17 Transformer 的解码器(Decoders)——我要生成一个又一个单词
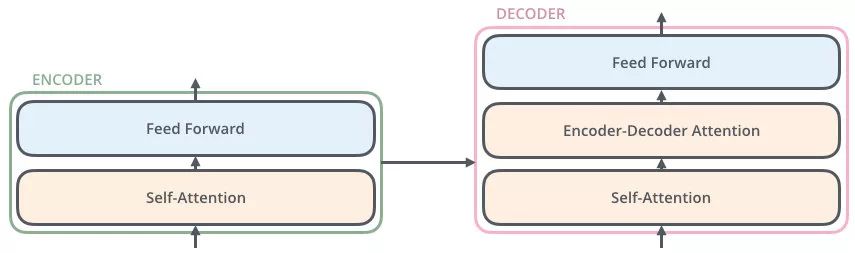
Transformer 编码器
编码器在干吗:词向量、图片向量,总而言之,编码器就是让计算机能够更合理地(不确定性的)认识人类世界客观存在的一些东西
Transformer 解码器
解码器会接收编码器生成的词向量,然后通过这个词向量去生成翻译的结果。
解码器的 Self-Attention 在编码已经生成的单词
假如目标词“我是一个学生”---》masked Self-Attention
训练阶段:目标词“我是一个学生”是已知的,然后 Self-Attention 是对“我是一个学生” 做计算
如果不做 masked,每次训练阶段,都会获得全部的信息
如果做 masked,Self-Attention 第一次对“我”做计算
Self-Attention 第二次对“我是”做计算
……
测试阶段:
- 目标词未知,假设目标词是“我是一个学生”(未知),Self-Attention 第一次对“我”做计算
- 第二次对“我是”做计算
- ……
而测试阶段,没生成一点,获得一点
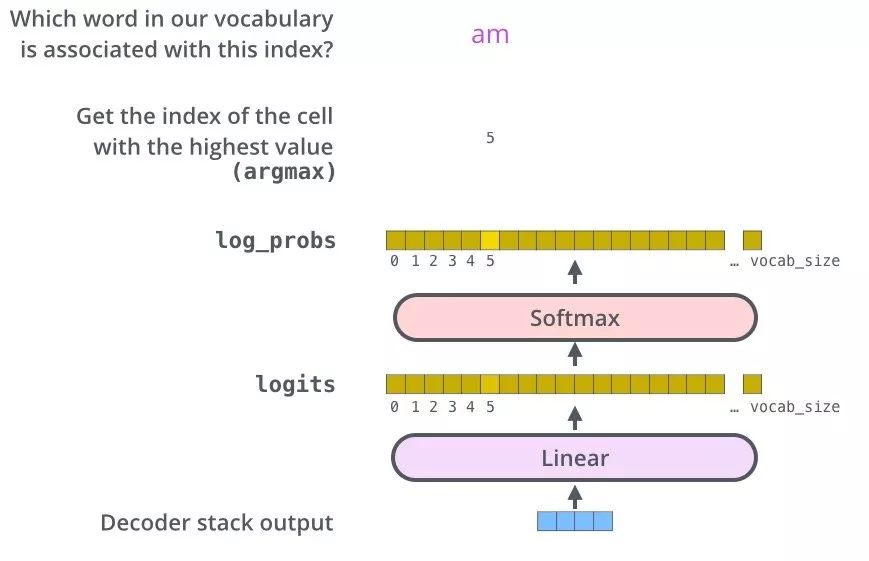
生成词

Linear 层转换成词表的维度
softmax 得到最大词的概率
softmax 细话
单词表
17 Transformer 的解码器(Decoders)——我要生成一个又一个单词的更多相关文章
- 17.组件页面应用和vue项目生成
基本示例 这里有一个 Vue 组件的示例: // 定义一个名为 button-counter 的新组件 Vue.component('button-counter', { data: function ...
- [CareerCup] 17.9 Word Frequency in a Book 书中单词频率
17.9 Design a method to find the frequency of occurrences of any given word in a book. 这道题让我们找书中单词出现 ...
- PHP生成随机单词
class GenRandWords { private static $_alphas = [ 'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', ' ...
- Attention和Transformer详解
目录 Transformer引入 Encoder 详解 输入部分 Embedding 位置嵌入 注意力机制 人类的注意力机制 Attention 计算 多头 Attention 计算 残差及其作用 B ...
- 【译】图解Transformer
目录 从宏观上看Transformer 把张量画出来 开始编码! 从宏观上看自注意力 自注意力的细节 自注意力的矩阵计算 "多头"自注意力 用位置编码表示序列的顺序 残差 解码器 ...
- 用Python手把手教你搭一个Transformer!
来源商业新知网,原标题:百闻不如一码!手把手教你用Python搭一个Transformer 与基于RNN的方法相比,Transformer 不需要循环,主要是由Attention 机制组成,因而可以充 ...
- 三大特征提取器(RNN/CNN/Transformer)
目录 三大特征提取器 - RNN.CNN和Transformer 简介 循环神经网络RNN 传统RNN 长短期记忆网络(LSTM) 卷积神经网络CNN NLP界CNN模型的进化史 Transforme ...
- transformer模型简介
Transformer模型由<Attention is All You Need>提出,有一个完整的Encoder-Decoder框架,其主要由attention(注意力)机制构成.论文地 ...
- Transformer模型---encoder
一.简介 论文链接:<Attention is all you need> 由google团队在2017年发表于NIPS,Transformer 是一种新的.基于 attention 机制 ...
- zz全面拥抱Transformer
放弃幻想,全面拥抱Transformer:自然语言处理三大特征抽取器(CNN/RNN/TF)比较 在辞旧迎新的时刻,大家都在忙着回顾过去一年的成绩(或者在灶台前含泪数锅),并对2019做着规划,当然也 ...
随机推荐
- 新手入门深度学习:在不使用Google的情况下如何在国内获得免费的算力 —— 算力共享,驱动人工智能创新的新引擎
分享链接地址: 算力获新生 | 算力共享,驱动人工智能创新的新引擎
- Apache DolphinScheduler支持Flink吗?
随着大数据技术的快速发展,很多企业开始将Flink引入到生产环境中,以满足日益复杂的数据处理需求.而作为一款企业级的数据调度平台,Apache DolphinScheduler也跟上了时代步伐,推出了 ...
- 视频中ppt、代码、ubuntu环境请扫描下面二维码,回复:ubuntu,即可获得
历时4个多月,第一期Linux驱动视频录制完毕, 一共32期,现在全部同步到了B站. 如果你觉得视频对你有用,建议大家多多点赞,投投免费硬币, 算是对我辛苦的劳动的认可. 视频中ppt.代码.ubun ...
- 兼容ios11的正则匹配
ios11不支持正则零宽断言,以字符串 $哈哈哈(sh039488)$ 为例: 不兼容写法:/\$(?<=\$).*?(?=\)\$)\)\$/g 兼容写法:/\$(.*?)\)\$/g
- JavaScript设计模式样例十三 —— 模版方法模式
模板方法模式(Template Method Pattern) 定义:一个抽象类公开定义了执行它的方法的方式/模板.它的子类可以按需要重写方法实现,但调用将以抽象类中定义的方式进行.目的:一些方法通用 ...
- Tesla 开发者 API 指南:BLE 密钥 – 身份验证和车辆命令
注意:本工具只能运行于 mac 或者 linux, win下不支持. 1. 克隆项目到本地 https://github.com/teslamotors/vehicle-command.git 2. ...
- TwinCAT3 - 实现自己的Dictionary
目录 1,前言 2,C#的字典 3,TwinCAT3的字典 定义功能块 添加方法 4,用起来 1,前言 C#有字典,TwinCAT没字典,咋办,自己写一个咯 2,C#的字典 C#的字典使用很简单,下面 ...
- 从日志记一次Spring事务完整流程
spring事务一次完整流程,创建 >确认获取连接 >完成 >提交>释放链接 DataSourceTransactionManager //Step1. 进入业务方法前,依据事 ...
- SpringMVC:域对象共享数据
SpringMVC:域对象共享数据 使用ServletAPI向request域对象共享数据 @RequestMapping("/testServletAPI") public St ...
- AWS Data Analytics Fundamentals 官方课程笔记 - Variety, Veracity, Value
Variety structured data applications include Amazon RDS, Amazon Aurora, MySQL, MariaDB, PostgreSQL, ...