Sea-Search03总结&&un finish
使用到的设计模式
Facade门面模式
为何使用?
在搜索项目中,由于使用Mvc架构且数据库中各种不同类型的数据源并没有放在同一张表,于是我们不可避免的在Controller中需要注入多个service,各种service眼花缭乱,而搜索中台提供的内容又及其单一(只负责返回搜索数据),于是采用Facade来统一接口以及装载service
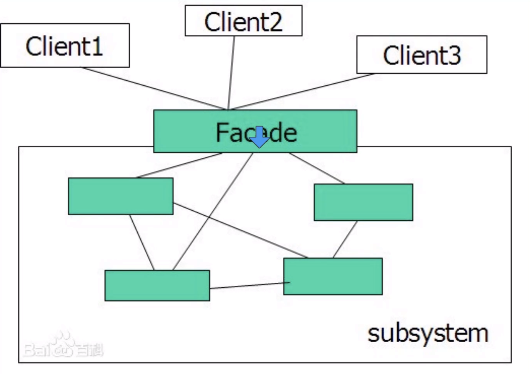
代码呈现
需要注意的是,我们还需要一个统一的return对象(SearchVo),有两种思路:
- SearchVo声明成接口,由其他如PostVo来实现
- 直接聚合:SearchVo聚合各个如PostVo的内容(对于内容我们也可采用抽象类来实现)等
@Component
public class SearchFacade {
@Autowired
private PictureService pictureService;
@Autowired
private PostService postService;
@Autowired
private UserService userService;
@Autowired
private DataSourceRegistry dataSourceRegistry;
public SearchVo getAll(SearchQueryRequest searchQueryRequest, HttpServletRequest request) {
long current = searchQueryRequest.getCurrent();
long size = searchQueryRequest.getPageSize();
String searchText = searchQueryRequest.getSearchText();
String type = searchQueryRequest.getType();
SearchTypeEnum searchTypeEnum = SearchTypeEnum.getEnumByValue(type);
ThrowUtils.throwIf(type != null && StringUtils.isBlank(type), ErrorCode.PARAMS_ERROR);
SearchVo searchVo = new SearchVo();
if (searchTypeEnum == null) {
CompletableFuture<Void> picCF = CompletableFuture.runAsync(() -> {
List<Picture> pictures = pictureService.searchPicture(searchQueryRequest.getSearchText(), searchQueryRequest.getCurrent(), searchQueryRequest.getPageSize());
searchVo.setPicList(pictures);
});
CompletableFuture<Void> userCF = CompletableFuture.runAsync(() -> {
UserQueryRequest userQueryRequest = new UserQueryRequest();
userQueryRequest.setUserName(searchText);
userQueryRequest.setCurrent(current);
userQueryRequest.setPageSize(size);
Page<UserVO> userVOPage = userService.listUserVoByPage(userQueryRequest);
searchVo.setUserList(userVOPage.getRecords());
});
CompletableFuture<Void> postCF = CompletableFuture.runAsync(() -> {
PostQueryRequest postQueryRequest = new PostQueryRequest();
postQueryRequest.setSearchText(searchText);
postQueryRequest.setCurrent(current);
postQueryRequest.setPageSize(size);
Page<PostVO> postPage = postService.listPostVOByPage(postQueryRequest, request);
searchVo.setPostList(postPage.getRecords());
});
try {
CompletableFuture.allOf(postCF, userCF, picCF).get();
} catch (Exception e) {
throw new BusinessException(ErrorCode.SYSTEM_ERROR, "查询数据异常");
}
} else {
DataSource dataSource = dataSourceRegistry.dataSourceMap.get(type);
List<?> list = dataSource.doSearch(searchText, current, size);
searchVo.setDataList(list);
}
return searchVo;
}
}
tips:
这里的真实有效的仅有dataList(其他三个是第二版的残留物)
/**
* @author:天才玩家M
* @date:2023/10/4 11:32
* @description:TODO
*/
@Data
public class SearchVo {
private List<Picture> picList;
private List<PostVO> postList;
private List<UserVO> userList;
private List<?> dataList;
}
适配器模式
为何使用?:
搜索中台中,我们之后可能会接入各种各样的type的搜索数据源,比如说我自己,有时候,几乎是同样功能的service只是数据源不一样,不复制粘贴就常常弄得各有各的接口,就很乱,所以出现了适配器模式,一方面,如果这个service不是我们写的,我们在其之后写,可以利用适配器尝试将对方改为我们的适配的api,或者我们先定了适配器,让对方按照我们的标准来实现
public interface DataSource<T> {
List<T> doSearch(String searchText,Long current,Long pageSize);
}
其他数据源:
public class PostDataSource implements DataSource<PostVO>{...}
注册器模式
为何使用?
承接上面的门面,以及适配器,在实际场景中我们肯定要根据不同的searchType更换,那么用switch?
太复杂了,那用一个map封装一下,之后get,差不多,这可大大节省了代码量
@Component
public class DataSourceRegistry {
public Map<String,DataSource> dataSourceMap=null;
@PostConstruct
public void initMap(){
dataSourceMap=new HashMap();
dataSourceMap.put(SearchTypeEnum.POST.getValue(),new PostDataSource());
dataSourceMap.put(SearchTypeEnum.PICTURE.getValue(),new PictureDataSource());
dataSourceMap.put(SearchTypeEnum.USER.getValue(),new UserDataSource());
}
}
ES的概念
倒排索引
正向索引:字典or通常书籍的目录
倒排索引:
输入数据时
会根据我们输入es的内容,先分词,然后统计哪个分词在哪个doc出现过,通过内容来检索到哪个doc
查找数据时
同样会通过分词,然后根据总共分词在哪些doc出现过,返回对应的数据
用户搜:“鱼皮rapper”
ES 先切词:鱼皮,rapper
去倒排索引表找对饮的文章:文章A,B
| 词 | 内容 id |
|---|---|
| 你好 | 文章A,B |
| 我是 | 文章A,B |
| rapper | 文章A |
| 鱼皮 | 文章B |
| coder | 文章B |
一个待升级点
es会通过我们输入的searchText来分词然后返回docs,这些doc同时带有一定的评分,我们可以通过这些评分来倒序返回给用户,实现对应的功能
(类似:百度:查找的时候第一页的内容和我们搜索的相关性较高(抛开广告不谈的话),之后相关性逐渐降低)
待解决点:
page改成cur_point
能够优化ES性能
尤其是像我们手机电商这种页码不明显的情况下,当然明显也能替换
Sea-Search03总结&&un finish的更多相关文章
- sea.js模块化编程
* 为什么要模块化? 解决文件依赖 解决命名冲突 ; var var2 = 2; function fn1(){ } function fn2(){ } return { fn1: fn1, fn2: ...
- 【Codeforces 738D】Sea Battle(贪心)
http://codeforces.com/contest/738/problem/D Galya is playing one-dimensional Sea Battle on a 1 × n g ...
- 在eclipse创建android project,最后一步点击finish没反应
在创建android project的时候,到最后一步点击finish没有反应. 本来以为可能是SDK中的Extra下Android Support Library没有安装,后来检查发现Minimum ...
- 解决sea.js引用jQuery提示$ is not a function的问题
在使用sea.js的如下写法引用jQuery文件时, //main.jsdefine(function(require,exports,module){ var $ = require('jquery ...
- Android中finish掉其它的Activity
在Android开发时,一般情况下我们如果需要关掉当前Activity非常容易,只需要一行代码 this.finish;即可.那么,如果是想要在当前Activity中关掉其它的Activity应该怎么 ...
- finish()在dialog中的作用
finish()在dialog中销毁的是dialog所在的活动:
- 模块化开发--sea.js
当你的网站开发越来越复杂的时候,会经常遇到一下问题吗?1.冲突2.性能3.依赖如果在多人开发或者是复杂的开发过程中会经常遇到这些问 题,就可以用模块化开发来解决.以上问题是如何产生的?1.冲突:如果你 ...
- sea.js 入门
上个月学了 require.js 现在顺便来学学 sea.js. 对比下这两种的区别,看自己喜欢哪个,就在接下来的项目中去使用它吧. seajs中的所有 JavaScript 模块都遵循 CMD 模块 ...
- 第三课:sea.js模块加载原理
模块加载,其实就是把js分成很多个模块,便于开发和维护.因此加载很多js模块的时候,需要动态的加载,以便提高用户体验. 在介绍模块加载库之前,先介绍一个方法. 动态加载js方法: function l ...
- Codeforces 738D. Sea Battle 模拟
D. Sea Battle time limit per test: 1 second memory limit per test :256 megabytes input: standard inp ...
随机推荐
- 在Winform系统开发中,对表格列表中的内容进行分组展示
在我们开发Winform界面的时候,有时候会遇到需要对一些字段进行一些汇总的管理,如果在列表中能够对表格列表中的内容进行分组展示,将比较符合我们的预期,本篇随笔介绍在Winform开发中如何利用Dev ...
- rabbitMq消息持久化机制,和延时队列
1.RabbitMQ的一大特色是消息的可靠性,那么它是如何保证消息可靠性的呢? 消息持久化.可以将Queue,Exchange,Message都设置为可持久化的.为了保证RabbitMQ在退出,服务重 ...
- C#利用控件实现柱形图分析
数据 { using (SqlConnection con = new SqlConnection("server=.;uid=sa;pwd=;database=db_TomeOne&quo ...
- 简化 libevent 编译
在 CMakePresets.json 的 cacheVariables 字段加入 { "EVENT__DISABLE_OPENSSL": "ON", &quo ...
- python json.loads()、json.dumps()和json.dump()、json.load()区别
json.loads().json.dumps()和json.dump().json.load()分别是两组不同用法 带s的用于数据类型的转换,不带s的用于操作文件. json.loads().jso ...
- Nacos源码 (7) Nacos与Spring
SpringCloud工程可以使用Nacos作为注册中心和配置中心,配置和使用非常简单,本文将简单介绍使用方式,并分析其实现方式. SpringCloud工程集成Nacos SpringCloud工程 ...
- 选择DOM中除一个元素以外的所有元素[Jquery]
$(function(){ $('body > *').not('#myDiv') .on('mouseover', function(){ //... }) .on('click', func ...
- grpc-环境与示例
1. 数据传输基本原理 2. grpc环境安装 代码生成器 go get -u github.com/golang/protobuf/protoc-gen-go // 会自动在 $GOPATH/bin ...
- [转帖]jmeter编写测试脚本大全
目录 一.背景 二.按照功能划分 2.1 加密处理.验签处理 2.2 jmeter 使用beanshell 编写脚本 2.3 jmeter脚本报错大全 2.4 jmeter打印log 2.5 jmet ...
- 银河麒麟不同架构获取rpm包的方法
银河麒麟不同架构获取rpm包的方法 背景 随着信创和网络安全越来越重要 现阶段国产化的软硬件部署越来越多. 很多时候现场有很多国产化的设备.不同架构.不同版本. 还不能上网, 无法获取对应的安装介质. ...