如何用ReadWriteLock实现一个通用的缓存中心?
摘要:在并发场景中,Java SDK中提供了ReadWriteLock来满足读多写少的场景。
本文分享自华为云社区《【高并发】基于ReadWriteLock开了个一款高性能缓存》,作者:冰 河。
写在前面
在实际工作中,有一种非常普遍的并发场景:那就是读多写少的场景。在这种场景下,为了优化程序的性能,我们经常使用缓存来提高应用的访问性能。因为缓存非常适合使用在读多写少的场景中。而在并发场景中,Java SDK中提供了ReadWriteLock来满足读多写少的场景。本文我们就来说说使用ReadWriteLock如何实现一个通用的缓存中心。
本文涉及的知识点有:

读写锁
说起读写锁,相信小伙伴们并不陌生。总体来说,读写锁需要遵循以下原则:
- 一个共享变量允许同时被多个读线程读取到。
- 一个共享变量在同一时刻只能被一个写线程进行写操作。
- 一个共享变量在被写线程执行写操作时,此时这个共享变量不能被读线程执行读操作。
这里,需要小伙伴们注意的是:读写锁和互斥锁的一个重要的区别就是:读写锁允许多个线程同时读共享变量,而互斥锁不允许。所以,在高并发场景下,读写锁的性能要高于互斥锁。但是,读写锁的写操作是互斥的,也就是说,使用读写锁时,一个共享变量在被写线程执行写操作时,此时这个共享变量不能被读线程执行读操作。
读写锁支持公平模式和非公平模式,具体是在ReentrantReadWriteLock的构造方法中传递一个boolean类型的变量来控制。
public ReentrantReadWriteLock(boolean fair) {
sync = fair ? new FairSync() : new NonfairSync();
readerLock = new ReadLock(this);
writerLock = new WriteLock(this);
}
另外,需要注意的一点是:在读写锁中,读锁调用newCondition()会抛出UnsupportedOperationException异常,也就是说:读锁不支持条件变量。
缓存实现
这里,我们使用ReadWriteLock快速实现一个缓存的通用工具类,总体代码如下所示。
public class ReadWriteLockCache<K,V> {
private final Map<K, V> m = new HashMap<>();
private final ReadWriteLock rwl = new ReentrantReadWriteLock();
// 读锁
private final Lock r = rwl.readLock();
// 写锁
private final Lock w = rwl.writeLock();
// 读缓存
public V get(K key) {
r.lock();
try { return m.get(key); }
finally { r.unlock(); }
}
// 写缓存
public V put(K key, V value) {
w.lock();
try { return m.put(key, value); }
finally { w.unlock(); }
}
}
可以看到,在ReadWriteLockCache中,我们定义了两个泛型类型,K代表缓存的Key,V代表缓存的value。在ReadWriteLockCache类的内部,我们使用Map来缓存相应的数据,小伙伴都都知道HashMap并不是线程安全的类,所以,这里使用了读写锁来保证线程的安全性,例如,我们在get()方法中使用了读锁,get()方法可以被多个线程同时执行读操作;put()方法内部使用写锁,也就是说,put()方法在同一时刻只能有一个线程对缓存进行写操作。
这里需要注意的是:无论是读锁还是写锁,锁的释放操作都需要放到finally{}代码块中。
在以往的经验中,有两种向缓存中加载数据的方式,一种是:项目启动时,将数据全量加载到缓存中,一种是在项目运行期间,按需加载所需要的缓存数据。
接下来,我们就分别来看看全量加载缓存和按需加载缓存的方式。
全量加载缓存
全量加载缓存相对来说比较简单,就是在项目启动的时候,将数据一次性加载到缓存中,这种情况适用于缓存数据量不大,数据变动不频繁的场景,例如:可以缓存一些系统中的数据字典等信息。整个缓存加载的大体流程如下所示。
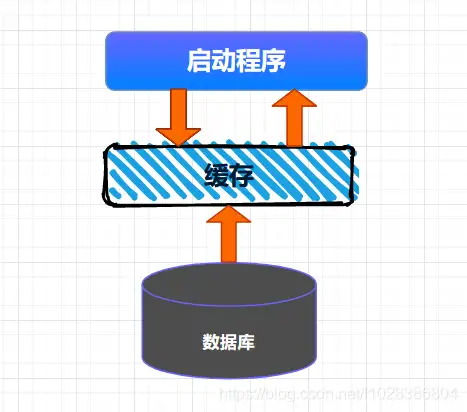
将数据全量加载到缓存后,后续就可以直接从缓存中读取相应的数据了。
全量加载缓存的代码实现比较简单,这里,我就直接使用如下代码进行演示。
public class ReadWriteLockCache<K,V> {
private final Map<K, V> m = new HashMap<>();
private final ReadWriteLock rwl = new ReentrantReadWriteLock();
// 读锁
private final Lock r = rwl.readLock();
// 写锁
private final Lock w = rwl.writeLock();
public ReadWriteLockCache(){
//查询数据库
List<Field<K, V>> list = .....;
if(!CollectionUtils.isEmpty(list)){
list.parallelStream().forEach((f) ->{
m.put(f.getK(), f.getV);
});
}
}
// 读缓存
public V get(K key) {
r.lock();
try { return m.get(key); }
finally { r.unlock(); }
}
// 写缓存
public V put(K key, V value) {
w.lock();
try { return m.put(key, value); }
finally { w.unlock(); }
}
}
按需加载缓存
按需加载缓存也可以叫作懒加载,就是说:需要加载的时候才会将数据加载到缓存。具体来说:就是程序启动的时候,不会将数据加载到缓存,当运行时,需要查询某些数据,首先检测缓存中是否存在需要的数据,如果存在,则直接读取缓存中的数据,如果不存在,则到数据库中查询数据,并将数据写入缓存。后续的读取操作,因为缓存中已经存在了相应的数据,直接返回缓存的数据即可。
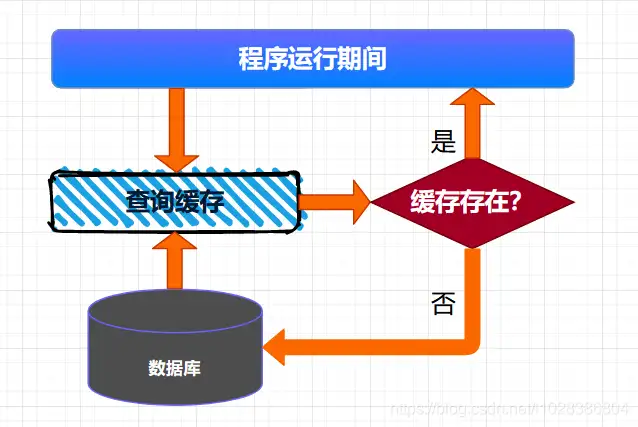
这种查询缓存的方式适用于大多数缓存数据的场景。
我们可以使用如下代码来表示按需查询缓存的业务。
class ReadWriteLockCache<K,V> {
private final Map<K, V> m = new HashMap<>();
private final ReadWriteLock rwl = new ReentrantReadWriteLock();
private final Lock r = rwl.readLock();
private final Lock w = rwl.writeLock();
V get(K key) {
V v = null;
//读缓存
r.lock();
try {
v = m.get(key);
} finally{
r.unlock();
}
//缓存中存在,返回
if(v != null) {
return v;
}
//缓存中不存在,查询数据库
w.lock();
try {
//再次验证缓存中是否存在数据
v = m.get(key);
if(v == null){
//查询数据库
v=从数据库中查询出来的数据
m.put(key, v);
}
} finally{
w.unlock();
}
return v;
}
}
这里,在get()方法中,首先从缓存中读取数据,此时,我们对查询缓存的操作添加了读锁,查询返回后,进行解锁操作。判断缓存中返回的数据是否为空,不为空,则直接返回数据;如果为空,则获取写锁,之后再次从缓存中读取数据,如果缓存中不存在数据,则查询数据库,将结果数据写入缓存,释放写锁。最终返回结果数据。
这里,有小伙伴可能会问:为啥程序都已经添加写锁了,在写锁内部为啥还要查询一次缓存呢?
这是因为在高并发的场景下,可能会存在多个线程来竞争写锁的现象。例如:第一次执行get()方法时,缓存中的数据为空。如果此时有三个线程同时调用get()方法,同时运行到 w.lock()代码处,由于写锁的排他性。此时只有一个线程会获取到写锁,其他两个线程则阻塞在w.lock()处。获取到写锁的线程继续往下执行查询数据库,将数据写入缓存,之后释放写锁。
此时,另外两个线程竞争写锁,某个线程会获取到锁,继续往下执行,如果在w.lock()后没有v = m.get(key); 再次查询缓存的数据,则这个线程会直接查询数据库,将数据写入缓存后释放写锁。最后一个线程同样会按照这个流程执行。
这里,实际上第一个线程已经查询过数据库,并且将数据写入缓存了,其他两个线程就没必要再次查询数据库了,直接从缓存中查询出相应的数据即可。所以,在w.lock()后添加v = m.get(key); 再次查询缓存的数据,能够有效的减少高并发场景下重复查询数据库的问题,提升系统的性能。
读写锁的升降级
关于锁的升降级,小伙伴们需要注意的是:在ReadWriteLock中,锁是不支持升级的,因为读锁还未释放时,此时获取写锁,就会导致写锁永久等待,相应的线程也会被阻塞而无法唤醒。
虽然不支持锁升级,但是ReadWriteLock支持锁降级,例如,我们来看看官方的ReentrantReadWriteLock示例,如下所示。
class CachedData {
Object data;
volatile boolean cacheValid;
final ReentrantReadWriteLock rwl = new ReentrantReadWriteLock();
void processCachedData() {
rwl.readLock().lock();
if (!cacheValid) {
// Must release read lock before acquiring write lock
rwl.readLock().unlock();
rwl.writeLock().lock();
try {
// Recheck state because another thread might have
// acquired write lock and changed state before we did.
if (!cacheValid) {
data = ...
cacheValid = true;
}
// Downgrade by acquiring read lock before releasing write lock
rwl.readLock().lock();
} finally {
rwl.writeLock().unlock(); // Unlock write, still hold read
}
}
try {
use(data);
} finally {
rwl.readLock().unlock();
}
}
}}
数据同步问题
首先,这里说的数据同步指的是数据源和数据缓存之间的数据同步,说的再直接一点,就是数据库和缓存之间的数据同步。
这里,我们可以采取三种方案来解决数据同步的问题,如下图所示
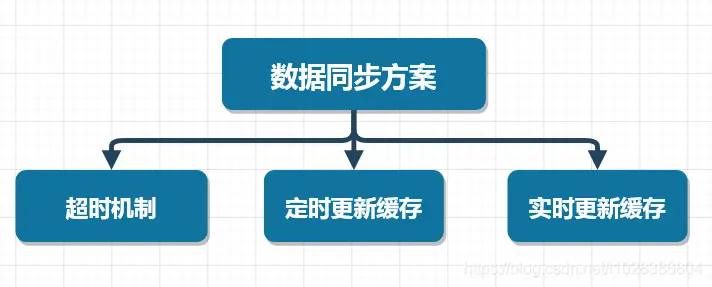
超时机制
这个比较好理解,就是在向缓存写入数据的时候,给一个超时时间,当缓存超时后,缓存的数据会自动从缓存中移除,此时程序再次访问缓存时,由于缓存中不存在相应的数据,查询数据库得到数据后,再将数据写入缓存。
定时更新缓存
这种方案是超时机制的增强版,在向缓存中写入数据的时候,同样给一个超时时间。与超时机制不同的是,在程序后台单独启动一个线程,定时查询数据库中的数据,然后将数据写入缓存中,这样能够在一定程度上避免缓存的穿透问题。
如何用ReadWriteLock实现一个通用的缓存中心?的更多相关文章
- 原来ReadWriteLock也能开发高性能缓存,看完我也能和面试官好好聊聊了!
大家好,我是冰河~~ 在实际工作中,有一种非常普遍的并发场景:那就是读多写少的场景.在这种场景下,为了优化程序的性能,我们经常使用缓存来提高应用的访问性能.因为缓存非常适合使用在读多写少的场景中.而在 ...
- 用Java实现一个通用并发对象池
这篇文章里我们主要讨论下如何在Java里实现一个对象池.最近几年,Java虚拟机的性能在各方面都得到了极大的提升,因此对大多数对象而言,已经没有必要通过对象池来提高性能了.根本的原因是,创建一个新的对 ...
- 基于.net的通用内存缓存模型组件
谈到缓存,我们自然而然就会想到缓存的好处,比如: 降低高并发数据读取的系统压力:静态数据访问.动态数据访问 存储预处理数据,提升系统响应速度和TPS 降低高并发数据写入的系统压力 提升系统可用性,后台 ...
- iOS开发:代码通用性以及其规范 第二篇(猜想iOS中实现TableView内部设计思路(附代码),以类似的思想实现一个通用的进度条)
在iOS开发中,经常是要用到UITableView的,我曾经思考过这样一个问题,为什么任何种类的model放到TableView和所需的cell里面,都可以正常显示?而我自己写的很多view却只是能放 ...
- 基于.net的分布式系统限流组件 C# DataGridView绑定List对象时,利用BindingList来实现增删查改 .net中ThreadPool与Task的认识总结 C# 排序技术研究与对比 基于.net的通用内存缓存模型组件 Scala学习笔记:重要语法特性
基于.net的分布式系统限流组件 在互联网应用中,流量洪峰是常有的事情.在应对流量洪峰时,通用的处理模式一般有排队.限流,这样可以非常直接有效的保护系统,防止系统被打爆.另外,通过限流技术手段,可 ...
- IEditableObject的一个通用实现
原文:IEditableObject的一个通用实现 IeditableObject是一个通用接口,用于支持对象编辑.当我们在界面上选择一个条目,然后对其进行编辑的时候,接下来会有两种操作,一个是保持编 ...
- 在Dynamics CRM中自定义一个通用的查看编辑注释页面
关注本人微信和易信公众号: 微软动态CRM专家罗勇 ,回复162或者20151016可方便获取本文,同时可以在第一时间得到我发布的最新的博文信息,follow me! 注释在CRM中的显示是比较特别, ...
- 哪种缓存效果高?开源一个简单的缓存组件j2cache
背景 现在的web系统已经越来越多的应用缓存技术,而且缓存技术确实是能实足的增强系统性能的.我在项目中也开始接触一些缓存的需求. 开始简单的就用jvm(java托管内存)来做缓存,这样对于单个应用服务 ...
- 编写一个通用的Makefile文件
1.1在这之前,我们需要了解程序的编译过程 a.预处理:检查语法错误,展开宏,包含头文件等 b.编译:*.c-->*.S c.汇编:*.S-->*.o d.链接:.o +库文件=*.exe ...
- Linux C编程学习之开发工具3---多文件项目管理、Makefile、一个通用的Makefile
GNU Make简介 大型项目的开发过程中,往往会划分出若干个功能模块,这样可以保证软件的易维护性. 作为项目的组成部分,各个模块不可避免的存在各种联系,如果其中某个模块发生改动,那么其他的模块需要相 ...
随机推荐
- Agora 教程丨一个典型案例,教你如何使用水晶球“数据洞察”
7 月初,声网Agora 水晶球的"数据洞察"功能正式版上线."数据洞察"可显示两种数据,一种是用量,另一种是质量. "数据洞察"的&quo ...
- 一站式微服务治理中台,Water v2.10.2 发布
Water(水孕育万物...) Water 为项目开发.服务治理,提供一站式解决方案(可以理解为微服务架构支持套件).基于 Solon 框架开发,并支持完整的 Solon Cloud 规范:已在生产环 ...
- ABAP 屏幕开发-仿采购订单
1.功能说明 本文档通过一个简单的实例,仿照采购订单的界面,介绍屏幕开发. 2.效果展示 3.功能实现 3.1界面框架 从界面上看,整个界面框架分为四部分.抬头行,抬头页签,行项目,项目细节.其中抬头 ...
- 发布新版博客备份功能:生成 sqlite 数据库文件,vscode 插件可查看
大家好,最近我们重新开发了园子的博客备份功能,今天发布第一个预览版,欢迎大家试用. 点击博客后台侧边栏的博客备份进入新版博客备份: 点击创建备份按钮创建博客备份任务(目前每天只能创建一次备份),待备份 ...
- JUC——CountDownLatch/CyclicBarrier/Semaphore
系统性学习,异步IT-BLOG CountDownLatch 是一个同步工具类,用来协调多个线程之间的同步,或者说起到线程之间的通信(而不是用作互斥的作用).CountDownLatch 能够使一个线 ...
- asp.net 应用程序中同步方法调用异步方法无响应解决方法
微软发布 C# async/await 异步语法功能已经好久了,但是目前来看使用并不广泛.本人经过实践在开发过程中使用 async/await 一路到底确实很爽,而且也没有啥问题.但是在面对旧项目变更 ...
- python入门教程之二十二网络编程
Python 提供了两个级别访问的网络服务.: 低级别的网络服务支持基本的 Socket,它提供了标准的 BSD Sockets API,可以访问底层操作系统Socket接口的全部方法. 高级别的网络 ...
- 五月十一号java基础知识点
1.通过add()方法向链表list输入1-10十个数for (int i = 1; i <11 ; i++) { list.add(i);//向链表添加1-10的整数 } import jav ...
- 听说你想用免费的FOFA?(第二弹)
听说你想用免费的FOFA?(第二弹) 上回说到 听说你想用免费的FOFA? 第二弹 记得那是一个阳光正好的午后,我刚更新了导出文件类型,到了晚上就发现fofa hack下载不了了,看了一下最新的规则, ...
- Flask 上下文是什么 ?
哈喽大家好,我是咸鱼.今天我们来聊聊什么是 Flask 上下文 咸鱼在刚接触到这个概念的时候脑子里蹦出的第一个词是 CPU 上下文 今天咸鱼希望通过这篇文章,让大家能够对 Flask 上下文设计的 ...