AdSPT}$ (2022): Soft Prompt tuning with an adversarial training object on vanilla PLMs.
- During Stage 1, we train 10 epochs with batch size 4 and early stopping (patience =3 ) on the accuracy metric. The optimizer is AdamW with learning rate 1 $\times 10^{-5}$ . And we halve the learning rate every 3 epochs. We set $\alpha=1.0$, $\beta=0.6$ for Eq.6 .
- During Stage 2, we train 10 epochs with batch size 4 and early stopping (patience =3 ) on the mixing loss of classification loss and mask language modeling loss. The optimizer is AdamW with a learning rate $1 \times 10^{-6}$ without learning rate decay. And we set $\alpha=0.5$, $\beta=0.5$ for Eq. 7 .
- In addition, for the mask language modeling objective and the self-supervised distillation objective, we randomly replace 30% of tokens to [MASK] and the maximum sequence length is set to 512 by truncation of inputs. Especially we randomly select the equal num unlabeled data from the target domain every epoch during Stage 2.
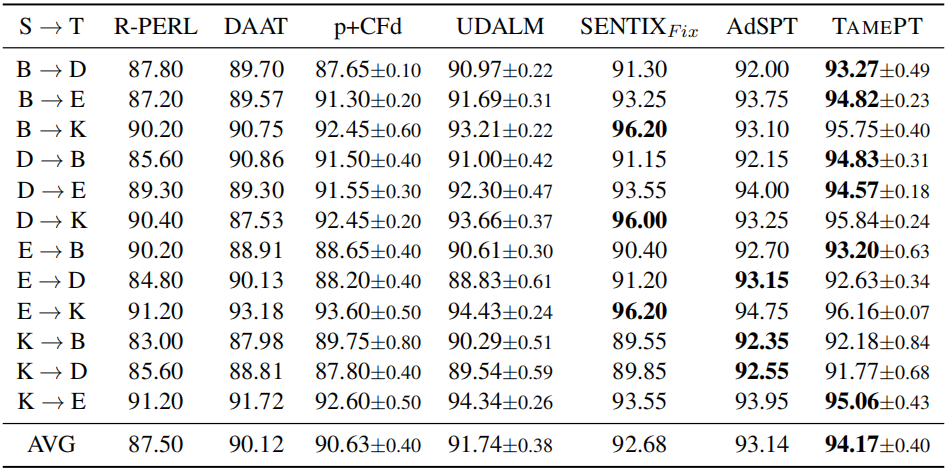
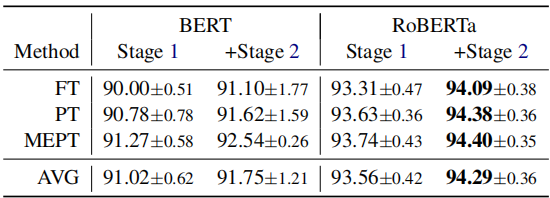
Single-source domain adaptation on Amazon reviews
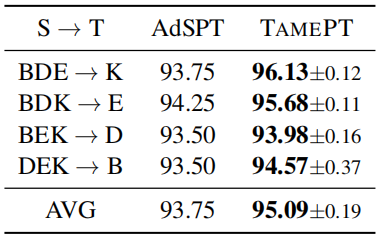
Multi-source domain adaptation on Amazon reviews
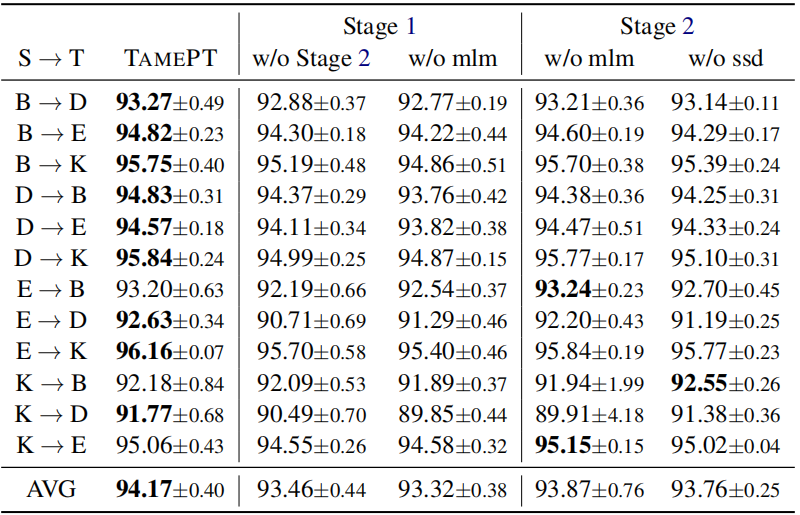
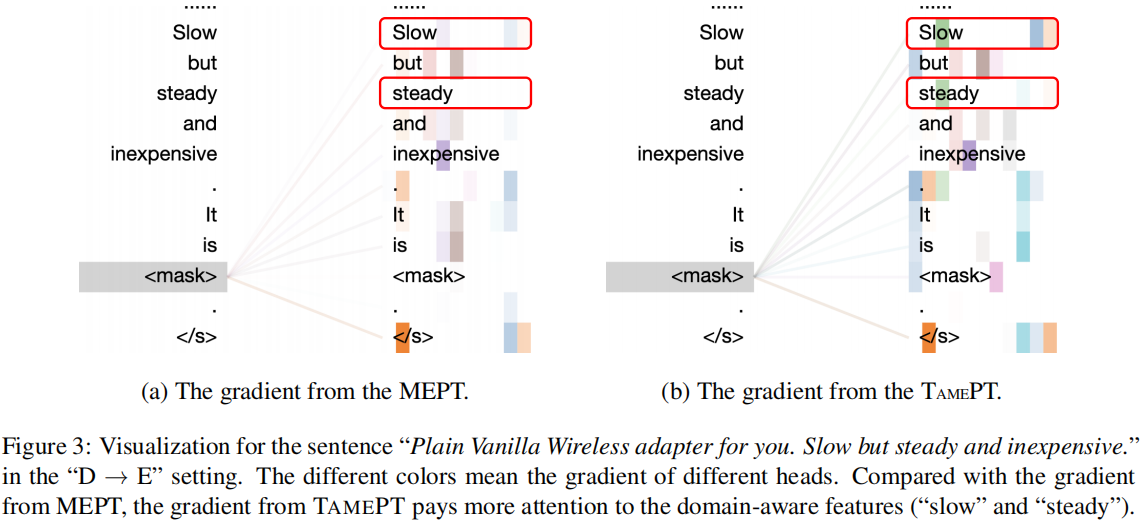

论文解读(TAMEPT)《A Two-Stage Framework with Self-Supervised Distillation For Cross-Domain Text Classification》的更多相关文章
- 论文解读(SimGRACE)《SimGRACE: A Simple Framework for Graph Contrastive Learning without Data Augmentation》
论文信息 论文标题:SimGRACE: A Simple Framework for Graph Contrastive Learning without Data Augmentation论文作者: ...
- AAAI2019 | 基于区域分解集成的目标检测 论文解读
Object Detection based on Region Decomposition and Assembly AAAI2019 | 基于区域分解集成的目标检测 论文解读 作者 | 文永亮 学 ...
- 自监督学习(Self-Supervised Learning)多篇论文解读(下)
自监督学习(Self-Supervised Learning)多篇论文解读(下) 之前的研究思路主要是设计各种各样的pretext任务,比如patch相对位置预测.旋转预测.灰度图片上色.视频帧排序等 ...
- 论文解读(SDNE)《Structural Deep Network Embedding》
论文题目:<Structural Deep Network Embedding>发表时间: KDD 2016 论文作者: Aditya Grover;Aditya Grover; Ju ...
- 论文解读(IDEC)《Improved Deep Embedded Clustering with Local Structure Preservation》
Paper Information Title:<Improved Deep Embedded Clustering with Local Structure Preservation>A ...
- 论文解读(KP-GNN)《How Powerful are K-hop Message Passing Graph Neural Networks》
论文信息 论文标题:How Powerful are K-hop Message Passing Graph Neural Networks论文作者:Jiarui Feng, Yixin Chen, ...
- 论文解读(SR-GNN)《Shift-Robust GNNs: Overcoming the Limitations of Localized Graph Training Data》
论文信息 论文标题:Shift-Robust GNNs: Overcoming the Limitations of Localized Graph Training Data论文作者:Qi Zhu, ...
- itemKNN发展史----推荐系统的三篇重要的论文解读
itemKNN发展史----推荐系统的三篇重要的论文解读 本文用到的符号标识 1.Item-based CF 基本过程: 计算相似度矩阵 Cosine相似度 皮尔逊相似系数 参数聚合进行推荐 根据用户 ...
- CVPR2019 | Mask Scoring R-CNN 论文解读
Mask Scoring R-CNN CVPR2019 | Mask Scoring R-CNN 论文解读 作者 | 文永亮 研究方向 | 目标检测.GAN 推荐理由: 本文解读的是一篇发表于CVPR ...
- Gaussian field consensus论文解读及MATLAB实现
Gaussian field consensus论文解读及MATLAB实现 作者:凯鲁嘎吉 - 博客园 http://www.cnblogs.com/kailugaji/ 一.Introduction ...
随机推荐
- Django4全栈进阶之路19 项目实战(用户管理):user_delete.html用户删除画面设计
1.user_list.html删除按钮链接设置: <td> <a class="btn btn-danger btn-xs" href="{% url ...
- 使用vite的创建vue项目
首先也是打开项目文件目录 在标签处快速打上cmd即可打开cmd窗口 然后按照顶部图进行操作即可完成 安装完成的样子如下图 紧接着输入 npm run dev 将Local 的IP复制到浏览器打开,出现 ...
- Vue 路由router
简单案例: App.vue是核心组件,其中的<router-link>相当于a标签,to相当于href,export是暴露函数,这样某组件才能被其他组件识别到 代码: <templa ...
- 聊聊MAUI、WinUI3和WPF的优势及劣势
今天在群里聊到WinUI3的学习及发展,还有他那堪比玩具的使用体验,正好梳理一篇关于WinUI3.MAUI和WPF优劣势,我整理的不是很好,所以又让ChatGPT在生成了一遍,感觉整体还可以.看完可以 ...
- 沉思篇-剖析JetPack的Lifecycle
这几年,对于Android开发者来说,最时髦的技术当属Jetpack了.谷歌官方从19年开始,就在极力推动Jetpack的使用,经过这几年的发展,Jetpack也基本完成了当时的设计目标--简单,一致 ...
- 1. SpringMVC 简介
1. 什么是 MVC MVC是一种软件架构的思想,将软件按照模型.视图.控制器来划分 M:Model,模型层,指工程中的JavaBean,作用是处理数据 JavaBean分为两类: 一类称为实 ...
- synchronized中wait、notify的原理与源码
synchronized中wait.notify的原理与源码 1.wait和notify的流程图 2.JVM源码 java层面wait的方法 public final native void wait ...
- range嵌套range beego前端页面渲染
range嵌套range beego前端页面渲染 问题 listA(name,age...) listB(hobby...) 有多个不同的list 对象,在前端中需要用range渲染,但是多个list ...
- C#中数组=out参数?
- 结论 先上结论,答案是yes,C#中数组确实具有out参数的特性. - 疑问 最近开发一个上位机的功能,有段代码看得我一直很迷糊,我的认识,函数的执行结果,要么在函数中通过return返回,要么通 ...
- 【Redis】字符串sds
sds,即 Simple Dynamic Strings,是Redis中存储绝大部分字符串所采用的数据结构. typedef char *sds; 一.类型 sds的类型包括SDS_TYPE_5, S ...