大一统的监控探针采集器 cprobe
需求背景
监控数据采集领域,比如 Prometheus 生态有非常多的 Exporter,虽然生态繁荣,但是无法达到开箱即用的大一统体验,Exporter 体系的核心问题有:
- 良莠不齐:有的 Exporter 写的非常棒,有的则并不完善,有些监控类别甚至有多个 Exporter,选择困难
- 写法各异:Exporter 所用的日志库、配置文件管理方式、命令行传参方式各异,体验不一
- 倚重边车模式:有些 Exporter 和采集目标之间是一对一的关系,有几个采集目标就需要部署几个 Exporter,在 Kubernetes 环境下相对容易管理,在物理机虚拟机环境下管理起来就比较复杂了,而且多个 Exporter 还会带来资源成本的提升
- 配置文件切分:对于非边车模式的 Exporter,即一个 Exporter 对应多个采集目标的,通常很难做到不同的采集目标不同的配置,期望能有一种配置文件切分 INCLUDE 机制,不同的采集目标采用不同的配置
- 缺乏监控目标服务发现:对于支持
/probe模式的 Exporter,服务发现就通过 Prometheus + relabel 模式来实现了,如果不支持/probe模式的 Exporter 则缺乏监控目标的服务发现机制
要是能有一个统一的采集器,把这些问题都解决掉,采用插件机制,All-in-One 采集所有监控目标,不同的插件体验一致,那该多好啊!cprobe 应运而生!
对比
社区有一些其他采集器,比如 grafana-agent,也是一个缝合怪,也是把各类 Exporter 的能力整合在一起,但是整合的非常生硬,缺少统一化设计,对目标实例的服务发现支持较弱;telegraf 和 categraf 则自成一派,指标体系没有拥抱 Prometheus exporter 生态,相关仪表盘、告警规则资源匮乏,另外服务发现机制做的也不好。datadog-agent 确实比较完备,但是生态上也是自成一派,服务于自身的 SaaS 服务,较少有开源用户采用。
以我当前的认知,监控数据的采集大抵需要三个角色,一个是部署在所有的目标机器上的,比如使用 categraf,中心端需要两个采集器,一个用于采集 Prometheus 协议的端点数据,可以使用 vmagent 或 Prometheus agent mode,另外一个用于采集所有非 Prometheus 协议的端点数据,计划就是 cprobe。
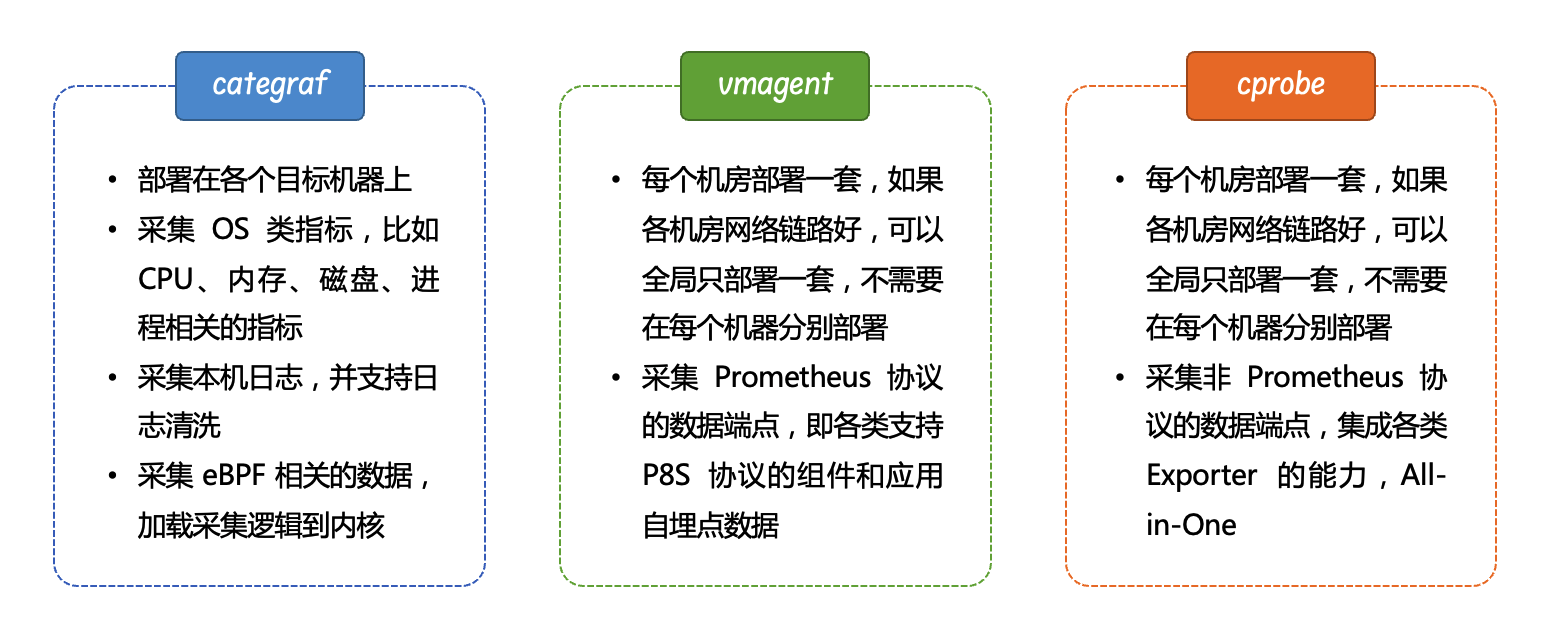
当然,vmagent 和 cprobe 都是探针角色,理论上可以合二为一,未来也会考虑让 cprobe 支持采集 Prometheus 协议的端点数据,这样就可以把 vmagent 去掉了,不过 vmagent 确实工作的很好,而且已经有很多用户在使用了,所以这个计划暂时搁置。
当前进展
cprobe 刚刚起步,完成了基础框架的搭建,也集成了 mysql、redis、kafka、blackbox 这几个 exporter,代码已经公布到 github:

项目文档偷个懒,会直接放到 issues 里,打上不同的标签。大家如果有建议和 PR 的想法,请先提 issue。cprobe 会尽量完善文档,会成立面向研发人员和资深用户的交流群(加群联系我的微信:picobyte,备注 cprobe-公司名-姓名)。
这几个插件在整合的过程中,也做了一些改动,主要改动如下:
- 统一日志库,统一日志格式,统一日志级别控制
- 统一配置文件管理,支持配置文件切分
- 支持不同的采集目标不同的配置
- 支持采集目标的服务发现,目前主要是 file_sd 和 http_sd
- mysql 插件支持了自定义 sql
- kafka 插件原本是一个 Kafka 集群一个 exporter,现在可以一个 cprobe 监控多个 Kafka 集群
安装体验
到 cprobe 的 releases 页面 https://github.com/cprobe/cprobe/releases 下载发布包。解包之后核心就是那个二进制 cprobe,通过如下命令安装:
sudo ./cprobe -install
sudo ./cprobe -start如果是支持 systemd 的 OS,上面的安装过程实际就是自动创建了 service 文件,你可以通过下面的命令查看:
systemctl status cprobe如果不是 systemd 的 OS,会采用其他进程管理方式,比如 Windows,会创建 cprobe 服务。
配置
解压缩之后应该可以看到 conf.d 目录,这是配置文件所在目录。writer.yaml 外加一堆的插件配置目录。 writer.yaml 是配置 remote write 地址(不知道什么是 remote write 地址,请自行 Google:Prometheus remote write),可以配置多个,默认配置如下:
global:
extra_labels:
colld: cprobe
writers:
- url: http://127.0.0.1:9090/api/v1/write这是一个极简配置,也基本够用,实际 writer.yaml 中还可以配置不同时序库后端的认证信息以及 relabel 的配置,同级目录下有个 backup.yaml 可以看到一些配置样例。
不同的插件的配置会散落在各个插件目录里,以 mysql 插件举例,相关配置在 conf.d/mysql 下面,入口文件是 main.yaml,用于定义需要采集的 mysql target。target 的服务发现方式支持两种:file_sd 和 http_sd,当然,也支持 static_configs。
在 cprobe 场景下,cprobe 会直连监控目标,比如 mysql 的监控,Prometheus 是从 mysqld_exporter 获取监控数据,而 cprobe 是直连 mysql,所以 main.yaml 中要配置一些采集规则,即 scrape_rule_files。scrape_rule_files 是个数组,即可以把配置文件切分管理,这提供了极大的管理灵活性,各位自行发挥了。各个插件的配置目录下通常都会有个 doc 目录,里面会有个 README.md,README.md 中会对插件配置做说明。
后续规划
最核心的是增加更多插件,不同的插件要整理仪表盘、告警规则。框架层面,希望增加更多自埋点数据,通过 HTTP 的方式暴露更多调试信息。另外就是完善中英文文档。当然,大家如有建议也欢迎留言给我们。
大一统的监控探针采集器 cprobe的更多相关文章
- centos创建监控宝采集器及添加插件任务
官方的说明文档很不详细操作也有点小问题,故把操作记录如下. 操作系统环境: centos 5.8 python 2.4.3 创建采集器等操作这里就不说了,见官方文档:http://blog.jiank ...
- zabbix主动模式,自定义Key监控 zabbix采集器
主动模式不是只能用模板提供的标准检测器方式 zabbix-agent两种运行方式即主动模式和被动模式.默认被动模式. 两种模式是相对 客户端 角度来说的. 被动模式:等待server来取数据,可以使用 ...
- javacoo/CowSwing 丑牛迷你采集器
丑牛迷你采集器是一款基于Java Swing开发的专业的网络数据采集/信息挖掘处理软件,通过灵活的配置,可以很轻松迅速地从 网页上抓取结构化的文本.图片.文件等资源信息,可编辑筛选处理后选择发布到网站 ...
- 实战ELK(4)Metricbeat 轻量型指标采集器
一.介绍 用于从系统和服务收集指标.从 CPU 到内存,从 Redis 到 Nginx,Metricbeat 能够以一种轻量型的方式,输送各种系统和服务统计数据. 1.系统级监控,更简洁(轻量型指标采 ...
- Metricbeat 轻量型指标采集器
一.介绍 用于从系统和服务收集指标.从 CPU 到内存,从 Redis 到 Nginx,Metricbeat 能够以一种轻量型的方式,输送各种系统和服务统计数据. 1.系统级监控,更简洁(轻量型指标采 ...
- Hawk 3. 网页采集器
1.基本入门 1. 原理(建议阅读) 网页采集器的功能是获取网页中的数据(废话).通常来说,目标可能是列表(如购物车列表),或是一个页面中的固定字段(如JD某商品的价格和介绍,在页面中只有一个).因此 ...
- 火车采集器 帝国CMS7.2免登录发布模块
帝国cms7.2增加了金刚模式,登录发布有难度.免登录发布模块配合火车采集器,完美解决你遇到的问题. 免登录直接获取栏目列表 通过文件内设置密码免登录发布数据 帝国cms7.2免登陆文章发布接口使用说 ...
- WEB页面采集器编写经验之一:静态页面采集器
严格意义来说,采集器和爬虫不是一回事:采集器是对特定结构的数据来源进行解析.结构化,将所需的数据从中提取出来:而爬虫的主要目标更多的是页面里的链接和页面的TITLE. 采集器也写过不少了,随便写一点经 ...
- WP开发-Toolkit组件 列表采集器(ListPicker)的使用
列表采集器ListPicker在作用上与html中的<select/>标签一样 都是提供多选一功能,区别在于ListPicker可以自定义下拉状态和非下拉状态的样式. 1.模板设置 Lis ...
- 【RSYSLOG】rsyslog作为日志采集器安装配置说明
RSYSLOG is the rocket-fast system for log processing. About 由于环境基于CentOS 6.7 x64,rsyslog本身就是OS的组件,由于 ...
随机推荐
- vue中vant-list组件实现下拉刷新,上滑加载
后端返回的数据是一股脑的情况(不是按pageSize,pageNum一组一组的发送)时,前端使用vant-list实现懒加载需要再写一点js,记录一下 main.js: Vue.use(List); ...
- Python使用HTMLTestRunner运行所有用例并产生报告
#coding:utf-8import unittestimport osimport sysimport HTMLTestRunnercase_path = os.path.join(os.path ...
- Solution Set - 图上问题
CF360E Link&Submission. 首先显然可以选择的边的权值一定会取端点值.事实上,第一个人经过的边选最小,第一个人不经过的边选最大,这样一定不劣.进一步,如果 \(s_1\) ...
- pde复习笔记 第一章 波动方程 第六节 能量不等式、波动方程解的唯一性和稳定性
能量不等式 这一部分需要知道的是能量的表达式 \[E(t)=\int_{0}^{l}u_{t}^{2}+a^{2}u_{x}^{2} dx \] 一般而言题目常见的问法是证明能量是减少的,也就是我们需 ...
- 12、web 中间件加固-apache 加固
1.账号设置 1.1.防止 webshell 越权使用 修改 httpd.conf:/etc/httpd/conf/httpd.conf 或编译路径下 /conf/httpd.conf 检查程序启动账 ...
- Windows 10 开启秒钟显示
开始搜索运行 注册表管理器 regedit 定位路径到 HKEY_CURRENT_USER\SOFTWARE\Microsoft\Windows\CurrentVersion\Explorer\Adv ...
- 5GC 关键技术之网络切片
目录 文章目录 目录 前文列表 网络切片的需求来自于业务对网络提出的差异化要求 基于 3 大业务场景的切片 基于切片资源访问对象的切片 网络切片的商业价值 网络切片的底层技术支撑 网络切片的粒度 网络 ...
- 在 JS 中使用 canvas 给图片添加文字水印
实现说明: 1.先通过 new Image() 载入图片: 2.图片加载成功后使用 drawImage() 将图片绘制到画布上: 3.最后使用 fillText() 函数绘制水印. 下面展示了详细用法 ...
- ObjectArx 创建一个自定义实体项目步骤
我使用的环境是cad2018+objectarx2018+vs2015+win10.先要安装desk向导程序,用向导创建项目对于初学者来说是很方便的,然后在配置程序编译链接的环境,最后就可以写一个项目 ...
- win11或win10客户端邮箱账号登录设置
1.alimall阿里企业邮箱 点击账户 点击添加账户 点击其他账户 输入电子邮箱地址和密码,并点击登录即可 2.Qq邮箱 2.1 点击账户 2.2 点击添加账户 2.3 点击其他账户 2.4 输入电 ...