Pandas 使用教程 JSON
Pandas 可以很方便的处理 JSON 数据
demo.json
[
{
"name":"张三",
"age":23,
"gender":true
},
{
"name":"李四",
"age":24,
"gender":true
},
{
"name":"王五",
"age":25,
"gender":false
}
]
JSON 转换为 CSV
非常方便,只要通过 pd.read_json 读出JSON数据,再通过 df.to_csv 写入 CSV 即可
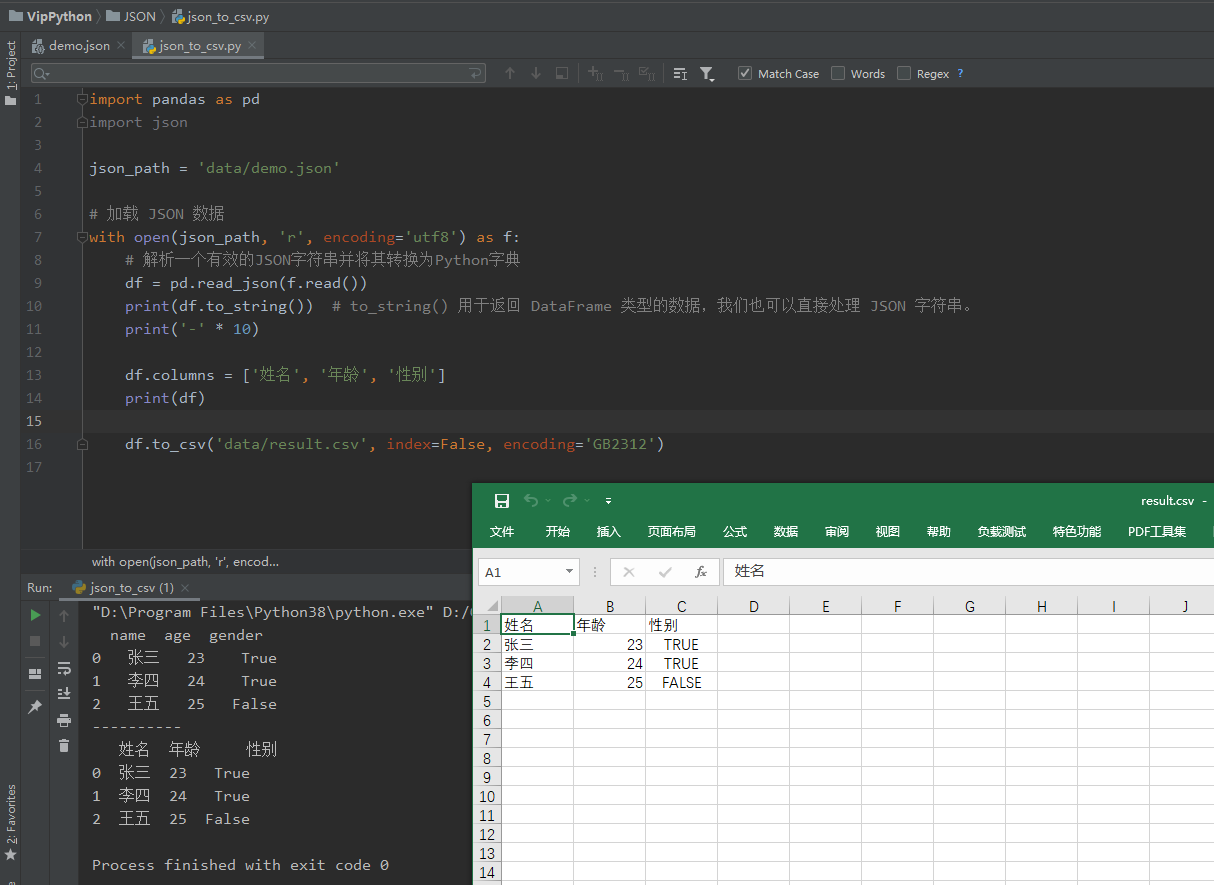
import pandas as pd
json_path = 'data/demo.json'
# 加载 JSON 数据
with open(json_path, 'r', encoding='utf8') as f:
# 解析一个有效的JSON字符串并将其转换为Python字典
df = pd.read_json(f.read())
print(df.to_string()) # to_string() 用于返回 DataFrame 类型的数据,我们也可以直接处理 JSON 字符串。
print('-' * 10)
# 重新定义标题
df.columns = ['姓名', '年龄', '性别']
print(df)
df.to_csv('data/result.csv', index=False, encoding='GB2312')
简单 JSON
从 URL 中读取 JSON 数据:
import pandas as pd
URL = 'https://static.runoob.com/download/sites.json'
df = pd.read_json(URL) # 和读文件一样
print(df)
输出:
id name url likes
0 A001 菜鸟教程 www.runoob.com 61
1 A002 Google www.google.com 124
2 A003 淘宝 www.taobao.com 45
字典转化为 DataFrame 数据
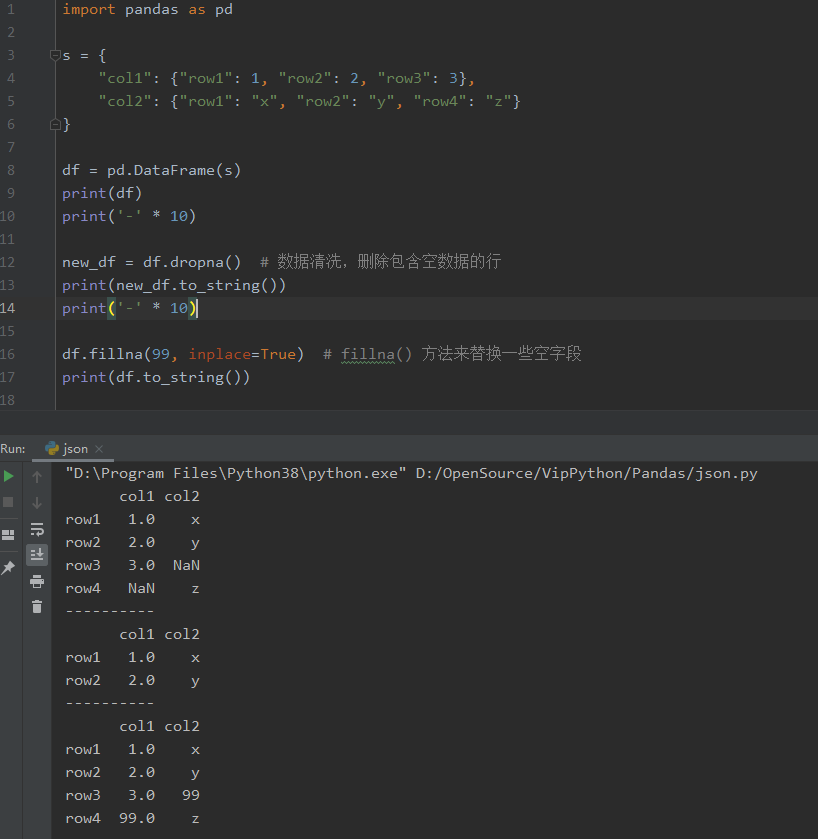
import pandas as pd
s = {
"col1": {"row1": 1, "row2": 2, "row3": 3},
"col2": {"row1": "x", "row2": "y", "row4": "z"}
}
df = pd.DataFrame(s)
print(df)
print('-' * 10)
new_df = df.dropna() # 数据清洗,删除包含空数据的行
print(new_df.to_string())
print('-' * 10)
df.fillna(99, inplace=True) # fillna() 方法来替换一些空字段
print(df.to_string())
输出:不同的行会用 NaN 填充
col1 col2
row1 1.0 x
row2 2.0 y
row3 3.0 NaN
row4 NaN z
----------
col1 col2
row1 1.0 x
row2 2.0 y
----------
col1 col2
row1 1.0 x
row2 2.0 y
row3 3.0 99
row4 99.0 z
内嵌的 JSON 数据
nested_list.json 嵌套的JSON数据
{
"school_name": "ABC primary school",
"class": "Year 1",
"students": [
{
"id": "A001",
"name": "Tom",
"math": 60,
"physics": 66,
"chemistry": 61
},
{
"id": "A002",
"name": "James",
"math": 89,
"physics": 76,
"chemistry": 51
},
{
"id": "A003",
"name": "Jenny",
"math": 79,
"physics": 90,
"chemistry": 78
}
]
}
运行代码
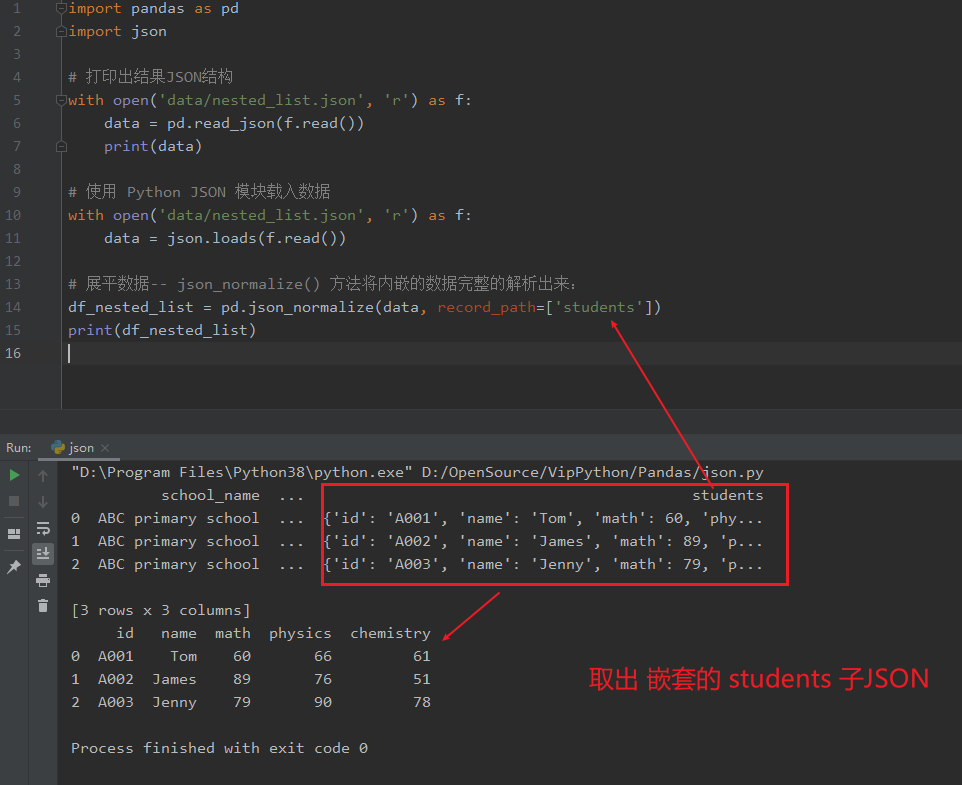
data = json.loads(f.read()) 使用 Python JSON 模块载入数据。
json_normalize() 使用了参数 record_path 并设置为 ['students'] 用于展开内嵌的 JSON 数据 students。
import pandas as pd
import json
# 打印出结果JSON结构
with open('data/nested_list.json', 'r') as f:
data = pd.read_json(f.read())
print(data)
# 使用 Python JSON 模块载入数据
with open('data/nested_list.json', 'r') as f:
data = json.loads(f.read())
# 展平数据-- json_normalize() 方法将内嵌的数据完整的解析出来:
df_nested_list = pd.json_normalize(data, record_path=['students'])
print(df_nested_list)
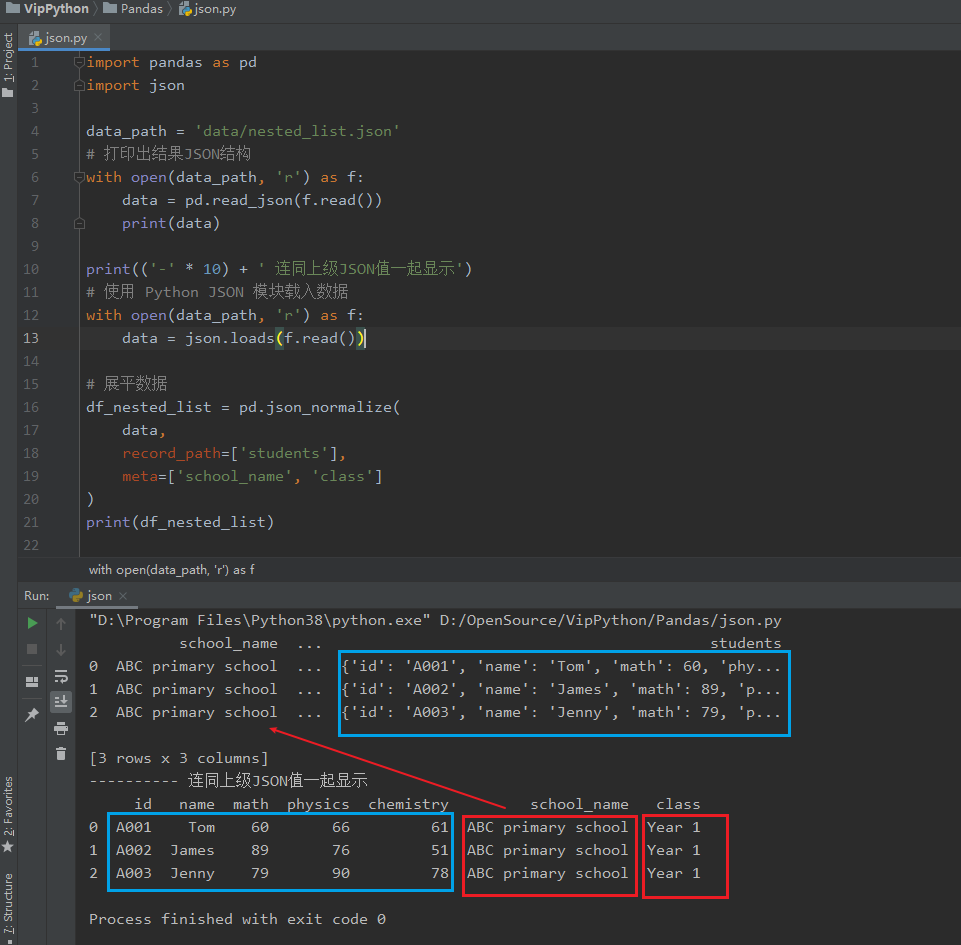
import pandas as pd
import json
data_path = 'data/nested_list.json'
print(('-' * 10) + ' 连同上级JSON值一起显示')
# 使用 Python JSON 模块载入数据
with open(data_path, 'r') as f:
data = json.loads(f.read())
# 展平数据
df_nested_list = pd.json_normalize(
data,
record_path=['students'],
meta=['school_name', 'class']
)
print(df_nested_list)
复杂 JSON
该数据嵌套了列表和字典,数据文件 nested_mix.json 如下
nested_mix.json
{
"school_name": "local primary school",
"class": "Year 1",
"info": {
"president": "John Kasich",
"address": "ABC road, London, UK",
"contacts": {
"email": "admin@e.com",
"tel": "123456789"
}
},
"students": [
{
"id": "A001",
"name": "Tom",
"math": 60,
"physics": 66,
"chemistry": 61
},
{
"id": "A002",
"name": "James",
"math": 89,
"physics": 76,
"chemistry": 51
},
{
"id": "A003",
"name": "Jenny",
"math": 79,
"physics": 90,
"chemistry": 78
}]
}
import pandas as pd
import json
# 使用 Python JSON 模块载入数据
with open('data/nested_mix.json', 'r') as f:
data = json.loads(f.read())
df = pd.json_normalize(
data,
record_path=['students'],
meta=[
'class',
['info', 'president'], # 类似 info.president
['info', 'contacts', 'tel']
]
)
print(df)
id name math ... class info.president info.contacts.tel
0 A001 Tom 60 ... Year 1 John Kasich 123456789
1 A002 James 89 ... Year 1 John Kasich 123456789
2 A003 Jenny 79 ... Year 1 John Kasich 123456789
[3 rows x 8 columns]
读取内嵌数据中的一组数据
nested_deep.json
{
"school_name": "local primary school",
"class": "Year 1",
"students": [
{
"id": "A001",
"name": "Tom",
"grade": {
"math": 60,
"physics": 66,
"chemistry": 61
}
},
{
"id": "A002",
"name": "James",
"grade": {
"math": 89,
"physics": 76,
"chemistry": 51
}
},
{
"id": "A003",
"name": "Jenny",
"grade": {
"math": 79,
"physics": 90,
"chemistry": 78
}
}]
}
这里我们需要使用到 glom 模块来处理数据套嵌,glom 模块允许我们使用 . 来访问内嵌对象的属性。
第一次使用我们需要安装 glom:
pip3 install glom -i https://pypi.tuna.tsinghua.edu.cn/simple
import pandas as pd
from glom import glom
df = pd.read_json('nested_deep.json')
data = df['students'].apply(lambda row: glom(row, 'grade.math'))
print(data)
输出:
0 60
1 89
2 79
Pandas 使用教程 JSON的更多相关文章
- Python 数据处理库 pandas 入门教程
Python 数据处理库 pandas 入门教程2018/04/17 · 工具与框架 · Pandas, Python 原文出处: 强波的技术博客 pandas是一个Python语言的软件包,在我们使 ...
- Pandas之:Pandas简洁教程
Pandas之:Pandas简洁教程 目录 简介 对象创建 查看数据 选择数据 loc和iloc 布尔索引 处理缺失数据 合并 分组 简介 pandas是建立在Python编程语言之上的一种快速,强大 ...
- Pandas之:Pandas高级教程以铁达尼号真实数据为例
Pandas之:Pandas高级教程以铁达尼号真实数据为例 目录 简介 读写文件 DF的选择 选择列数据 选择行数据 同时选择行和列 使用plots作图 使用现有的列创建新的列 进行统计 DF重组 简 ...
- Pandas系列教程——写在前面
之前搜pandas资料,发现互联网上并没有成体系的pandas教程,于是乎突然有个爱迪页儿,打算自己把官网的文档加上自己用pandas的理解,写成一个系列的教程, 巩固自己,方便他人 接下来就干这件事 ...
- 「Python」pandas入门教程
pandas适合于许多不同类型的数据,包括: 具有异构类型列的表格数据,例如SQL表格或Excel数据 有序和无序(不一定是固定频率)时间序列数据. 具有行列标签的任意矩阵数据(均匀类型或不同类型) ...
- Pandas基础教程
pandas教程 更多地可以 参考教程 安装 pip install pandas pandas的类excel操作,超级方便: import pandas as pd dates = pd.date_ ...
- 程序员用于机器学习编程的Python 数据处理库 pandas 进阶教程
数据访问 在入门教程中,我们已经使用过访问数据的方法.这里我们再集中看一下. 注:这里的数据访问方法既适用于Series,也适用于DataFrame. **基础方法:[]和. 这是两种最直观的方法,任 ...
- 程序员用于机器学习编程的Python 数据处理库 pandas 入门教程
入门介绍 pandas适合于许多不同类型的数据,包括: · 具有异构类型列的表格数据,例如SQL表格或Excel数据 · 有序和无序(不一定是固定频率)时间序列数据. · 具有行列标签的任意矩阵数据( ...
- PHP高级教程-JSON
PHP JSON 本章节我们将为大家介绍如何使用 PHP 语言来编码和解码 JSON 对象. 环境配置 在 php5.2.0 及以上版本已经内置 JSON 扩展. JSON 函数 函数 描述 json ...
- IT兄弟连 JavaWeb教程 JSON和JSON字符串
JSON (JavaScript Object Notation)是JavaScript语言中的一种对象类型.JSON的好处是易于阅读和解析.当客户端和服务器端需要交互大量数据时,使用JSON格式传输 ...
随机推荐
- Rust如何引入源码作为依赖
问题描述 通常我们在rust项目中引入第三方依赖包时,会直接指定包的版本,这种方式指定后,Cargo在编译时会从crates.io这个源中下载这些依赖包. [package] name = " ...
- Selenium - 浏览器操作
Selenium - 浏览器操作 获取浏览器信息 from selenium import webdriver driver = webdriver.Chrome() driver.get(" ...
- Django4全栈进阶之路21 项目实战(三种方式开发部门管理):方式二:CBV+Django内置类(ListView, CreateView, UpdateView, DeleteView, DetailView)
在 Django 中,视图(View)是处理请求并返回响应的主要机制.Django 中有许多视图类可用于处理常见的 CRUD(Create.Read.Update.Delete)操作以及其他类型的请求 ...
- ModuleNotFoundError: No module named 'flask_login'
ModuleNotFoundError: No module named 'flask_login' 解决: pip install flask_login
- ModuleNotFoundError: No module named 'pyecharts'
ModuleNotFoundError: No module named 'pyecharts' 解决: pip install pyecharts
- ICANN 2001-Learning to Learn Using Gradient Descent
Key Gradient Descent+LSTM元学习器 解决的主要问题 在之前的机器学习的学习方法中,不会利用到之前的经验,利用到之前经验的"knowledge transfer&quo ...
- Java商城网站系统设计与实现(带源码)
基于Java的商城网站系统设计与实现 功能介绍 平台采用B/S结构,后端采用主流的Springboot框架进行开发,前端采用主流的Vue.js进行开发. 整个平台包括前台和后台两个部分. 前台功能包括 ...
- 2023-05-18:有 n 名工人。 给定两个数组 quality 和 wage , 其中,quality[i] 表示第 i 名工人的工作质量,其最低期望工资为 wage[i] 。 现在我们想雇佣
2023-05-18:有 n 名工人. 给定两个数组 quality 和 wage , 其中,quality[i] 表示第 i 名工人的工作质量,其最低期望工资为 wage[i] . 现在我们想雇佣 ...
- this关键字理解
编译器对对象的加载步骤: (1)类名 (2)成员变量 (3)成员方法 即使定义类时,成员变量写在成员方法后面,加载对象时,也是先加载成员变量 当编译器识别方法时,会对成员方法改写,在所有方法里隐藏一个 ...
- openlayers 使用canvas绘制圆形头像图标
记录一个使用canvas 将一张图片等比缩放,裁剪为一个圆 1.原始图片 2.绘制后在地图中呈现的样式 3.设置样式的函数 /** * 设置Style */ setStyleOnPersonLocat ...