Python FastAPI 获取 Neo4j 数据
前提条件
- 先往Neo4j 里,准备数据 参考:https://www.cnblogs.com/vipsoft/p/17631347.html#创建传承人
- 搭建 FastAPI 项目:https://www.cnblogs.com/vipsoft/p/17684079.html
改造
utils/neo4j_provider.py
增加了暴露给外面调用的属性,同时提供了同步和异步执行的驱动
#!/usr/bin/python3
import os
from neo4j import GraphDatabase, AsyncGraphDatabase, basic_auth, Driver, AsyncDriver
from settings import settings
# Neo4j 数据库操作类
class Neo4jProvider:
"""创建 Neo4j 数据库连接"""
def __init__(self) -> None:
# 获取环境变量值,如果没有就返回默认值
self.url = settings.NEO4J_URI
self.username = settings.NEO4J_USER
self.password = settings.NEO4J_PASSWORD
self.neo4j_version = settings.NEO4J_VERSION
self.database = settings.NEO4J_DATABASE
self.port = int(settings.NEO4J_PORT)
# 同步驱动
def driver(self) -> Driver:
return GraphDatabase.driver(self.url, auth=basic_auth(self.username, self.password))
# 异步驱动
def async_driver(self) -> AsyncDriver:
return AsyncGraphDatabase.driver(self.url, auth=basic_auth(self.username, self.password))
# 同步驱动。暴露给外面调用
driver = Neo4jProvider().driver()
# 异步驱动。暴露给外面调用
asyncDriver = Neo4jProvider().async_driver()
routers/node_router.py
添加一个查询数据的接口方法
#!/usr/bin/python3
import logging
from fastapi import APIRouter, status
from fastapi.responses import JSONResponse
from utils.neo4j_provider import asyncDriver
from settings import settings
router = APIRouter()
# 定义一个根路由
@router.get("/add")
def add_node():
# TODO 往 neo4j 里创建新的节点
data = {
'code': 0,
'message': '',
'data': 'add success'
}
return JSONResponse(content=data, status_code=status.HTTP_200_OK)
@router.route("/search")
async def get_search(q: str = None):
if q is None:
return []
cql = ("""
MATCH (p:Person) WHERE p.name CONTAINS $name RETURN p
""")
records, _, _ = await asyncDriver.execute_query(
cql,
name=q.query_params['name'], # 将参数 q 传给cql 里的 $name 变量 -- Python 很聪明,直接 q.query_params 就可以获取参数值了
database_=settings.NEO4J_DATABASE,
routing_="r",
)
for record in records:
# 打印出 record 属性
logging.info("%s, %s", record["p"]["name"], record["p"]["generation"])
# 转成 json
data = [serialize_person(record["p"]) for record in records]
return JSONResponse(content=data, status_code=status.HTTP_200_OK)
def serialize_person(person):
return {
"id": person["id"],
"name": person["name"],
"generation": person["generation"],
"votes": person.get("votes", 0)
}
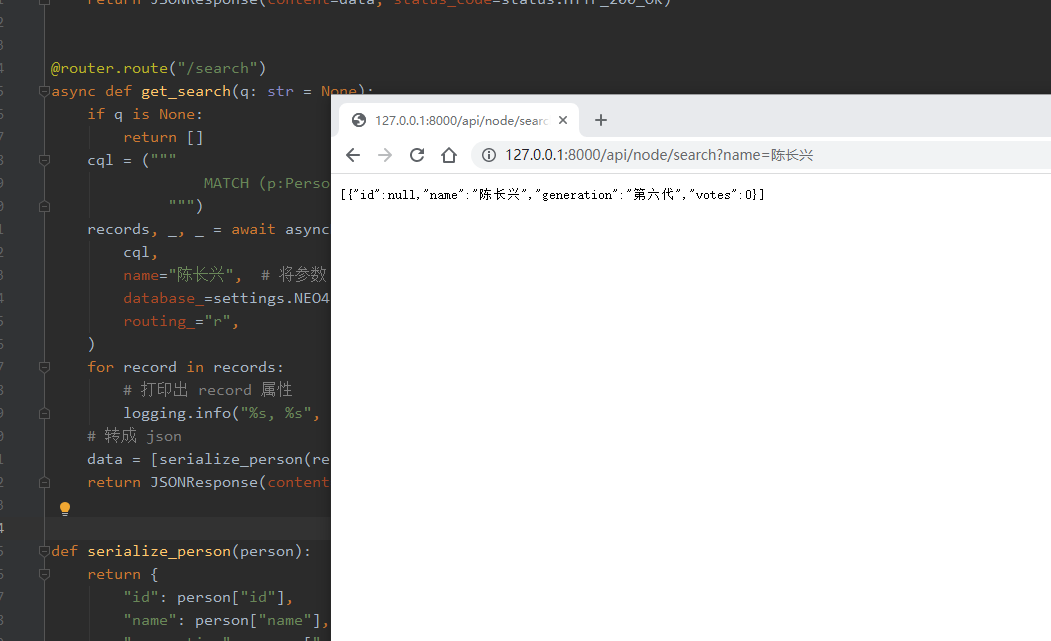
运行效果
http://127.0.0.1:8000/api/node/search?name=%E9%99%88%E9%95%BF%E5%85%B4
Python FastAPI 获取 Neo4j 数据的更多相关文章
- 【原创】python爬虫获取网站数据并存入本地数据库
#coding=utf-8 import urllib import re import MySQLdb dbnumber = MySQLdb.connect('localhost', 'root', ...
- 洗礼灵魂,修炼python(57)--爬虫篇—知识补充—编码之对比不同python版本获取的数据
前面既然都提到编码了,那么把相关的编码问题补充完整吧 编码 之前我说过,使用python2爬取网页时,容易出现编码问题,下面就真的拿个例子来看看: python2下: # -*- coding:utf ...
- python修改获取xlsx数据
刚才要修改一个表格的数据,在网上搜了下方法,做出以下总结: 简单的取出数据以及写入数据 import xlrd data = xlrd.open_workbook(r'C:\Users\亦清\Desk ...
- 通过Python SDK 获取tushare数据
导入tushare import tushare as ts 这里注意, tushare版本需大于1.2.10 设置token ts.set_token('your token here') 以上方法 ...
- python之psutil模块(获取系统性能数据)
psutil模块 1.介绍 psutil是一个跨平台库(http://code.google.com/p/psutil/),能够轻松实现获取系统运行的进程和系统利用率(包括CPU.内存.磁盘.网络等) ...
- Python股票分析系列——系列介绍和获取股票数据.p1
本系列转载自youtuber sentdex博主的教程视频内容 https://www.youtube.com/watch?v=19yyasfGLhk&index=4&list=PLQ ...
- [Python爬虫] 之一 : Selenium+Phantomjs动态获取网站数据信息
本人刚才开始学习爬虫,从网上查询资料,写了一个利用Selenium+Phantomjs动态获取网站数据信息的例子,当然首先要安装Selenium+Phantomjs,具体的看 http://www.c ...
- python获取Excel数据
Python中一般使用xlrd(excel read)来读取Excel文件,使用xlwt(excel write)来生成Excel文件(可以控制Excel中单元格的格式),需要注意的是,用xlrd读取 ...
- 实时获取股票数据,免费!——Python爬虫Sina Stock实战
更多精彩内容,欢迎关注公众号:数量技术宅,也可添加技术宅个人微信号:sljsz01,与我交流. 实时股票数据的重要性 对于四大可交易资产:股票.期货.期权.数字货币来说,期货.期权.数字货币,可以从交 ...
- Python用pandas获取Excel数据
import pandas as pd df1 = pd.DataFrame(pd.read_excel(r'C:\python测试文件\我的三国啊.xlsx',sheet_name='Sheet1' ...
随机推荐
- Redis创始人开源最小聊天服务器,仅200行代码,几天功夫已获2.8K Star!
中午时候,在技术交流群里聊起关于Redis创始人的一些趣事,比如离开Redis之后,去写科幻小说之类的. 因为好奇科幻小说,TJ君就去搜索了一下.结果一搜,发现Redis作者最近居然又搞了个新活儿! ...
- Codeforces Round #699 (Div. 2) A~C题解
写在前边 链接:Codeforces Round #699 (Div. 2) 好自闭哈哈,\(B\)题暴力fst了,第二天改了一个字母就A了,第3题写了一个小时,然后又调了三四个小时,看不到样例,最终 ...
- PIR传感器选型及其使用介绍
(一)PIR简介 PIR传感器(Passive Infrared Sensor),即被动式红外传感器.它因为功耗低,价格低廉,使用简单从而被大量使用在门铃.猫眼.感应开关.小夜灯.安防等消费类产品上. ...
- MongoDB 中的事务
MongoDB 事务 前言 如何使用 事务的原理 事务和复复制集以及存储引擎之间的关系 WiredTiger 中的事务隔离级别 WiredTiger 事务过程 事务开启 事务执行 事务提交 事务回滚 ...
- 提升开发技能:10个高级的JavaScript技巧
前言 在这个快速发展的数字时代,JavaScript作为一种广泛应用的编程语言,其重要性愈发凸显.为了在竞争激烈的开发领域中保持竞争力,不断提升自己的技能是至关重要的.本文小编将您介绍10个高级的Ja ...
- java集合框架(二)LinkedList的常见使用
@[toc]## 一.什么是LinkedList LinkedList是Java中的一个双向链表. 它实现了List和Deque接口,在使用时可以像List一样使用元素索引,也可以像Deque一样使用 ...
- 通过Span实现高性能数组,实例解析
Span<T> 是 C# 7.2 引入的一个强大的数据结构,用于表示内存中的一块连续数据.它可以用于实现高性能的数组操作,而无需额外的内存分配.在本文中,我将详细介绍如何使用 Span&l ...
- Vite4+Typescript+Vue3+Pinia 从零搭建(6) - 状态管理pina
项目代码同步至码云 weiz-vue3-template pina 是 vue3 官方推荐的状态管理库,由 Vue 核心团队维护,旨在替代 vuex.pina 的更多介绍,可从 pina官网 查看 特 ...
- scrapy 请求meta参数使用案例-豆瓣电影爬取
num = 0 import scrapy from scrapy.http import HtmlResponse from scrapy_demo.items import DoubanItem ...
- 浅谈android的activity
说道activity,大家可以说是熟悉的不能再熟悉,首先,先来个镇楼图, 个人觉得谷歌的这张图,比别的什么生命周期图都好;说下各个生命周期注意的: 1:onstart()时,activity可见; 2 ...