base64详解
base64详解
前置知识
位与字节
二进制系统中,每个0或1就是一个位(bit,比特),也叫存储单元,位是数据存储的最小单位。
其中8bit就称为一个字节(Byte)。
1B=8位
位运算
与运算:符号表示为&。运算规则:两位同时为“1”,结果才为“1”,否则为0或运算:符号表示为|。运算规则:两位只要有一位为“1”,结果就为“1”,否则为0
典型:
0000 0101 : 代表高四位, 代表低四位
char1&0x3:0x3是十六进制数,用二进制表示是0000 0011,用于提取char1的低两位,就是有1的那两位
char2&0xf0:0xf0是一个十六进制数,表示为二进制 11110000,用于提取 char2 的高四位。
移位操作
>>右移,<<左移
// 左移
01101000 << 2 -> 101000(左侧移出位被丢弃) -> 10100000(右侧空位一律补0)
// 右移
01101000 >> 2 -> 011010(右侧移出位被丢弃) -> 00011010(左侧空位一律补0)
base64编码
base64编码的概念
base64编码就是将字符串以每3个比特(bit)的字节子序列拆分为4个6比特(bit)的字节子序列(这个6比特是有效字节,最左边两个永远为0,其实也算是8比特的字节),再将得到的子序列查找base64的编码索引表,得到对应的字符拼接成新的字符串的一种编码方式。
每3个8比特(bit)的字节子序列拆分成4个6比特(bit)的字节序列的拆分过程如下图所示:

为什么base64编码后的大小是原来的4/3倍
因为6和8的最小公倍数是24,所以3个8比特的字节刚好可以拆分成4个6比特的字节,3 * 8 = 6 * 4。计算机中,因为一个字节需要8个存储单元存储,所以我们要把6个比特往前面补两位0,补足8个比特。如下图所示:

很明显,补足后所需的存储单元为32个,是原来所需的24个的4/3倍。现在大家明白为什么base64编码后的大小是原来的4/3倍了吧。
为什么命名为base64呢
因为6位的二进制有2的6次方个,也就是二进制数(0000 0000 - 0011 1111)之间的代表0-63的64个二进制数。
不是说一个字节是用8位二进制表示的吗,为什么不是2的8次方?
因为我们得到的8位二进制数的前两位永远是0,真正的有效位只有6位,所以我们所能够得到的二进制数只有2的6次方个。
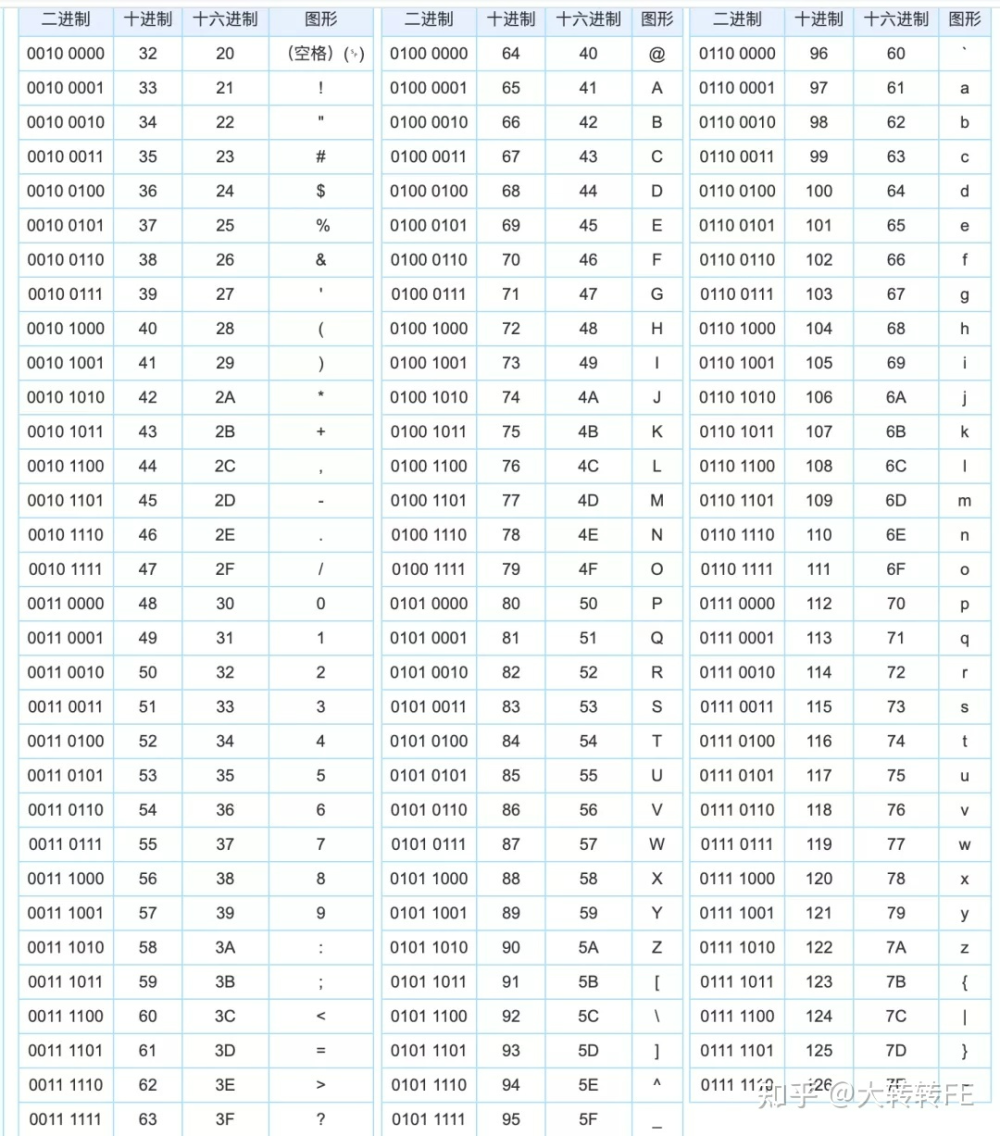
base64字符是哪64个
Base64的编码索引表,字符选用了"A-Z、a-z、0-9、+、/" 64个可打印字符来代表(00000000-00111111)这64个二进制数。即
let base64EncodeChars = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/'
编码原理
我们不妨自己先思考一下,要把3个字节拆分成4个字节可以怎么做?你的实现思路和我的实现思路有哪个不同,我们之间又会碰出怎样的火花?
流程图
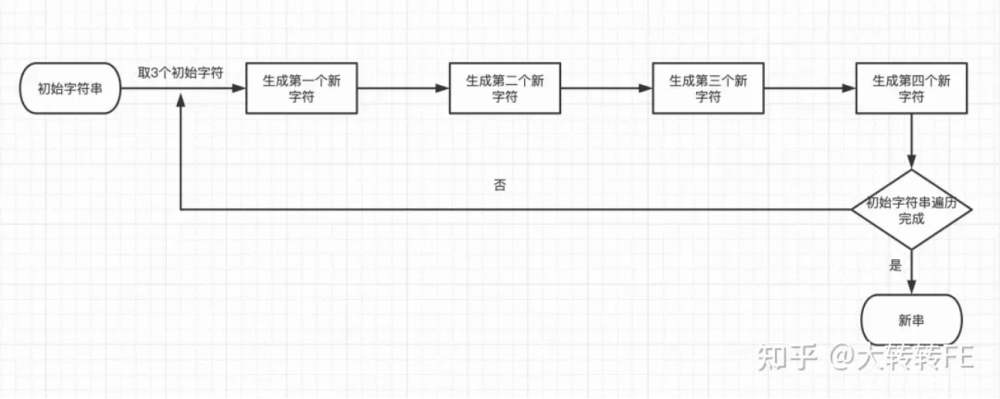
思路
分析映射关系:a b c -> x y z i
从高位到地位添加索引分析这个过程:
- x:(前面补2个0)a的前6位 => 00a[7]a[6] a[5]a[4]a[3]a[2]
- y:(前面补2个0)a的后2位 + b的前4位 => 00a[1]a[0] b[7]b[6]b[5]b[4]
- z:(前面补2个0)b的后4位 + c的前2位 => 00b[3]b[2] b[1]b[0]c[7]c[6]
- i:(前面补2个0)c的后6位 => 00c[5]c[4] c[3]c[2]c[1]c[0]
通过上面的分析,很容易得到实现思路:
- 将字符对应的ASCII编码转为8位的二进制
- 将每三个8位二进制数进行以下操作:
(1)将第一个数右移2位,得到第一个6位有效位二进制数
(2)将第一个数&0x3之后左移4位,得到第二个6位有效位二进制数的第一个和第二个有效位,将第二个数 & 0xf0之后右移位4位,得到第二个6位有效位二进制数的后四位有效位,两者取且得到第二个6位有 效位二进制
(3)将第二个数 & 0xf之后左移位2位,得到第三个6位有效位二进制数的前四位有效位,将第三个数 & 0xC0之后右移位6位,得到第三个6位有效位二进制数的后两位有效位,两者取且得到第三个6位有效 位二进制
(4)将第三个数 & 0x3f,得到第四个6位有效位二进制数
- 将获得的6位有效位二进制数转十进制,查找对应base64字符
注释:
char1&0x3的计算方法:先将char1和0x3转换为二进制,即0000 0011,按位与,作用是取char1的低两位
& 0xf0,即1111 0000,取高四位
& 0xf ,即0000 1111,取低四位
& 0xC0,即1100 0000,取高两位
& 0x3f ,即0011 1111,取低六位
base64编码实例
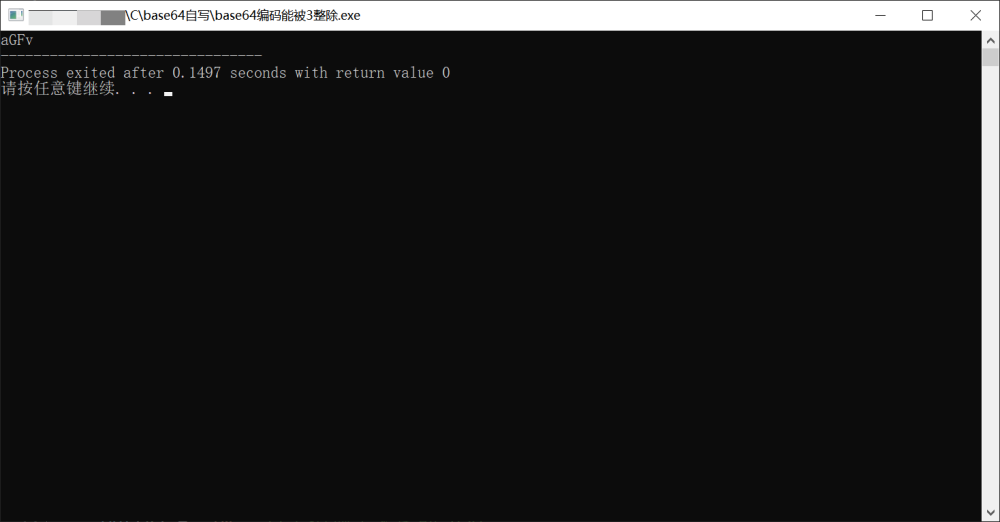
0x01
我们以hao字符串为例,观察base64编码的过程,我们将上面转换通过代码逻辑分析实现吧。

编码结果为aGFv
#include <stdio.h>
char base64EncodeChars[] = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/";
int main() {
char str[]="hao";
char char1,char2,char3,out1,out2,out3,out4;
char out[5];
// 将字符对应的ASCII值转为8位二进制数,& 0xff是为了保留8位二进制
char1 = str[0] & 0xff; // h 的ASCII为 104 二进制为 01101000
char2 = str[1] & 0xff; // a 的ASCII为 97 二进制为 01100001
char3 = str[2] & 0xff; // o 的ASCII为 111 二进制为 01101111
// 输出6位有效字节二进制数
out1 = char1 >> 2; // 26 011010
out2 = (char1 & 0x3) << 4 | (char2 & 0xf0) >> 4; // 6 000110
out3 = (char2 & 0xf) << 2 | (char3 & 0xc0) >> 6; // 5 000101
out4 = char3 & 0x3f; // 47 101111
out[0] = base64EncodeChars[out1]; //输出out1对应的ASCII
out[1] = base64EncodeChars[out2]; //输出out2对应的ASCII
out[2] = base64EncodeChars[out3]; //输出out3对应的ASCII
out[3] = base64EncodeChars[out4]; //输出out4对应的ASCII
out[4] = '\0'; //去掉输出末尾的'hao'
printf("%s",out);
return 0;
}
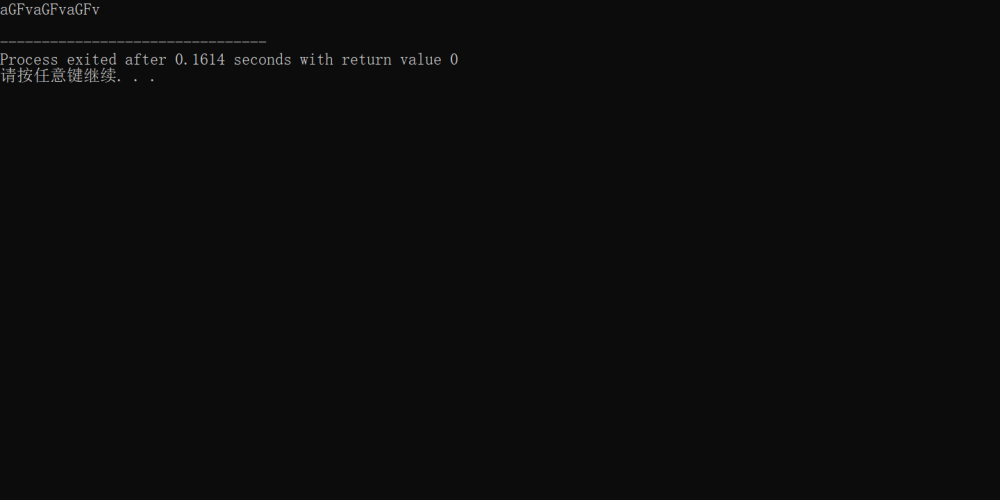
0x02
扩展至多字符字符串
#include<stdio.h>
#include<string.h> char base64EncodeChars[]="ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/" ; int main(){
char str[]="haohaohao";
char char1,char2,char3,out1,out2,out3,out4;
char out[100];
int len = strlen(str);
int index = 0;
int outindex = 0; while(index < len){
char1 = str[index++] & 0xff ;
char2 = str[index++] & 0xff ;
char3 = str[index++] & 0xff ; out1 = char1 >> 2 ;
out2 = (char1 & 0x3) << 4 | (char2 & 0xf0) >> 4 ;
out3 = (char2 & 0xf) << 2 | (char3 & 0xc0) >> 6 ;
out4 = char3 & 0x3f ; out[outindex++] = base64EncodeChars[out1];
out[outindex++] = base64EncodeChars[out2];
out[outindex++] = base64EncodeChars[out3];
out[outindex++] = base64EncodeChars[out4]; }
out[outindex] = '\0';
printf("%s\n",out);
return 0;
}
0x03
究极版base64编码
#include <stdio.h>
#include <stdlib.h> char* base64Encode(const char* str) {
// Base64 characters
const char base64EncodeChars[] = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/"; // Get string length
int len = 0;
while (str[len] != '\0') {
len++;
} // Output string
char* out = (char*)malloc(len * 4 / 3 + 4);
char* v11 = out; int index = 0; while (index < len) {
// Define input and output bytes
unsigned char char1, char2, char3;
unsigned char out1, out2, out3, out4; // Convert characters to ASCII codes
char1 = str[index++] & 0xff;
out1 = char1 >> 2; if (index == len) {
out2 = (char1 & 0x3) << 4;
sprintf(v11, "%c%c==", base64EncodeChars[out1], base64EncodeChars[out2]);
break;
} char2 = str[index++] & 0xff;
out2 = ((char1 & 0x3) << 4) | ((char2 & 0xf0) >> 4); if (index == len) {
out3 = (char2 & 0xf) << 2;
sprintf(v11, "%c%c%c=", base64EncodeChars[out1], base64EncodeChars[out2], base64EncodeChars[out3]);
break;
} char3 = str[index++] & 0xff;
out3 = ((char2 & 0xf) << 2) | ((char3 & 0xc0) >> 6);
out4 = char3 & 0x3f; sprintf(v11, "%c%c%c%c", base64EncodeChars[out1], base64EncodeChars[out2], base64EncodeChars[out3], base64EncodeChars[out4]);
v11 += 4;
} return out;
} int main() {
char* encodedStr = base64Encode("haohao");
printf("%s\n", encodedStr);
free(encodedStr); encodedStr = base64Encode("haoha");
printf("%s\n", encodedStr);
free(encodedStr); encodedStr = base64Encode("haoh");
printf("%s\n", encodedStr);
free(encodedStr); return 0;
}
base64自定义字符编码
#include <stdio.h>
#include <stdlib.h> char* base64Encode(const char* str) {
// Base64 characters
const char base64EncodeChars[] = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/"; // Get string length
int len = 0;
while (str[len] != '\0') {
len++;
} // Output string
char* out = (char*)malloc(len * 4 / 3 + 4);
char* v11 = out; int index = 0; while (index < len) {
// Define input and output bytes
unsigned char char1, char2, char3;
unsigned char out1, out2, out3, out4; // Convert characters to ASCII codes
char1 = str[index++] & 0xff;
out1 = char1 >> 2; if (index == len) {
out2 = (char1 & 0x3) << 4;
sprintf(v11, "%c%c==", base64EncodeChars[out1], base64EncodeChars[out2]);
break;
} char2 = str[index++] & 0xff;
out2 = ((char1 & 0x3) << 4) | ((char2 & 0xf0) >> 4); if (index == len) {
out3 = (char2 & 0xf) << 2;
sprintf(v11, "%c%c%c=", base64EncodeChars[out1], base64EncodeChars[out2], base64EncodeChars[out3]);
break;
} char3 = str[index++] & 0xff;
out3 = ((char2 & 0xf) << 2) | ((char3 & 0xc0) >> 6);
out4 = char3 & 0x3f; sprintf(v11, "%c%c%c%c", base64EncodeChars[out1], base64EncodeChars[out2], base64EncodeChars[out3], base64EncodeChars[out4]);
v11 += 4;
} return out;
} int main() {
char YourStr[100];
scanf("%s",&YourStr); char* encodedStr = base64Encode(YourStr);
printf("%s\n", encodedStr);
free(encodedStr); return 0;
}
解码原理
逆向推导,由每4个6位有效位的二进制数合并为3个8位二进制数,根据ASCII编码映射到对应字符后拼接字符串。
思路
分析映射关系x y z i -> a b c
- a:x的后6位 + y的第5、6位 => x[5] x[4] x[3] x[2] x[1] x[0] y[5] y[4]
- b:y的后4位 + z的第3、4、5、6位 => y[3] y[2] y[1] y[0] z[5] z[4] z[3] z[2]
- c:z的后2位 + i的后6位 => z[1] z[0] i[5] i[4] i[3] i[2] i[1] i[0]
- 将字符对应的base64字符集的索引转为6位有效位二进制数
- 将每四个6位有效位二进制数进行以下操作
(1)第一个二进制数左移位2位,得到新二进制数的前6位,第二个二进制数 & 0x30之后右移位4位, 或运算后得到第一个新二进制数
(2)第二个二进制数 & 0xf之后左移位4位,第三个二进制数 & 0x3c之后右移位2位,或运算后得到 第二个新二进制数
(3)第二个二进制数 & 0x3之后左移位6位,与第四个二进制数或运算后得到第二个新二进制数
- 根据ascII编码映射到对应字符后拼接字符串
base64解码实例
只有三个字符版本
#include <stdio.h>
#include <string.h> int main() {
char str[] = "aGFv";
char base64CharsArr[] = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/";
int char1, char2, char3, char4;
int out1, out2, out3;
char out[4]; // 获取索引值
char *ptr = strchr(base64CharsArr, str[0]);
if (ptr != NULL) {
char1 = ptr - base64CharsArr;
}
ptr = strchr(base64CharsArr, str[1]);
if (ptr != NULL) {
char2 = ptr - base64CharsArr;
}
ptr = strchr(base64CharsArr, str[2]);
if (ptr != NULL) {
char3 = ptr - base64CharsArr;
}
ptr = strchr(base64CharsArr, str[3]);
if (ptr != NULL) {
char4 = ptr - base64CharsArr;
} // 位运算
out1 = (char1 << 2) | ((char2 & 0x30) >> 4);
out2 = ((char2 & 0xf) << 4) | ((char3 & 0x3c) >> 2);
out3 = ((char3 & 0x3) << 6) | char4; // 输出结果
out[0] = out1;
out[1] = out2;
out[2] = out3;
out[3] = '\0';
printf("%s\n", out); return 0;
}
遇到有用'='补过位的情况时
#include <stdio.h>
#include <string.h>
#include <stdlib.h> char base64CharsArr[] = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/"; void base64decode(char str[]) {
int length = strlen(str);
int padding = 0; // 计算填充字符数量
if (str[length - 1] == '=') {
padding++;
if (str[length - 2] == '=')
padding++;
} // 计算解码后的字符数量
int decodedLength = (length * 3) / 4 - padding; // 分配存储解码结果的内存
char* decodedStr = (char*)malloc(decodedLength + 1); int outIndex = 0;
for (int i = 0; i < length; i += 4) {
char char1 = -1, char2 = -1, char3 = -1, char4 = -1; // 查找每个字符在Base64字符集中的索引
for (int j = 0; j < 64; j++) {
if (base64CharsArr[j] == str[i]) {
char1 = j;
break;
}
} for (int j = 0; j < 64; j++) {
if (base64CharsArr[j] == str[i + 1]) {
char2 = j;
break;
}
} for (int j = 0; j < 64; j++) {
if (base64CharsArr[j] == str[i + 2]) {
char3 = j;
break;
}
} for (int j = 0; j < 64; j++) {
if (base64CharsArr[j] == str[i + 3]) {
char4 = j;
break;
}
} // 解码并存储结果
decodedStr[outIndex++] = (char1 << 2) | ((char2 & 0x30) >> 4);
if (char3 != -1)
decodedStr[outIndex++] = ((char2 & 0xf) << 4) | ((char3 & 0x3c) >> 2);
if (char4 != -1)
decodedStr[outIndex++] = ((char3 & 0x3) << 6) | char4;
} // 添加字符串结束符
decodedStr[decodedLength] = '\0'; printf("Decoded string: %s\n", decodedStr); // 释放内存
free(decodedStr);
} int main() {
char str[] = "SGVsbG8gd29ybGQ="; // Example base64 encoded string
base64decode(str);
return 0;
}
解码整个字符串,整理代码后
#include <stdio.h>
#include <string.h>
#include <stdlib.h> char* base64decode(const char* str) {
// Base64字符集
const char base64CharsArr[] = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/";
int i = 0;
int len = strlen(str);
char* out = (char*)malloc(len * 3 / 4 + 1); // 分配足够的内存来存储解码后的字符串
int outIndex = 0; while (i < len) {
int char1 = strchr(base64CharsArr, str[i]) - base64CharsArr;
i++;
int char2 = strchr(base64CharsArr, str[i]) - base64CharsArr;
i++;
int out1, out2, out3; if (char1 == -1 || char2 == -1) {
out[outIndex] = '\0';
return out;
} char1 = char1 & 0xff;
char2 = char2 & 0xff; int char3 = strchr(base64CharsArr, str[i]) - base64CharsArr;
i++; // 第三位不在base64对照表中时,只拼接第一个字符串
out1 = (char1 << 2) | ((char2 & 0x30) >> 4);
if (char3 == -1) {
out[outIndex++] = out1;
out[outIndex] = '\0';
return out;
} int char4 = strchr(base64CharsArr, str[i]) - base64CharsArr;
i++; // 第四位不在base64对照表中时,只拼接第一个和第二个字符串
out2 = ((char2 & 0xf) << 4) | ((char3 & 0x3c) >> 2);
if (char4 == -1) {
out[outIndex++] = out1;
out[outIndex++] = out2;
out[outIndex] = '\0';
return out;
} // 位运算
out3 = ((char3 & 0x3) << 6) | char4; out[outIndex++] = out1;
out[outIndex++] = out2;
out[outIndex++] = out3;
} out[outIndex] = '\0';
return out;
} int main() {
char* decodedStr = base64decode("aGFvaGFv");
printf("%s\n", decodedStr); // 输出: haohao
free(decodedStr); decodedStr = base64decode("aGFvaGE=");
printf("%s\n", decodedStr); // 输出: haoha
free(decodedStr); decodedStr = base64decode("aGFvaA==");
printf("%s\n", decodedStr); // 输出: haoh
free(decodedStr); return 0;
}
总结
说起Base64编码可能有些奇怪,因为大多数的编码都是由字符转化成二进制的过程,而从二进制转成字符的过程称为解码。而Base64的概念就恰好反了,由二进制转到字符称为编码,由字符到二进制称为解码。Base64 是一种数据编码方式,可做简单加密使用,我们可以改变base64编码映射顺序来形成自己独特的加密算法进行加密解密。
编码表
|
码值 |
字符 |
码值 |
字符 |
码值 |
字符 |
码值 |
字符 |
|||
|
0 |
A |
16 |
Q |
32 |
g |
48 |
w |
|||
|
1 |
B |
17 |
R |
33 |
h |
49 |
x |
|||
|
2 |
C |
18 |
S |
34 |
i |
50 |
y |
|||
|
3 |
D |
19 |
T |
35 |
j |
51 |
z |
|||
|
4 |
E |
20 |
U |
36 |
k |
52 |
0 |
|||
|
5 |
F |
21 |
V |
37 |
l |
53 |
1 |
|||
|
6 |
G |
22 |
W |
38 |
m |
54 |
2 |
|||
|
7 |
H |
23 |
X |
39 |
n |
55 |
3 |
|||
|
8 |
I |
24 |
Y |
40 |
o |
56 |
4 |
|||
|
9 |
J |
25 |
Z |
41 |
p |
57 |
5 |
|||
|
10 |
K |
26 |
a |
42 |
q |
58 |
6 |
|||
|
11 |
L |
27 |
b |
43 |
r |
59 |
7 |
|||
|
12 |
M |
28 |
c |
44 |
s |
60 |
8 |
|||
|
13 |
N |
29 |
d |
45 |
t |
61 |
9 |
|||
|
14 |
O |
30 |
e |
46 |
u |
62 |
+ |
|||
|
15 |
P |
31 |
f |
47 |
v |
63 |
/ |
|||
参考:https://zhuanlan.zhihu.com/p/408318391
base64详解的更多相关文章
- ArrayBuffer转base64详解
先贴代码: const base64String = window.btoa(String.fromCharCode(... new Uint8Array(buffer))) 看起来非常的简洁,优美. ...
- Java 8新特性探究(五)Base64详解
BASE64 编码是一种常用的字符编码,在很多地方都会用到.但base64不是安全领域下的加密解密算法.能起到安全作用的效果很差,而且很容易破解,他核心作用应该是传输数据的正确性,有些网关或系统只能使 ...
- base64详解及实现
概述 base64 说起来大家应该都是很熟悉的,很多类型的数据都可以转成base64的编码规则,例如图片,pdf,文本,邮件内容等. 什么是base64 根据RFC2045的定义,base64被定义为 ...
- Android 数据加密算法 Des,Base64详解
一,DES加密: 首先网上搜索了一个DES加密算法工具类: import java.security.*;import javax.crypto.*; public class DesHelper { ...
- Java 8新特性探究(十一)Base64详解
开发十年,就只剩下这套架构体系了! >>> BASE64 编码是一种常用的字符编码,在很多地方都会用到.但base64不是安全领域下的加密解密算法.能起到安全作用的效果很差,而且 ...
- 图片上传预览转压缩并转base64详解(dShowImg64.js)
hello,大家好,游戏开始了,欢迎大家收看这一期的讲解.本次的内容是图片的上传预览.最后发源码链接.废话不多说,先上图. 待上传图像 点击蓝色框内,pc可以选择文件,移动端选择拍照或选择图片进行上传 ...
- Base64编码格式详解
什么是Base64? 按照RFC2045的定义,Base64被定义为:Base64内容传送编码被设计用来把任意序列的8位字节描述为一种不易被人直接识别的形式.(The Base64 Content-T ...
- EF+LINQ事物处理 C# 使用NLog记录日志入门操作 ASP.NET MVC多语言 仿微软网站效果(转) 详解C#特性和反射(一) c# API接受图片文件以Base64格式上传图片 .NET读取json数据并绑定到对象
EF+LINQ事物处理 在使用EF的情况下,怎么进行事务的处理,来减少数据操作时的失误,比如重复插入数据等等这些问题,这都是经常会遇到的一些问题 但是如果是我有多个站点,然后存在同类型的角色去操作 ...
- javascript中的Base64.UTF8编码与解码详解
javascript中的Base64.UTF8编码与解码详解 本文给大家介绍的是javascript中的Base64.UTF8编码与解码的函数源码分享以及使用范例,十分实用,推荐给小伙伴们,希望大家能 ...
- 详解前端模块化工具-webpack
webpack是一个module bundler,抛开博大精深的汉字问题,我们暂且管他叫'模块管理工具'.随着js能做的事情越来越多,浏览器.服务器,js似乎无处不在,这时,使日渐增多的js代码变得合 ...
随机推荐
- day03-Redis的客户端
Redis的Java客户端 在Redis官网中提供了各种语言的客户端,地址:Get started using Redis clients | Redis Redis的Java客户端: 1.Jedis ...
- 开心档之MySQL 序列使用
MySQL 序列使用 MySQL 序列是一组整数:1, 2, 3, ...,由于一张数据表只能有一个字段自增主键, 如果你想实现其他字段也实现自动增加,就可以使用MySQL序列来实现. 本章我们将 ...
- UE中根据场景模型,导出缩略图
在实际使用中,我们有了很多模型,但是有时候我们需要这些模型对应的缩略图,比如我有很多物品,我想弄个仓库,有2种方式,要么,弄个仓库场景,一个物体一个格子摆放第二种,就是为每个物体制作一个缩略图 如果一 ...
- fzy&czn生日赛t1 CZN
fzy&czn生日赛t1 CZN 膜拜hybb首杀 目录 fzy&czn生日赛t1 CZN 题目背景 题目描述 分析 my code wnag's code 题目 题目背景 有一天,c ...
- 自定义Python版本ESL库访问FreeSWITCH
环境:CentOS 7.6_x64Python版本:3.9.12FreeSWITCH版本 :1.10.9 一.背景描述 ESL库是FreeSWITCH对外提供的接口,使用起来很方便,但该库是基于C语言 ...
- 2022-11-03:给定一个数组arr,和一个正数k 如果arr[i] == 0,表示i这里既可以是左括号也可以是右括号, 而且可以涂上1~k每一种颜色 如果arr[i] != 0,表示i这里已经确
2022-11-03:给定一个数组arr,和一个正数k 如果arr[i] == 0,表示i这里既可以是左括号也可以是右括号, 而且可以涂上1~k每一种颜色 如果arr[i] != 0,表示i这里已经确 ...
- 2022-04-18:things是一个N*3的二维数组,商品有N件,商品编号从1~N, 比如things[3] = [300, 2, 6], 代表第3号商品:价格300,重要度2,它是6号商品的附属
2022-04-18:things是一个N3的二维数组,商品有N件,商品编号从1~N, 比如things[3] = [300, 2, 6], 代表第3号商品:价格300,重要度2,它是6号商品的附属商 ...
- React-hooks 父组件通过ref获取子组件数据和方法
我们知道,对于子组件或者节点,如果是class类,存在实例,可以通过 React.createRef() 挂载到节点或者组件上,然后通过 this 获取到该节点或组件. class RefTest e ...
- 【GiraKoo】夜神模拟器提示“当前设备未开启VT”
[解决]夜神模拟器提示"当前设备未开启VT" 环境 Windows 11 夜神模拟器64位 现象 启动夜神模拟器时,提示"检测到当前设备未开启VT,请先开启VT后再运行6 ...
- 前端开发如何更好的避免样式冲突?级联层(CSS@layer)
作者:vivo 互联网前端团队 - Zhang Jiqi 本文主要讲述了CSS中的级联层(CSS@layer),讨论了级联以及级联层的创建.嵌套.排序和浏览器支持情况.级联层可以用于避免样式冲突,提高 ...