【行云流水线】满足你对工作流编排的一切幻想~skr
流水线模型
众所周知,DevOps流水线(DevOps pipeline)的本质是实现自动化工作流程,用于支持软件开发、测试和部署的连续集成、交付和部署(CI/CD)实践。它是DevOps方法论的核心组成部分,旨在加速软件交付、提高质量和实现持续改进。流水线的核心是流水线模型,是实现工作流编排,执行的重要基石,一个优秀的流水线模型可以覆盖用户更多的实践场景,按照用户的所思所想支持编排相应的工作流程,通过模型的分层设计,通用原子能力的生态建设,尽可能满足用户的任意场景的需求。
流水线模型基于将整个工作流程划分为一系列连续的阶段或任务,并通过将每个阶段的输出作为下一个阶段的输入,实现高效的生产或处理流程。每个阶段专注于特定的任务,并将其结果传递给下一个阶段,以便整个过程能够连续地进行。
优秀的流水线模型特征
生活中的流水线
说起生活中的流水线大家可能想到的是车间,厂房中的流水线。这个也是经常被拿出来举例的场景。但我今天不举这个例子。大家可以思考下这两个场景有什么区别?

任天堂Switch有一款叫做“胡闹厨房”的游戏,俗称“分手厨房”,据说一玩就分手。这是一款以高难度合作著称的游戏,在形形色色的厨房中,你需要和你的同伴一起克服重重难关,按照指定的顺序生产出美味佳肴,满足客人的味蕾。在游戏过程中,制作一道菜需要完成许多的步骤,这就像我们在工作中使用的流水线,流水线有个总目标,也会拆分成几个阶段来完成分阶段的目标,作为下个阶段的输入。
这里我们以“制作Pizza”的流程为例,简单的把操作拆分为4个阶段:准备食材Prepare(如鸡肉,起司,青椒等),揉面Knead(面粉,油,发酵),制作(组合准备的食材与披萨底座),最终烘焙完成。在整个流程中,前后阶段是隐含着依赖关系,并驱动每一个阶段继续执行下去。

回想我们在实际工作中的流程,往往并不能通过简单的串联并联解决问题。都是有依赖关系的执行流程,场景可能比以上例子更复杂。

行云流水线模型升级
在众多流水线能力中,工作流的编排和执行能力是最核心的能力,也是用户实现自定义流程配置的基础和载体。行云流水线通过把流程中的不同阶段和任务串联在一起,实现提高阶段见的连接效率,通过阶段内部的垂直领域原子能力,实现阶段内各个原子或步骤的执行效率提升。
为了能更好的支撑用户的使用场景,云原生流水线升级了工作流模型。
流水线模型与交付流程的映射

竞品分析
对比Harness,Azure,Github Actions等平台在不同pipeline维度的模型策略
| 行云流水线 | Harness | Azure | Github | 云效 | |
| 执行模式-Stage级 | DAG 默认parallel | serial/parallel | DAG 默认serial | DAG 默认parallel | serial |
| 执行模式-Job/Atom级 | serial | serial/parallel | serial | serial | parallel |
| 编排模式-图形化 | |||||
| 编排模式-yaml |
serial:只串行执行 parallel:只并行执行 serial/parallel:支持串并行组合方式,编排workflow DAG:依赖声明方式编排workflow 默认serial:无依赖声明的步骤,串行编排 默认parallel:无依赖声明的步骤,并行编排
平台用户的最佳实践
场景1:测试环境的按需更新与测试
测试环境一般不是独立存在的,可能也不是只更新某一个服务就可以满足测试条件的。在这种情况下,用户结合环境拓扑的概念,先基于拓扑创建一套环境,再更新所需的多个服务实例,以快速,自动化的方式实现测试环境的按需更新。通过准入流水线,创建测试环境(创建拓扑环境,更新拓扑节点等),并进行接口测试

下图为用户流水线编排界面


场景2:多维度的数据资源收集与分析
在数据分析的业务场景下,此流水线支持SRAS搜推算法服务,作为推送模型到线上的前置准备任务。用户需要收集多维度的数据源信息,通过扇入的方式聚合数据,并通过python脚本逻辑做数模型据汇总
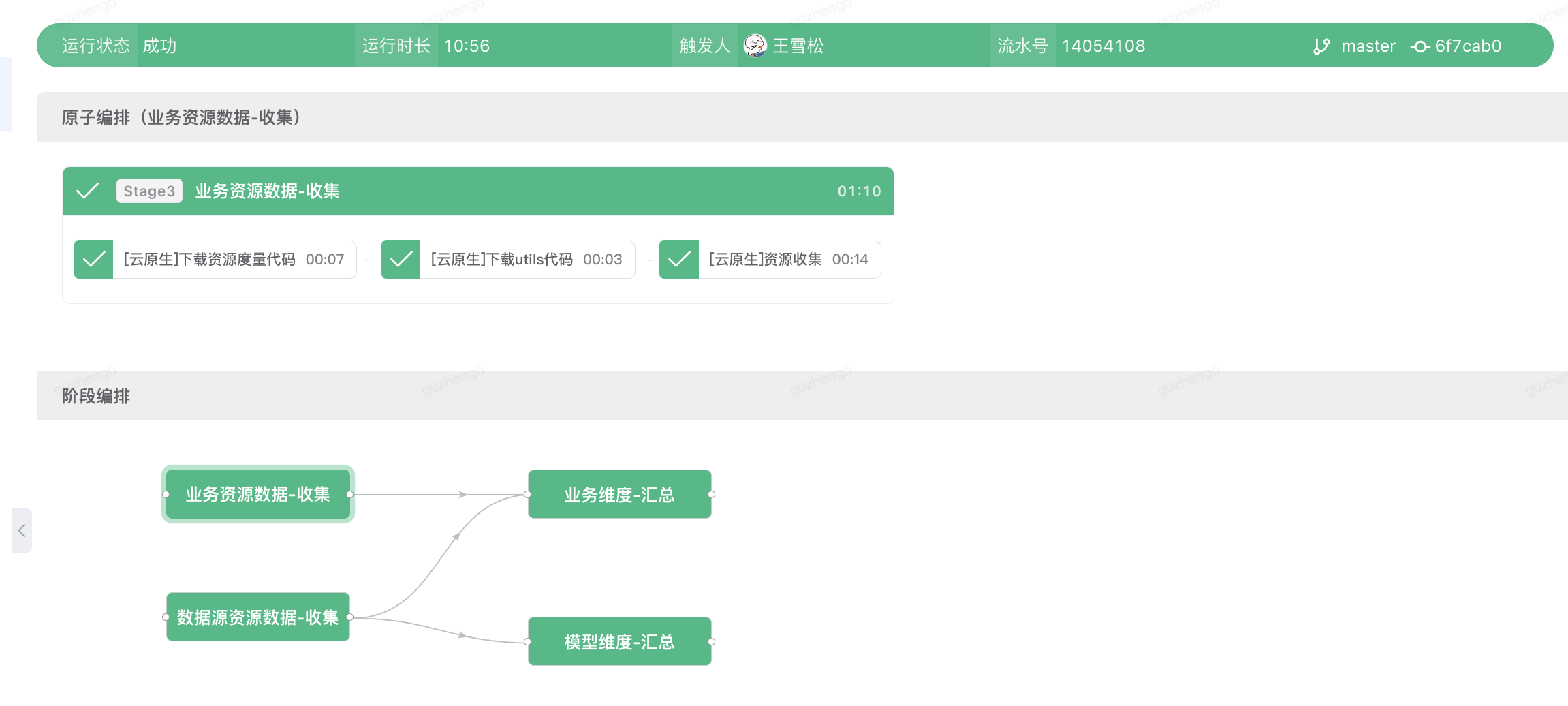
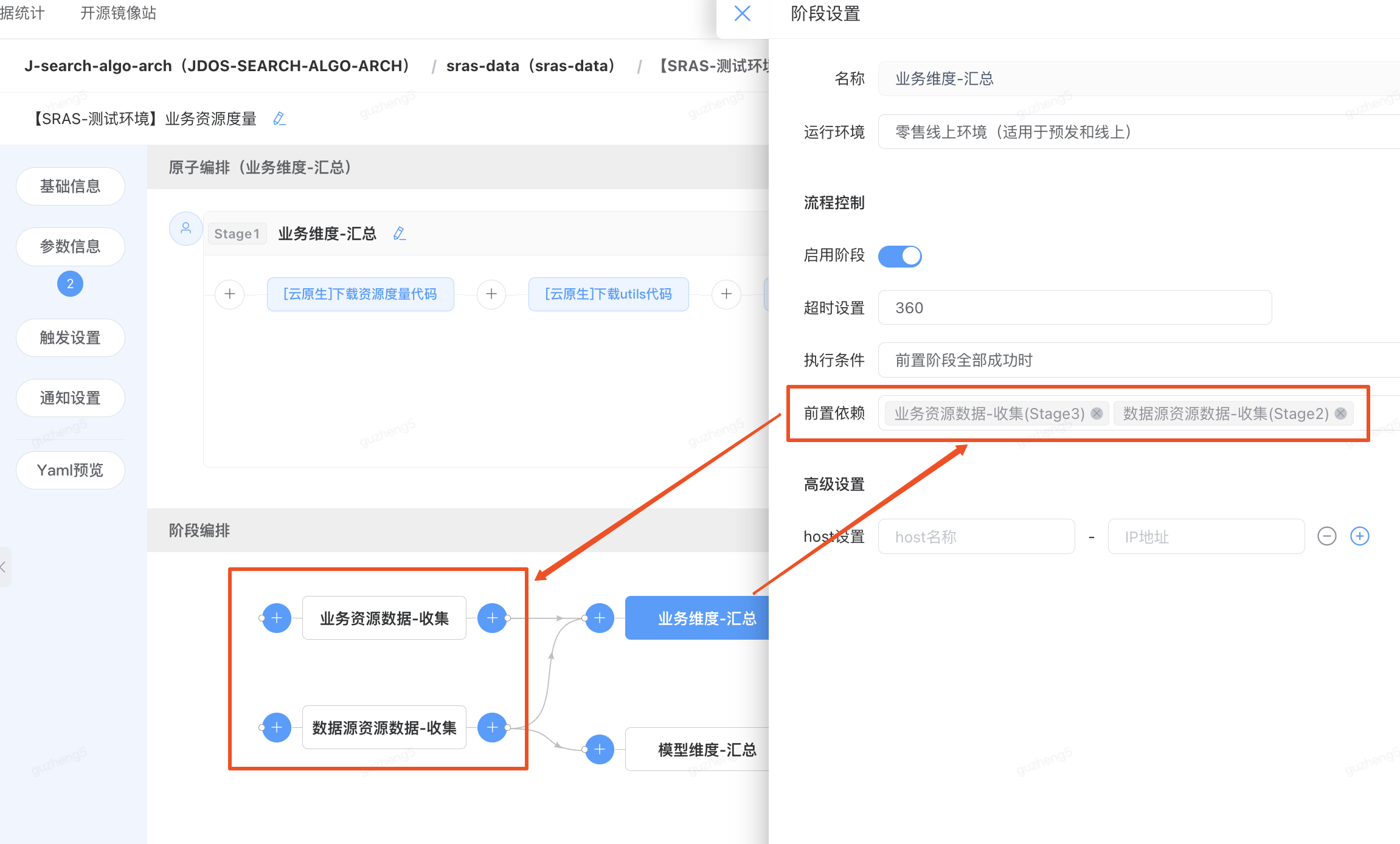
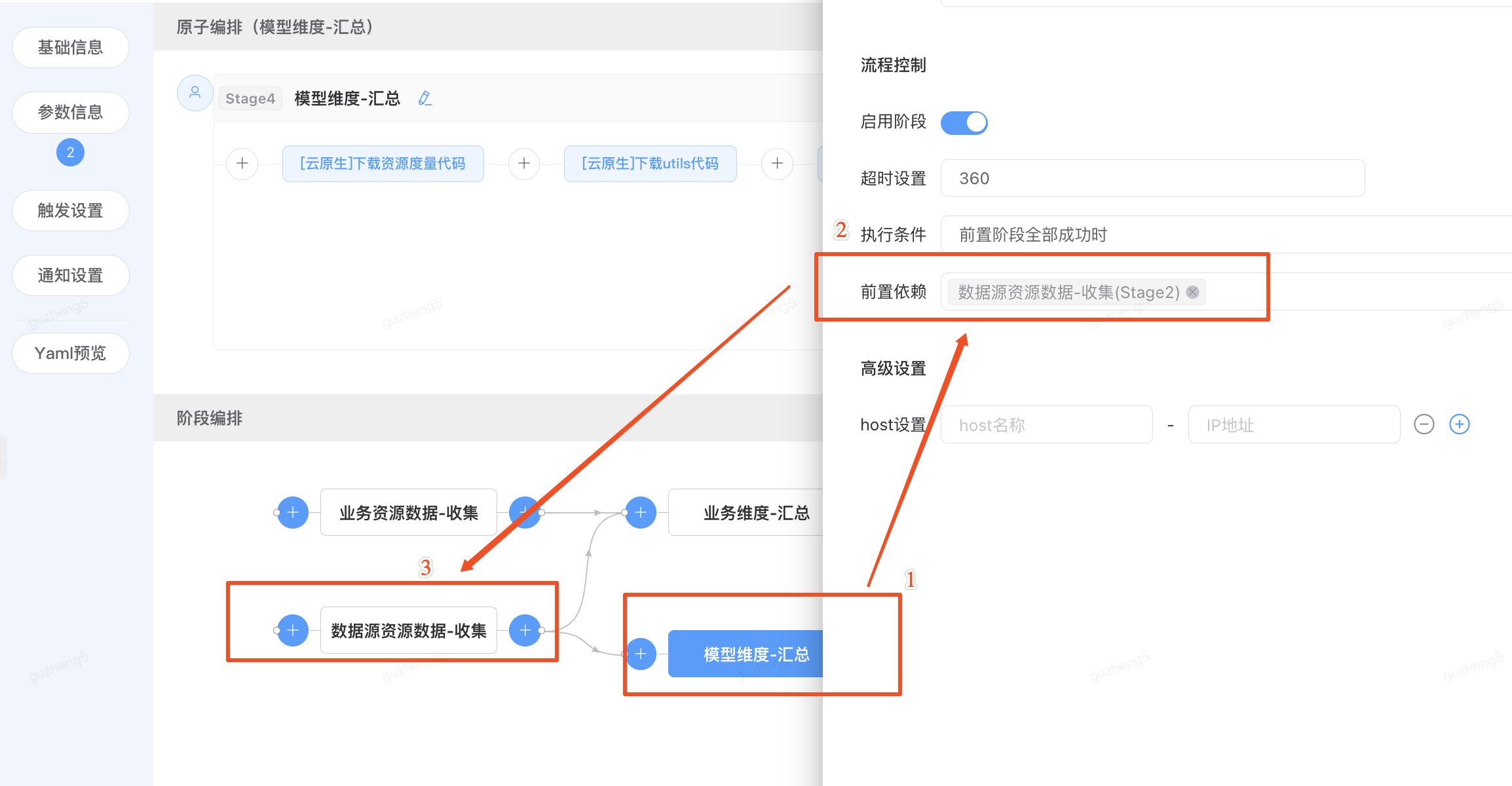
云原生流水线编排功能介绍
入口:流水线列表或流水线构建记录页,点击“配置流水线”

编排界面布局:下方为阶段编排,点击其中一个stage时,上方显示stage内的原子排列顺序

1)添加阶段
图形化的“阶段编排”快速搭建流程,在每个stage的前后分别会有一个“”号,此加号作用是建立前后依赖关系。当点击左侧加号时,添加前置依赖阶段;点击右侧加号时,添加依赖于当前阶段的后续阶段。在点击完成的同时,弹出stage模版(分阶段选择)添加创建。

点击右侧加号,选择开发阶段中的Java单元测试模版
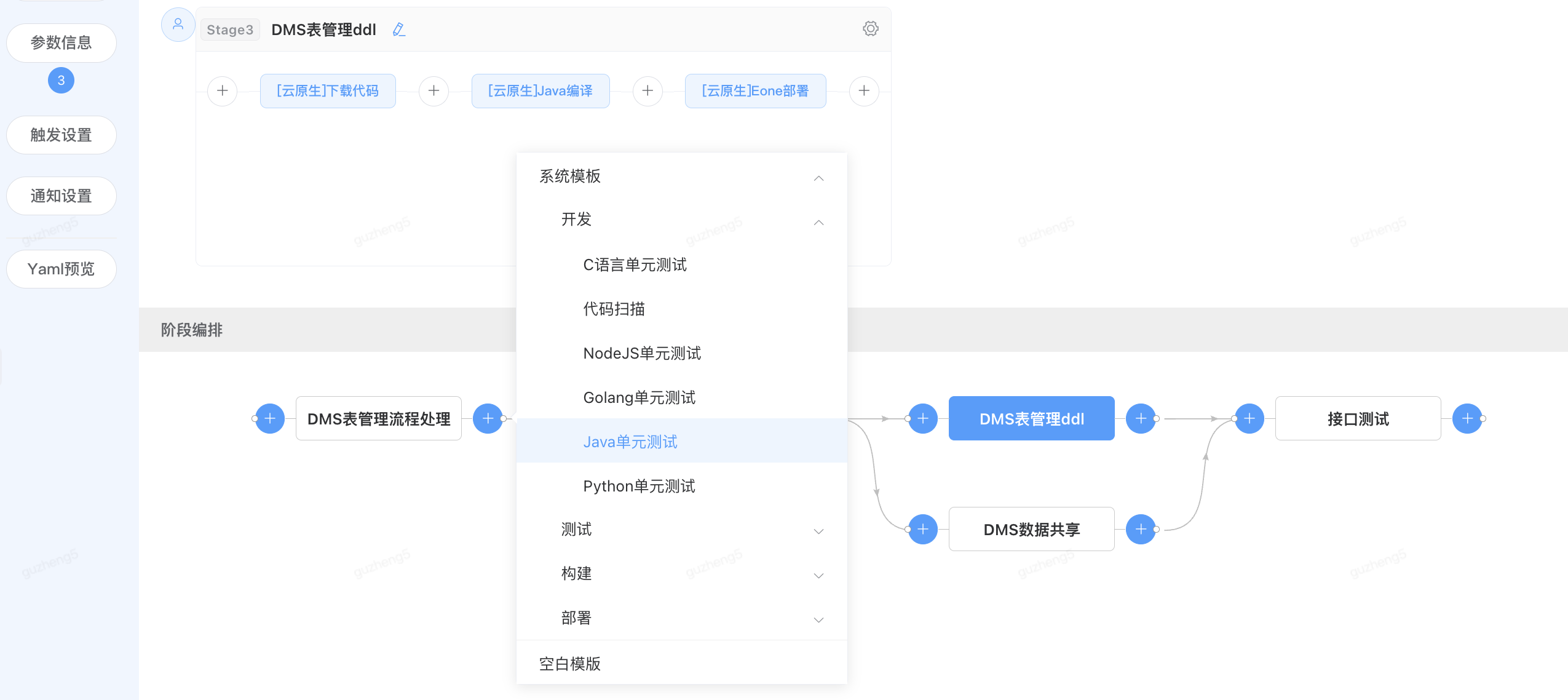
快速添加后续执行阶段,并在上方显示原子编排顺序
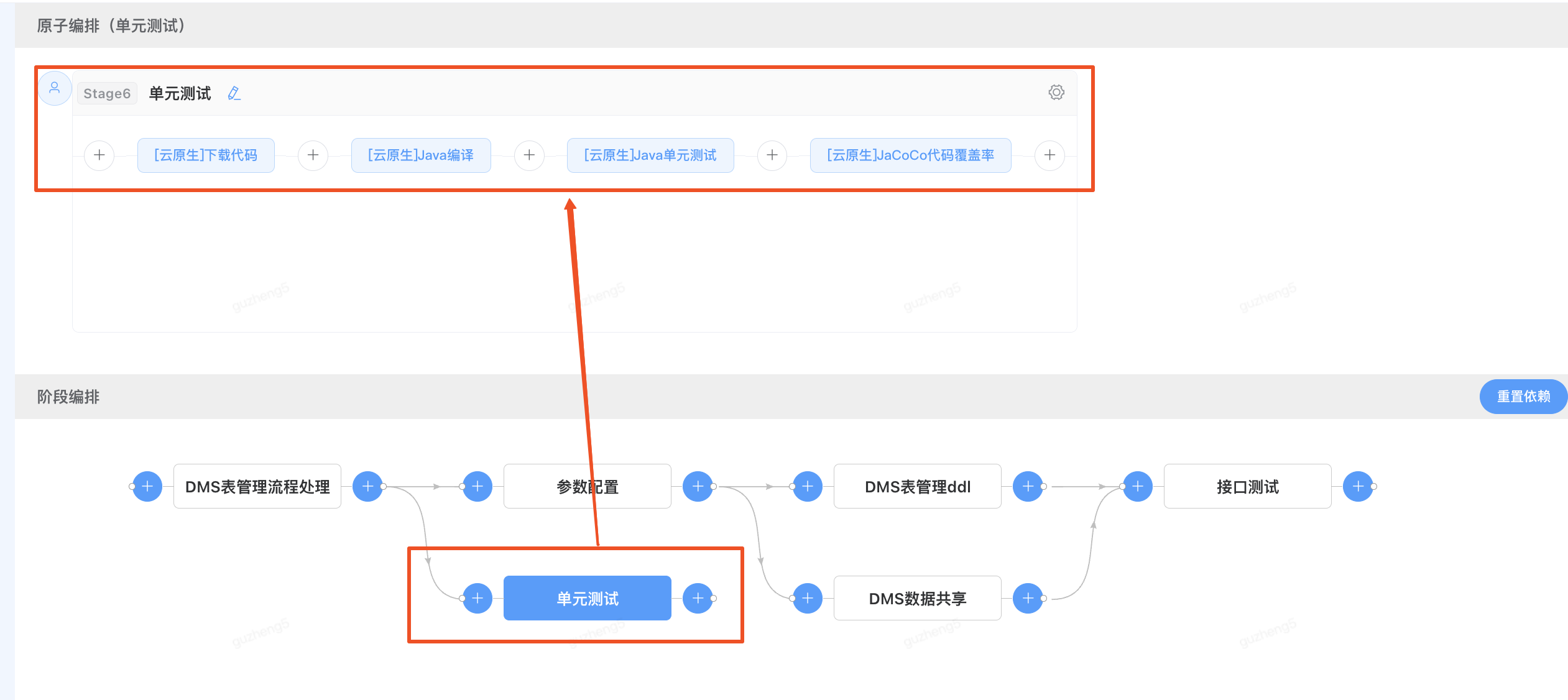
查看单元测试阶段的依赖设置,前置依赖-“DMS表管理流程处理”
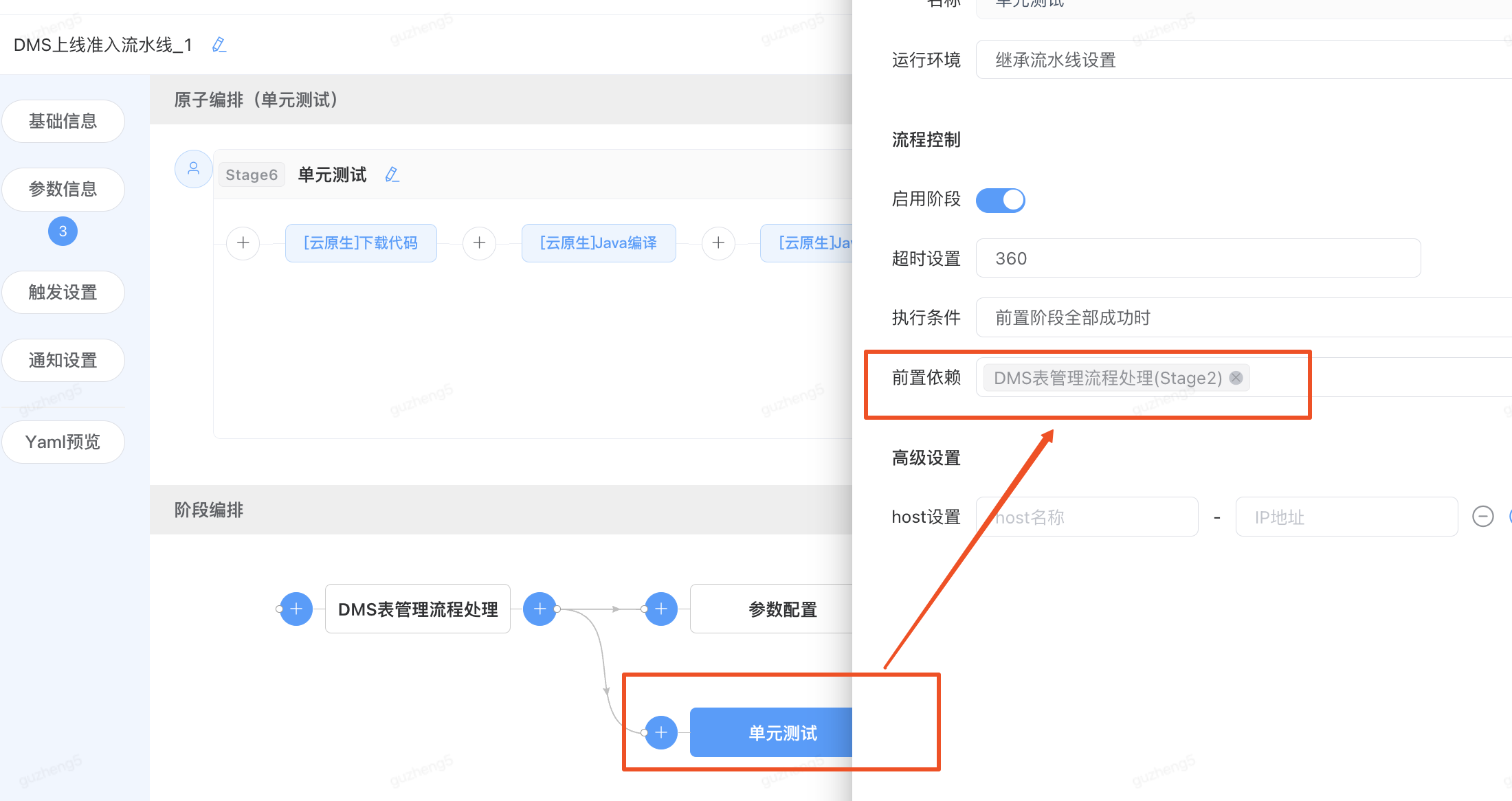
2)调整依赖阶段
当调整“单元测试阶段”到DMS数据共享阶段之后执行
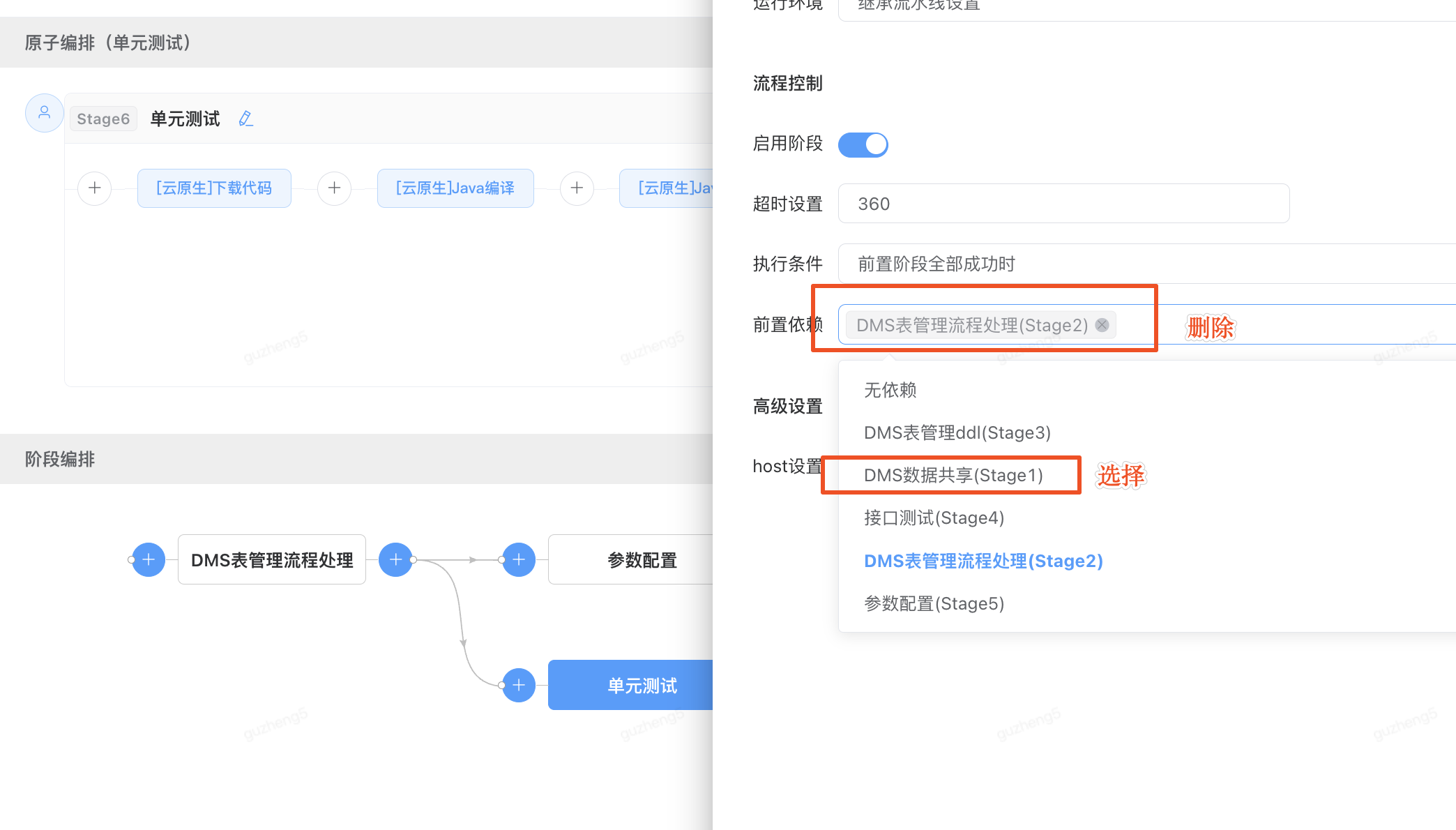
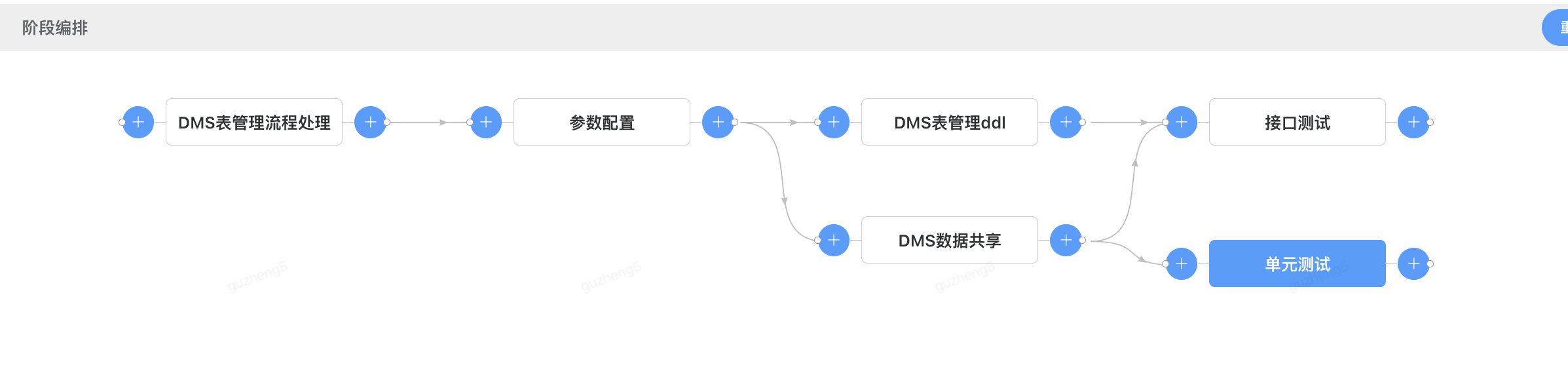
3)删除阶段
stage右上角直接删除并确认

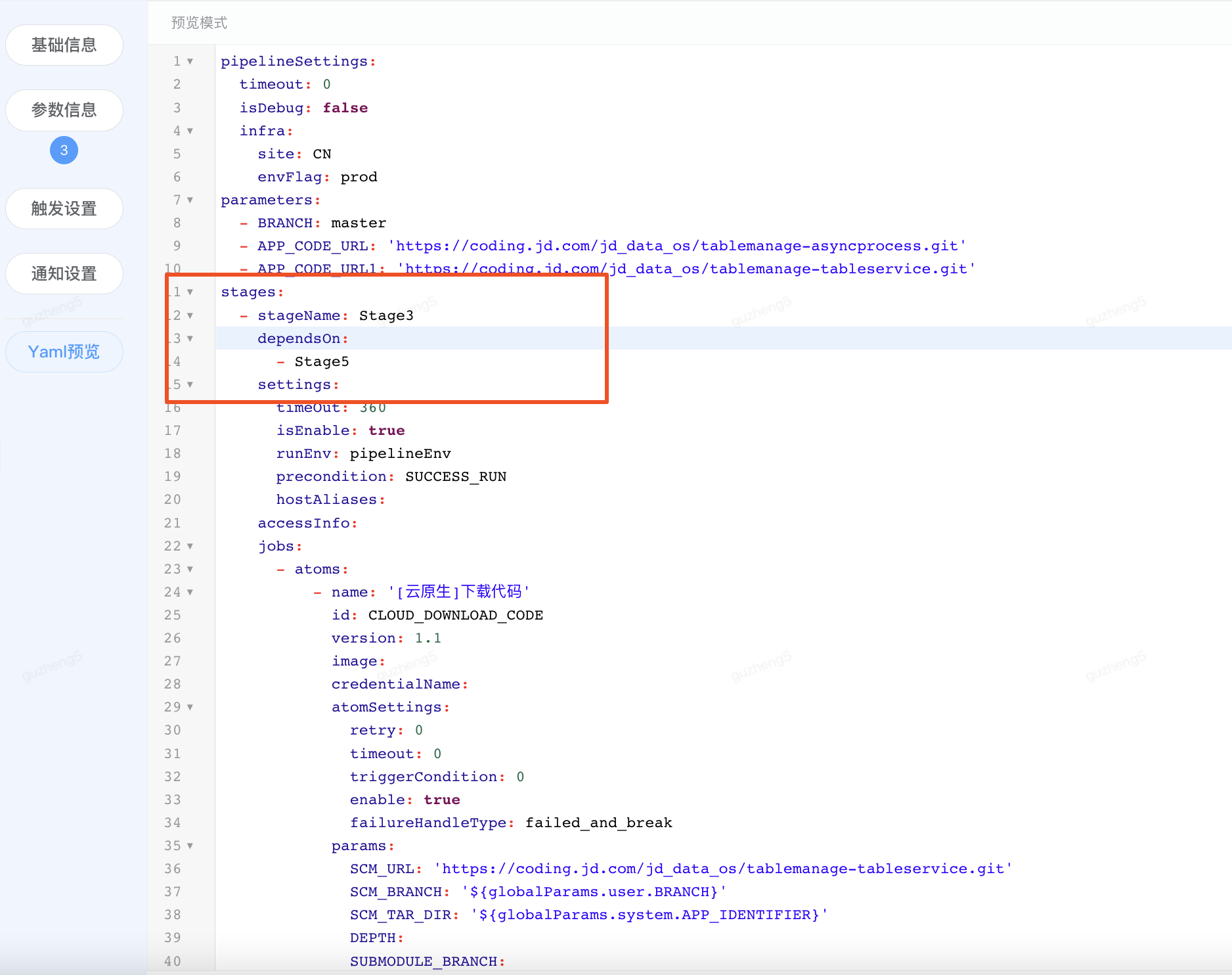
4)Yaml配置中的依赖关系
现阶段开放依赖关系的查看,可通过yaml方式导出创建具备DAG模式的流水线模型,后续将开放编排yaml功能
Q&A
Q:流水线模型的升级与级联流水线冲突吗?
A:不冲突,从能力上看,级联流水线只具备简单的扇出能力,不具备扇入能力,也不具备复杂流程的编排能力。级联流水线更多的是支持通过流水线A触发流水线B的触发模式。级联流水线在配置上,参数传递上都比较复杂,用户使用,大规模应用成本较高。我们希望随着云原生流水线模型的升级,未来逐步替代级联流水线,并支持用户更多场景。
以上介绍了云原生流水线模型升级的价值,解决的问题,用户实践,简单上手操作等。后续随着用户使用场景的增加,我们会持续介绍用户实践,技术探索等等。欢迎大家提出建议或吐槽。
作者:京东零售 顾铮
来源:京东云开发者社区 转载请注明来源
【行云流水线】满足你对工作流编排的一切幻想~skr的更多相关文章
- 云原生流水线 Argo Workflow 的安装、使用以及个人体验
注意:这篇文章并不是一篇入门教程,学习 Argo Workflow 请移步官方文档 Argo Documentation Argo Workflow 是一个云原生工作流引擎,专注于编排并行任务.它的特 ...
- 【敏捷研发系列】前端DevOps流水线实践
作者:胡骏 一.背景现状 软件开发从传统的瀑布流方式到敏捷开发,将软件交付过程中开发和测试形成快速的迭代交付,但在软件交付客户之前或者使用过程中,还包括集成.部署.运维等环节需要进一步优化交付效率.因 ...
- Pipeline流水线设计的最佳实践
谈到到DevOps,持续交付流水线是绕不开的一个话题,相对于其他实践,通过流水线来实现快速高质量的交付价值是相对能快速见效的,特别对于开发测试人员,能够获得实实在在的收益.很多文章介绍流水线,不管是j ...
- 面向多场景而设计的 Erda Pipeline
作者|林俊(万念) 来源|尔达 Erda 公众号 Erda Pipeline 是端点自研.用 Go 编写的一款企业级流水线服务.截至目前,已经为众多行业头部客户提供交付和稳定的服务. 为什么我们坚持自 ...
- 印尼医疗龙头企业Halodoc的数据平台转型之Lakehouse架构
1. 摘要 在 Halodoc,我们始终致力于为最终用户简化医疗保健服务,随着公司的发展,我们不断构建和提供新功能. 我们两年前建立的可能无法支持我们今天管理的数据量,以解决我们决定改进数据平台架构的 ...
- 从函数计算到 Serverless 架构
前言 随着 Serverless 架构的不断发展,各云厂商和开源社区都已经在布局 Serverless 领域,一方面表现在云厂商推出传统服务/业务的 Serverless 化版本,或者 Serverl ...
- Serverless Streaming:毫秒级流式大文件处理探秘
摘要:本文将以图片处理的场景作为例子详细描述当前的问题以及华为云FunctionGraph函数工作流在面对该问题时采取的一系列实践. 文章作者|旧浪:华为云Serverless研发专家.平山:华为云中 ...
- 一文快速了解MaxCompute
很多刚初次接触MaxCompute的用户,面对繁多的产品文档内容以及社区文章,往往很难快速.全面了解MaxCompute产品全貌.同时,很多拥有大数据开发经验的开发者,也希望能够结合自身的背景知识,将 ...
- 轻松构建基于 Serverless 架构的弹性高可用音视频处理系统
前言 随着计算机技术和 Internet 的日新月异,视频点播技术因其良好的人机交互性和流媒体传输技术倍受教育.娱乐等行业青睐,而在当前, 云计算平台厂商的产品线不断成熟完善, 如果想要搭建视频点播类 ...
- 高德最佳实践:Serverless 规模化落地有哪些价值?
作者 | 何以然(以燃) 导读:曾经看上去很美.一直被观望的 Serverless,现已逐渐进入落地的阶段.今年的"十一出行节",高德在核心业务规模化落地 Serverless,由 ...
随机推荐
- 面向对象的Python编程,你需要知道这些!
摘要:Python 没有像 java 中的"private"这样的访问说明符.除了强封装外,它支持大多数与"面向对象"编程语言相关的术语.因此它不是完全面向对象 ...
- 理论+实例,带你掌握Linux的页目录和页表
摘要:操作系统在加载用户程序的时候,不仅仅需要分配物理内存,来存放程序的内容:而且还需要分配物理内存,用来保存程序的页目录和页表. 本文分享自华为云社区<Linux从头学15:[页目录和页表]- ...
- 从“概念”到“应用”,字节跳动基于 DataLeap 的 DataOps 实践
更多技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,回复[1]进入官方交流群 近日,火山引擎数智平台 VeDI Meetup「超话数据」在深圳举办,来自火山引擎的产品专家分享了字节跳动基于 D ...
- 火山引擎DataLeap:3步打造“指标管理”体系,幸福里数据中心是这么做的
更多技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,回复[1]进入官方交流群 一家企业,为什么要搭建指标体系? 一句话总结来说,全面.合理的指标体系可以帮助企业统一目标,将业务环节量化,帮助策 ...
- Solon Web 开发:一、开始
1.第一个Web应用 回顾一下<快速入门>里做过的事情,然后开始我们的第一个web应用 1.1.pom.xml配置 设置solon的parent.这不是必须的,但包含了大量默认的配置,可简 ...
- byte[] 数组,创建的时候赋初始值
C# //创建一个长度为10的byte数组,并且其中每个byte的值为0x08. byte[] myByteArray = Enumerable.Repeat((byte)0x08, 10).ToAr ...
- Intellij idea getter setter 模板设置
通过getter setter 模板设置 在实体类中 自动添加 @XmlTransient 按 [Alt+Insert],弹出的提示中选择 Getter and Setter Xml Entity ...
- MyBatis Mapper.XML 标签使用说明
直接将值返回给对象 <select id="list" resultType="com.vipsoft.base.entity.UserInfo"> ...
- 使用BAPI_NETWORK_COMP_*实现生产订单组件的增删改查
1.文档说明 对于生产订单组件的增删改有多种办法,比较常用的有使用内部函数CO_XT_COMPONENT_*,有改造BAPI_ALM_ORDER_MAINTAIN来实现,各有千秋. 本文档介绍,通过P ...
- #2059:龟兔赛跑(动态规划dp)
Problem Description 据说在很久很久以前,可怜的兔子经历了人生中最大的打击--赛跑输给乌龟后,心中郁闷,发誓要报仇雪恨,于是躲进了杭州下沙某农业园卧薪尝胆潜心修炼,终于练成了绝技,能 ...