Python FastAPI 获取 Neo4j 数据
前提条件
- 先往Neo4j 里,准备数据 参考:https://www.cnblogs.com/vipsoft/p/17631347.html#创建传承人
- 搭建 FastAPI 项目:https://www.cnblogs.com/vipsoft/p/17684079.html
改造
utils/neo4j_provider.py
增加了暴露给外面调用的属性,同时提供了同步和异步执行的驱动
#!/usr/bin/python3
import os
from neo4j import GraphDatabase, AsyncGraphDatabase, basic_auth, Driver, AsyncDriver
from settings import settings
# Neo4j 数据库操作类
class Neo4jProvider:
"""创建 Neo4j 数据库连接"""
def __init__(self) -> None:
# 获取环境变量值,如果没有就返回默认值
self.url = settings.NEO4J_URI
self.username = settings.NEO4J_USER
self.password = settings.NEO4J_PASSWORD
self.neo4j_version = settings.NEO4J_VERSION
self.database = settings.NEO4J_DATABASE
self.port = int(settings.NEO4J_PORT)
# 同步驱动
def driver(self) -> Driver:
return GraphDatabase.driver(self.url, auth=basic_auth(self.username, self.password))
# 异步驱动
def async_driver(self) -> AsyncDriver:
return AsyncGraphDatabase.driver(self.url, auth=basic_auth(self.username, self.password))
# 同步驱动。暴露给外面调用
driver = Neo4jProvider().driver()
# 异步驱动。暴露给外面调用
asyncDriver = Neo4jProvider().async_driver()
routers/node_router.py
添加一个查询数据的接口方法
#!/usr/bin/python3
import logging
from fastapi import APIRouter, status
from fastapi.responses import JSONResponse
from utils.neo4j_provider import asyncDriver
from settings import settings
router = APIRouter()
# 定义一个根路由
@router.get("/add")
def add_node():
# TODO 往 neo4j 里创建新的节点
data = {
'code': 0,
'message': '',
'data': 'add success'
}
return JSONResponse(content=data, status_code=status.HTTP_200_OK)
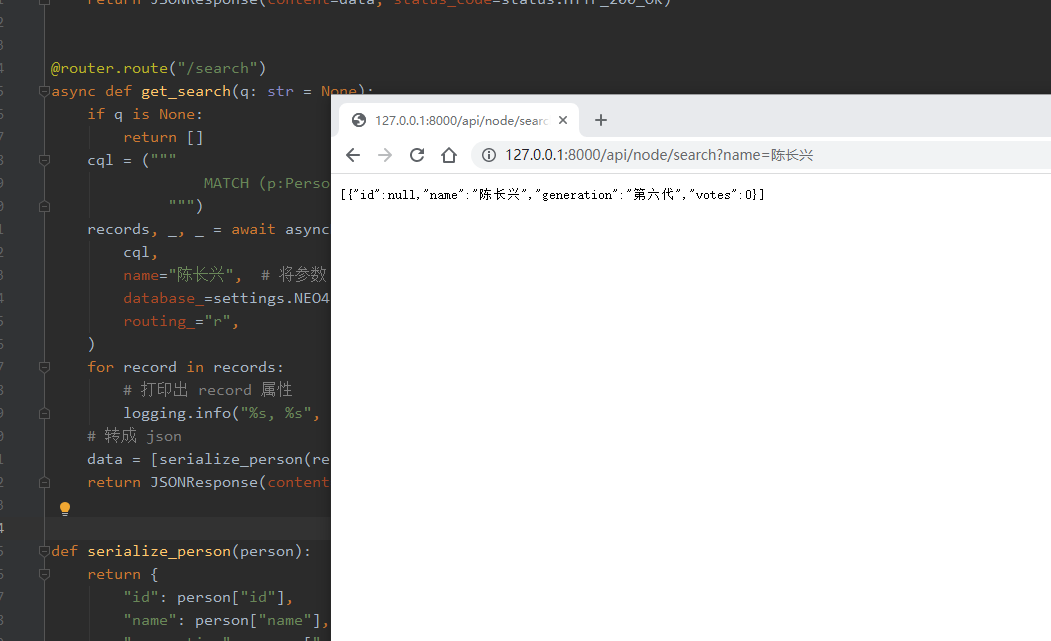
@router.route("/search")
async def get_search(q: str = None):
if q is None:
return []
cql = ("""
MATCH (p:Person) WHERE p.name CONTAINS $name RETURN p
""")
records, _, _ = await asyncDriver.execute_query(
cql,
name=q.query_params['name'], # 将参数 q 传给cql 里的 $name 变量 -- Python 很聪明,直接 q.query_params 就可以获取参数值了
database_=settings.NEO4J_DATABASE,
routing_="r",
)
for record in records:
# 打印出 record 属性
logging.info("%s, %s", record["p"]["name"], record["p"]["generation"])
# 转成 json
data = [serialize_person(record["p"]) for record in records]
return JSONResponse(content=data, status_code=status.HTTP_200_OK)
def serialize_person(person):
return {
"id": person["id"],
"name": person["name"],
"generation": person["generation"],
"votes": person.get("votes", 0)
}
运行效果
http://127.0.0.1:8000/api/node/search?name=%E9%99%88%E9%95%BF%E5%85%B4
Python FastAPI 获取 Neo4j 数据的更多相关文章
- 【原创】python爬虫获取网站数据并存入本地数据库
#coding=utf-8 import urllib import re import MySQLdb dbnumber = MySQLdb.connect('localhost', 'root', ...
- 洗礼灵魂,修炼python(57)--爬虫篇—知识补充—编码之对比不同python版本获取的数据
前面既然都提到编码了,那么把相关的编码问题补充完整吧 编码 之前我说过,使用python2爬取网页时,容易出现编码问题,下面就真的拿个例子来看看: python2下: # -*- coding:utf ...
- python修改获取xlsx数据
刚才要修改一个表格的数据,在网上搜了下方法,做出以下总结: 简单的取出数据以及写入数据 import xlrd data = xlrd.open_workbook(r'C:\Users\亦清\Desk ...
- 通过Python SDK 获取tushare数据
导入tushare import tushare as ts 这里注意, tushare版本需大于1.2.10 设置token ts.set_token('your token here') 以上方法 ...
- python之psutil模块(获取系统性能数据)
psutil模块 1.介绍 psutil是一个跨平台库(http://code.google.com/p/psutil/),能够轻松实现获取系统运行的进程和系统利用率(包括CPU.内存.磁盘.网络等) ...
- Python股票分析系列——系列介绍和获取股票数据.p1
本系列转载自youtuber sentdex博主的教程视频内容 https://www.youtube.com/watch?v=19yyasfGLhk&index=4&list=PLQ ...
- [Python爬虫] 之一 : Selenium+Phantomjs动态获取网站数据信息
本人刚才开始学习爬虫,从网上查询资料,写了一个利用Selenium+Phantomjs动态获取网站数据信息的例子,当然首先要安装Selenium+Phantomjs,具体的看 http://www.c ...
- python获取Excel数据
Python中一般使用xlrd(excel read)来读取Excel文件,使用xlwt(excel write)来生成Excel文件(可以控制Excel中单元格的格式),需要注意的是,用xlrd读取 ...
- 实时获取股票数据,免费!——Python爬虫Sina Stock实战
更多精彩内容,欢迎关注公众号:数量技术宅,也可添加技术宅个人微信号:sljsz01,与我交流. 实时股票数据的重要性 对于四大可交易资产:股票.期货.期权.数字货币来说,期货.期权.数字货币,可以从交 ...
- Python用pandas获取Excel数据
import pandas as pd df1 = pd.DataFrame(pd.read_excel(r'C:\python测试文件\我的三国啊.xlsx',sheet_name='Sheet1' ...
随机推荐
- git 创建本地分支并关联远程分支
1.查看远程分支 git branch 可以看到,我本地只有dev和master分支.现在同事创建了一个远程分支dev-glq,里面是他的代码.我应该再我本地创建一个分支,并且他的关联远程分支. 2. ...
- go语言reflection反射
一.反射 1.1简介 Reflection(反射)在计算机中就是表示程序在运行期间能够探知自身结构的能力类型(类型信息.内存结构.更新变量.以及调用方法) 1.2使用场景 函数的参数类型是interf ...
- js/javaScript实现金额千分位
作为前端开发,我们都知道,在实际的需求开发中,难免会遇到需要将接口返回的金额进行千分位格式化的场景.千分位后的金额便于阅读,提升用户体验.金额千分位可以由前端来处理,也可以后端处理后返回给前端展示. ...
- JVM SandBox 的技术原理与应用分析
https://www.infoq.cn/article/tsy4lgjvsfweuxebw*gp https://blog.csdn.net/qq_40378034/article/details/ ...
- Python 如何实现合并 PDF 文件?
在处理多个 PDF 文档时,频繁地打开关闭文件会严重影响效率.因此,对于一大堆内容相关的 PDF 文件,我们可以先将这些 PDF 文件合并起来再操作,从而提高工作效率.比如,在传送大量的 PDF 文档 ...
- SQL INSERT INTO 语句详解:插入新记录、多行插入和自增字段
SQL INSERT INTO 语句用于在表中插入新记录. INSERT INTO 语法 可以以两种方式编写INSERT INTO语句: 指定要插入的列名和值: INSERT INTO 表名 (列1, ...
- 小满OKKICRM与金蝶云星空对接集成客户资料
小满OKKICRM与金蝶云星空对接集成客户列表查询(更新列表)&客户新增(小满客户对接金蝶客户-P) 数据源平台:小满OKKICRM 小满科技成立于2013年,是阿里巴巴集团战略投资的高新技术 ...
- 洛谷2151 [SDOI2009]HH去散步(矩阵快速幂,边点互换)
题意:HH有个一成不变的习惯,喜欢饭后百步走.所谓百步走,就是散步,就是在一定的时间 内,走过一定的距离. 但是同时HH又是个喜欢变化的人,所以他不会立刻沿着刚刚走来的路走回. 又因为HH是个喜欢变化 ...
- 地图选择器datav怎么使用?
DataV 是一款基于阿里云的数据可视化产品,它提供了丰富的组件和功能,其中包括地图选择器.下面是一个详细的介绍: 1. 了解 DataV: - DataV 是一款强大的数据可视化工具,能够帮助用户将 ...
- 关于C#反射概念,附带案例!
反射 C#中的反射是一种使程序在运行时能够动态地获取类型信息并调用其成员的技术.通过反射,程序可以在运行时进行类型的动态加载.创建对象.调用方法和属性,以及访问和修改字段等.反射可以使程序更加灵活,但 ...