[转帖][译]ARM大小核架构白皮书
https://zhuanlan.zhihu.com/p/33411449
ARM big.LITTLE Processing with ARM Cortex-A15 & Cortex-A7
--Improving Energy Efficiency in High-Performance Mobile Platforms
关于
big.LITTLE是ARM提出的异构处理架构,结合了大核高性能处理以及小核低功耗工作的优点,能够提高高性能移动平台的能源效率。本文是翻译ARM官方介绍big.LITTLE架构的文档,如有错误,请多多指出。
原作者:Peter Greenhalgh, ARM
发表时间:September 2011
翻译作者:He11o_Liu
转载请注明出处
原文下载地址:ARM big.LITTLE Processing with ARM Cortex-A15 & Cortex-A7
内容提要
本文介绍了ARM big.LITTLE系统的基本原理和设计。本文设计的硬件有高性能Cortex-A15 MPCore处理器,高效能Cortex-A7 MPCore处理器,以及ARM CoreLink CCI-400 interconnect和相关的IP核。
big.LITTLE 简介
随着以手机为代表的移动终端的快速发展,移动处理器处理器对于性能的要求前所未有的大。用户既需要移动终端能够完成高强度的任务,如网页浏览与游戏,也期望其能够有足够的续航来完成低强度的任务,如发短信,邮件以及听音乐。
在ARM的第一个big.LITTLE系统设计中,一个`big`的ARM Cortex-A15处理器与一个`LITTLE`的ARM Cortex-A7处理器配合使用,构建起一个既能够完成高强度任务,同时具有不错的效能的系统。实际运用中,ARM Cortex-A15和ARM Cortex-A7处理器通过CoreLink CCI-400内部总线进行连接,组成一个足以面对各种运用场景的灵活系统。
big.LITTLE 架构的处理器
在big.LITTLE系统中,无论大小核处理器在架构上都是相同的。例如ARM Cortex-A15和ARM Cortex-A7都实现了完整的ARM v7A架构,包括虚拟化和大型物理地址扩展。 因此,所有的指令在Cortex-A15和Cortex-A7上运行都是“结构一致”(Architecturally consistent)相同的,除了两者性能差别导致的执行时间不同。
Cortex-A15和Cortex-A7特性集实现的定义也是类似的。 因此两个处理器都可以被配置为拥有一到四个核,并且都在处理器集群内部集成了一个l2级缓存。 另外,由于两个处理器都支持AMBA-4定义的片中总线,故可以使用CoreLink CCI-400内部总线进行连接。
Cortex-A15和Cortex-A7两者之间的差异主要体现在微架构(micro-architectures)中。
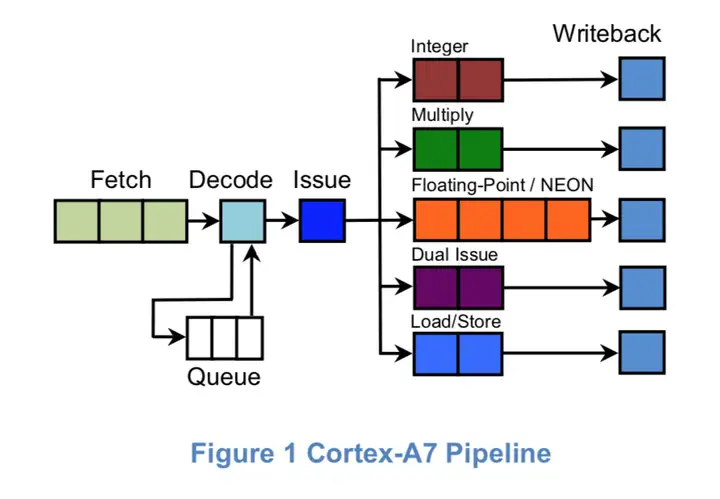
Cortex-A7是一个有序、非对称、双发射(超标量)处理器,其流水线长度在8-stages到10-stages之间。
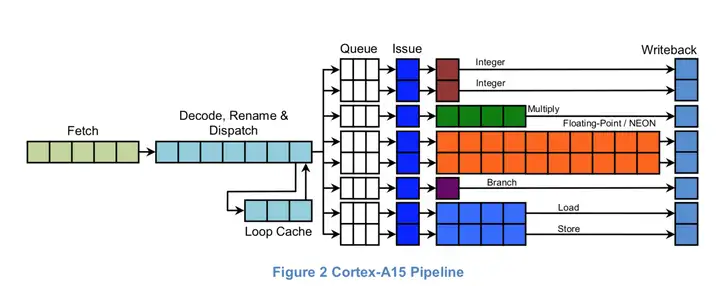
Cortex-A15是一个乱序、三发射(超标量)处理器,其流水线长度在15-stages到24-stages之间。
对于一条指令来说,执行其所消耗的能量有一部分是与其经历的流水线长度有关的。所以Cortex-A15和Cortex-A7之间的功耗差别很大程度与他们流水线长度有关。(当然,流水线越长,指令中可重叠的部分越多,CPU性能也越高。)
总的来说,Cortex-A15与Cortex-A7在微结构中采用了不同的倾向。Cortex-A15偏重性能,而Cortex-A7会牺牲性能来提高能源效率。这两种架构的l2级cache设计是这种折衷倾向的一个很好例子。通过在Cortex-A15和Cortex-A7之间共享一个l2级缓存,可以使两者进行互补。
Cortex-A15和Cortex-A7之间在性能和效能上的差异如下表所示:
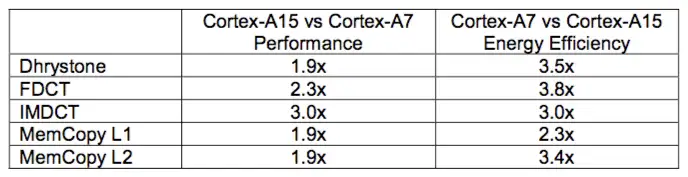
上表的第一列表示了从Cortex-A7到Cortex-A15的性能提升。第二列则表示了从Cortex-A15到Cortex-A7的效能提升。 上表中所有的测量都在相同设置的Cortex-A15和Cortex-A7处理器上完成,并使用相同的单元和RAM库。 所有在Cortex-A7上执行的代码都是为Cortex-A15编译的。
从上表可以看出 ,虽然Cortex-A7被标记为“LITTLE”处理器,但其性能上的表现依然非常不错。因此,相当可观数量的一些任务可以留在Cortex -A7上执行,而不用切换到Cortex-A15上执行。
big.LITTLE 的系统
big.LITTLE架构的另一个必须要考虑的问题是处理器间的系统该如何构建,才能完整发挥出big.LITTLE架构的优势。
其中最为关键的部分是利用CCI-400进行处理器间总线互连,它确保了Cortex-A15和Cortex-A7之间的完全一致性,同时也确保了与其他部件(如GPU)的IO一致性。同时兼顾 Cortex-A15与Cortex-A7之间的特性,主存访问以及系统的特征,我们可以找到一个最佳的方案。
big.LITTLE在A15与A7上面的实现的一个系统实例如下图所示:
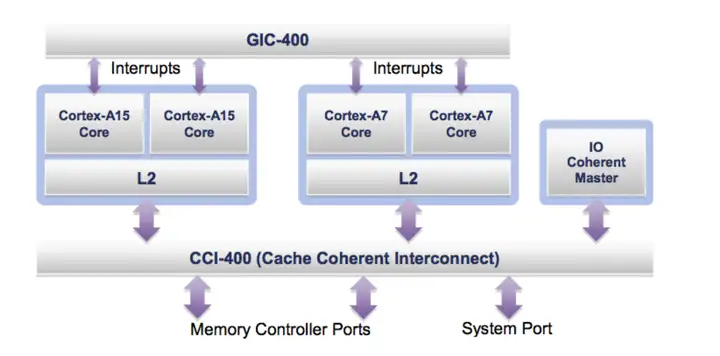
big.LITTLE架构的另一个重要的特性是Cortex-A15和Cortex-A7共享一个通用中断控制器(GIC-400)。多达480个中断可以分配给Cortex-A15和Cortex-A7。且可编程的中断控制器GIC-400允许在Cortex-A15或Cortex-A7集群中的任何核心之间迁移中断。
从跟踪和调试的角度来看,Cortex-A15和Cortex-A7都提供了跟踪解决方案,且两者都符合Debug v7.1体系结构。 通过CoreSight SoC,big.LITTLE提供了调试和跟踪的接口。
要考虑的最后一点是,虽然big.LITTLE架构并没有强制要求特定的组合,特定的环境, 但是考虑到big.LITTLE架构中任务迁移的复杂性,建议在Cortex-A15与Cortex-A7的集群中使用相同数量的内核。
big.LITTLE 的任务迁移模型 Model 1
big.LITTLE的任务迁移是在A15与A7之间,一个任务不会同时使用两个核心 。这种模式与动态电压和频率调节(DVFS)的思路类似。OS将会比较当前任务所需要的性能与当前使用处理簇平台的性能,并设置一个转换点(Operating point)。
例如,当前任务在Cortex-A7执行时,操作系统将会计算出当前平台处理的最高工作点(Operation Point)。 一旦Cortex-A7处于最高工作点,且还需要更多的资源,操作系统和应用程序将会移动到Cortex-A15上开始执行。
Cortex-A15-Cortex-A7 DVFS 曲线图见下:
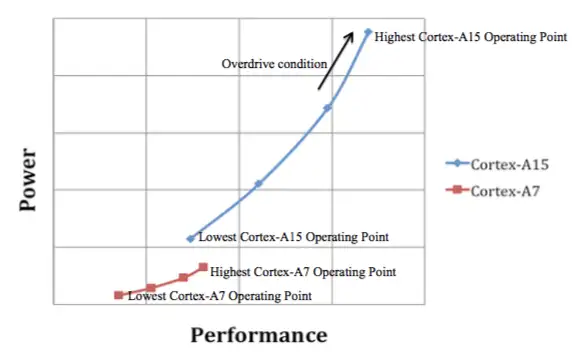
big.LITTLE系统的另一个需要严肃考虑的问题是在Cortex-A15集群和Cortex-A7集群之间迁移任务所需的时间。如果花费时间太长,有可能会得不偿失,反而没有直接在A7上运行快。因此,Cortex-A15-Cortex-A7系统设计成在1GHz下,迁移花费在 20,000个周期(20ms)以内。
任务迁移可以如此之快的原因之一是任务迁移涉及到的处理器状态空间是比较小的。 即将被关闭的处理器(出站处理器)必须保存所有 整数和高级SIMD 寄存器文件内容与 整个CP15配置状态内容。 即将恢复执行的处理器(入站处理器)将按照刚才保存的文件恢复所有状态。另外,由GIC-400控制的处理中中断也必须要迁移。整个保存-恢复的流程只用不到2000条指令就实现,这是因为两个处理器在结构上是相同的,故在入站和出站处理器之间可以建立一个一对一的状态寄存器映射。
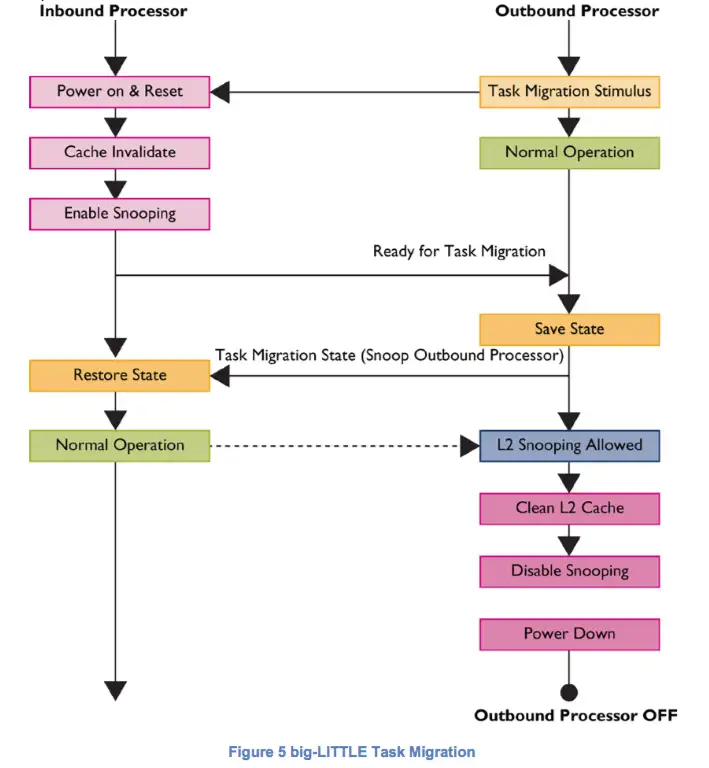
上图描述了入站和出站处理器之间的任务迁移的整个流程。一致性是能够实现快速迁移的保证,因为其能够使入站处理器直接从出站处理器的保存状态中进行恢复,而不用走主存。此外,由于出站处理器的二级缓存是一致的,因此可以在任务迁移之后保持在线,以改善入站处理器的高速缓存冷启动(warming time)时间。但是,由于出站处理器的已经分配的二级缓存不能再使用,其最终还是需要清理、关闭。
还应该注意的是,在任务迁移过程中当前正在执行的线程。对于该线程来说,运行暂停只是存在于关闭中断开始迁移的这一小段时间。
big.LITTLE MP模型 Model 2
除了上面描述的任务迁移模型,另一个模型是允许Cortex-A15和Cortex-A7同时通电并同时执行代码。这个模型被称为big.LITTLE MP,它本质上是异构/异质的多核处理(Multi-Processing)。在这种模型下,Cortex-A7是一直在线的,只有当需要更多的计算资源时,Cortex-A15才上线并与Cortex-A7同时执行。
big.LITTLE MP最为引人注目的特点是其能使线程在最合适的处理资源上执行。对于那些计算密集的线程,且需要大量的处理性能,因为它们的输出是用户可见的,可以分配给Cortex-A15执行。 而对于那些大量处理I/O或者不需要立刻提供给用户(非时间敏感)的任务,都可以交给Cortex-A7执行。例如电子邮件的后台更新就是一个这样的例子。当用户在浏览其他网页时,用户期望电子邮件也会继续在后台更新,但是此时对于时效性要求就没有那么高。由于Cortex-A7更节能,消耗更少的电量,故该任务可以交给Cortex-A7来执行。
最后,作为一个完全一致的系统,为了维持一致性可能会导致很高的维持一致性开销。但是Cortex-A15,Cortex-A7和CCI-400的设计考虑了应对这种最糟糕的情况。 比如当Mali-T604 GPU连接到其中一个I/O 一致性 CCI-400端口时的情况。在这种情况下,为了维持一致性GPU会对Cortex-A15与Cortex-A7的变量进行监听,同时Cortex-A15与Cortex-A7也会相互进行监听。
big.LITTLE的软件
作为big.LITTLE系统的一部分,ARM提供了一个运行在Cortex-A15,Cortex-A7,CCI-400和GIC-400架构上的软件转换器(切换器)。该转换器有两个目的:
- 第一个目的是提供Cortex-A15和Cortex-A7之间进行任务迁移所需的所有机制。 以及处理器状态的保存与还原、处理器上下线时的一致性、互连总线中的控制监听(control snooping in the interconnect)以及中断迁移所需要的代码。这部分代码可以被整合到操作系统中来支持big.LITTLE架构。
- 第二个目的是向操作系统隐藏Cortex-A15与Cortex-A7中的细微的差异。虽然Cortex-A15和Cortex-A7在架构上是相同的,且所有寄存器都以体系结构一致的方式读取和写入,但是寄存器的内容可能并不总是相同的。 所以Cortex-A15和Cortex-A7在编程模型上并不是完全相同的,需要通过一部分处理向操作系统隐藏着一部分的差异。例如,Cortex-A15和Cortex-A7中的 Main ID寄存器的内容将会不同,该寄存器用于标示处理器类型(当然会不同),以及用于描述1级和2级缓存拓扑的CP15寄存器的内容也会不相同。 幸运的是,由于Cortex-A15和Cortex-A7都实现了虚拟化,操作系统在访问这些寄存器只会触及虚拟化层,而转换器程序可以在这里处理这些差异。
ARM提供的转换器代码使得当今的操作系统都能够比较轻松地移植到big.LITTLE架构上来。然而,可能有少数大小核之间有差异的编程模型希望由操作系统来处理,而不是由转换器来处理(对于状态保存与恢复部分的代码)。
总结
本白皮书描述了ARM的第一个big.LITTLE架构并描述了该架构的一个具体实现:由Cortex-A15和Cortex -A7组合而成的系统。该系统为移动高性能计算领域开辟了新的思路,新的可能。
现有架构只能利用一个处理器来应对各种高、低性能需求的应用与场景,而big.LITTLE可以动态适应应用以及场景,在需要更多计算资源是才开启A15核心。该架构相较于传统架构有更多的灵活性,既能够面对高性能要求的场景,又拥有不错的能效表现。
总的来说,big.LITTLE架构提供了在下一代移动平台上提升性能同时兼顾续航,延长电池寿命的思路。
[转帖][译]ARM大小核架构白皮书的更多相关文章
- ARM Linux 大小核切换 ——cortex-A7 big.LITTLE 大小核 切换代码分析
ARM Linux 大小核切换——cortex-A7 big.LITTLE 大小切换代码分析 8核CPU或者是更多核的处理器,这些CPU有可能不完全对称.有的是4个A15和4个A7,或者是4个A57和 ...
- 关于ARM的内核架构
很多时候我们都会对M0,M0+,M3,M4,M7,arm7,arm9,CORTEX-A系列,或者说AVR,51,PIC等,一头雾水,只知道是架构,不知道具体是什么,有哪些不同?今天查了些资料,来解解惑 ...
- ARM CORTEX-M3 内核架构理解归纳
ARM CORTEX-M3 内核架构理解归纳 来源:网络 个人觉得对CM3架构归纳的非常不错,因此转载 基于<ARM-CORTEX M3 权威指南>做学习总结: 在我看来,Cotex-M3 ...
- 关于ARM内核与架构的解释
本文摘自某论坛某位大神的一段回复,经典至极,copy来己用! 只要你玩过ARM内核的芯片,那么关于内核和架构,我想应该或多或少的困惑过你,看了下面的介绍,你应该会清楚很多! 好比你盖房子,刚开始因为水 ...
- ARM和X86架构
重温下CPU是什么 中央处理单元(CPU)主要由运算器.控制器.寄存器三部分组成.运算器起着运算的作用,控制器负责发出CPU每条指令所需要的信息,寄存器保存运算或者指令的一些临时文件以保证更高的速度. ...
- ARM与X86架构的对决[整编]
CISC(复杂指令集计算机)和RISC(精简指令集计算机)是当前CPU的两种架构.它们的区别在于不同的CPU设计理念和方法.早期的CPU全部是CISC架构,它的设计目的是 CISC要用最少的机器语言 ...
- 【ARM】---关于ARM内核与架构的解释
本文摘自某论坛某位大神的一段回复,经典至极,copy来己用! 只要你玩过ARM内核的芯片,那么关于内核和架构,我想应该或多或少的困惑过你,看了下面的介绍,你应该会清楚很多! 好比你盖房子,刚开始因为水 ...
- 大数据架构-使用HBase和Solr将存储与索引放在不同的机器上
大数据架构-使用HBase和Solr将存储与索引放在不同的机器上 摘要:HBase可以通过协处理器Coprocessor的方式向Solr发出请求,Solr对于接收到的数据可以做相关的同步:增.删.改索 ...
- 后Hadoop时代的大数据架构(转)
原文:http://zhuanlan.zhihu.com/donglaoshi/19962491 作者: 董飞 提到大数据分析平台,不得不说Hadoop系统,Hadoop到现在也超过10年 ...
- Java系的大网站架构-LinkedIn和淘宝
国内私募机构九鼎控股打造APP,来就送 20元现金领取地址:http://jdb.jiudingcapital.com/phone.html 内部邀请码:C8E245J (不写邀请码,没有现金送) 国 ...
随机推荐
- 三步实现BERT模型迁移部署到昇腾
本文分享自华为云社区 <bert模型昇腾迁移部署案例>,作者:AI印象. 镜像构建 1. 基础镜像(由工具链小组统一给出D310P的基础镜像) From xxx 2. 安装mindspor ...
- 小熊派开发实践丨小熊派+合宙Cat.1接入云服务器
摘要:使用小熊派开发板,以合宙的AIR724为通信模组(Cat.1),以AT指令方式,通过mqtt协议接入云服务器. 本贴使用小熊派开发板+合宙的Air724(Cat.1模组),接入自己搭建的EMQ服 ...
- “互联网+”大赛之AI创新应用赛题攻略:大胆脑洞,共绘智慧生活蓝图
摘要:本次"互联网+"大赛AI创新应用赛题的设置是希望学生可以从日常实际应用需求出发,结合自己的奇思妙想,提升智能终端用户的使用体验,为构建万物互联的智能世界贡献一份力量. 本文分 ...
- MPU:鸿蒙轻内核的任务栈的溢出检察官
摘要:MPU(Memory Protection Unit,内存保护单元)把内存映射为一系列内存区域,定义这些内存区域的维洲,大小,访问权限和内存熟悉信息. 本文分享自华为云社区<鸿蒙轻内核M核 ...
- 创建一个科学决策必备的A/B实验,都需要哪些准备?——火山引擎 DataTester 使用指南
更多技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,回复[1]进入官方交流 DataTester 是火山引擎数智平台旗下产品,能基于先进的底层算法,提供科学分流能力和智能的统计引擎,支持多种复 ...
- 如临现场的视觉感染力,NBA决赛直播还能这样看?
在6月16日结束的NBA总决赛中,勇士4-2击败凯尔特人,问鼎总冠军!今年的NBA总决赛吸引了众多关注,互联网各大平台的赛事直播气氛也异常热烈. 平台如何既能展现专业的赛事解说,又能与球迷观众深入互动 ...
- SpringMVC — 数据响应 / 获取请求参数
SpringMVC的数据响应方式 页面跳转 直接返回字符串 通过ModelAndView对象返回 回写数据 直接返回字符串 返回对象或集合 页面跳转 方式一.返回带有前缀的字符串: 转发:forwar ...
- 技术分享 | 不同格式标准SBOM清单横评:SPDX、CDX和DSDX
为了保证安全性.降低开发.采购及维护的相关成本,复杂动态的现代软件供应链对软件资产透明度提出了更高的要求.使用清晰的软件物料清单(SBOM)收集和共享信息,并在此基础上进行漏洞.许可证和授权管理等,可 ...
- uni-app 从入门到放弃(持续更新)
https://blog.csdn.net/weixin_33940102/article/details/91460204
- Invalid options object. Sass Loader has been initialized using an options obj
https://blog.csdn.net/liwan09/article/details/106981239