解析数仓lazyagg查询重写优化规则
摘要:为了降低调优难度,提升产品易用性,GaussDB(DWS)提供了lazyagg查询重写优化规则。
本文分享自华为云社区《GaussDB(DWS) lazyagg查询重写优化解析【这次高斯不是数学家】》,作者: OreoreO 。
聚集操作将查询结果按某一列或多列的值分组,值相等的为一组。聚集操作是一种常见的操作并在金融客户中有广泛的使用。例如如下语句则聚集操作将查询结果按某一列或多列的值分组,值相等的为一组。聚集操作是一种常见的操作并在金融客户中有广泛的使用。例如如下语句eze聚集操作将查询结果按某一列或多列的值分组,值相等的为一组。聚集操作是一种常见的操作并在金融客户中有广泛的使用。例如如下语句则聚集操作将查询结果按某一列或多列的值分组,值相等的为一组。聚集操作是一种常见的操作并在金融客户中有广泛的使用。例如如下语句:
SELECT a, count(a) FROM t1 GROUP BY a; -- 按a分组并计算分组内重复值的个数
一、Lazy Agg重写规则
数据量大的场景下,聚集运算由于数据量大导致下盘,聚集操作执行时间成为性能瓶颈,从而导致整个查询执行效率非常差。例如:
SELECT t2.b, sum(cc) FROM (SELECT b, sum(c) AS cc FROM t1 GROUP BY b) AS s, t2 WHERE s.b=t2.b GROUP BY t2.b;
子查询对t1.b列进行聚集,对t1.c列求和,在外部查询中,同样也存在聚集运算,对子查询的聚集求和列cc列求和。对于这类语句,当子查询的聚集运算较耗时的情况下,可以利用查询重写规则消除子查询的聚集运算,由外部查询的聚集函数统一完成聚集运算。消除子查询后可能导致子查询行数增多,但对于子查询聚集运算时t1.b列的distinct值较多的场景,子查询聚集运算后的行数较原表不会有明显缩减,不会导致外层JOIN运算量的大量增加。即语句可被重写为:
SELECT t2.b, sum(cc) FROM (SELECT b, c AS cc FROM t1) AS s, t2 WHERE s.b=t2.b GROUP BY t2.b;
这个改写规则称为Lazy Agg,适用于基表数据量大且distinct值较多的场景。如果重复值较少,那么消除了聚集操作会导致Join后的行数激增,Join性能较差,因此需要将Agg下推到Join之前进行,通过提前的Agg操作减少Join结果的行数,这个改写规则称为Eager Agg。
二、GaussDB(DWS) lazyagg优化
为了降低调优难度,提升产品易用性,GaussDB(DWS)提供了lazyagg查询重写优化规则,可以通过设置guc参数rewrite_rule包含’lazyagg’使用Lazy Agg查询重写优化。开启lazyagg查询重写优化后,对满足条件的场景会优化并消除子查询中的聚集操作。原计划如下所示:
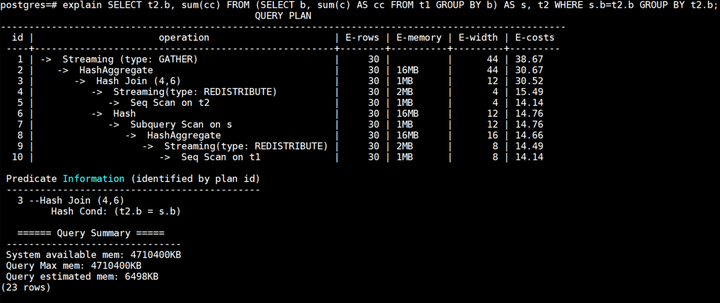
lazyagg重写优化后计划如下所示:
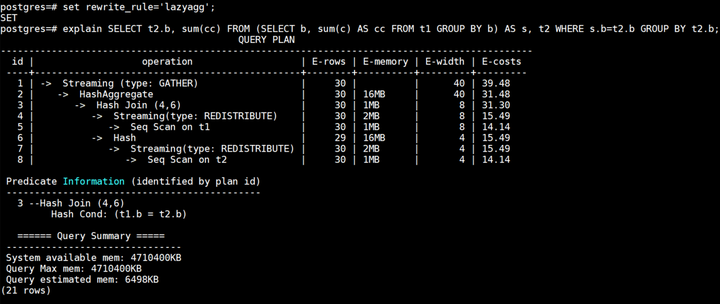
可以看到相比于原计划,lazyagg重写优化后消除掉了原计划中的聚集操作,即7号Subquery Scan算子和8号HashAggregate算子。
三、lazyagg优化规格
- 支持子查询为单一聚集查询或包含聚集子集合操作的查询。集合操作仅支持UNION ALL,可对部分分支子查询进行聚集运算消除。子查询需为JOIN表之一(不在TargetList、Where子句等其他位置)。
- 支持若外部查询的所有Agg参数列包含于其某个子查询的Agg函数列,则可对该子查询的聚集运算进行消除。
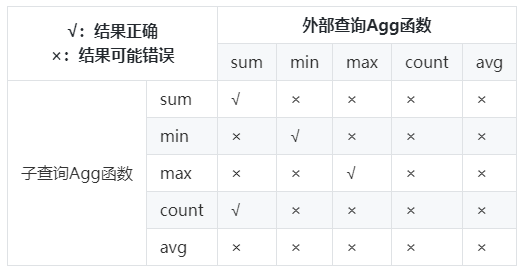
- 支持所有消除子查询聚集运算后结果正确的聚集函数种类。聚集函数种类结果正确性见下表:
4.场景约束
在上述场景扩展的基础上,对于可能导致结果错误的场景,不进行查询重写,包括但不限于:
- 不支持消除的Agg函数类型。
- 子查询中包含其它条件或算子,会导致重写后结果错误,例如HAVING、window agg、LIMIT、OFFSET、AP function、distinct、recursive等。
- 外层Agg参数列、GROUP BY列或JOIN列中包含volatile函数,如random、timeofday等。
- 子查询Agg函数外、外部查询Agg函数内有其他表达式或函数操作,如子查询Agg函数列为sum+1、max+max(d),外部查询Agg函数列为sum(cc+1)等。
- 外部查询的JOIN列、GROUP BY列或其它条件中包含子查询Agg函数列。
- 子查询在LEFT JOIN、RIGHT JOIN的inner边或FULL JOIN中,且子查询Agg函数为count,外部查询Agg函数为sum的。
四、结语
通过本文的分析,相信用户朋友已经充分了解了Lazy Agg重写优化的使用场景,以及GaussDB(DWS)的lazyagg实现方式。希望广大用户能够通过深入的了解,对GaussDB(DWS)的性能调优产生浓厚的兴趣并深度参与进来。
参考文档:GaussDB(DWS)性能调优系列实战篇四:十八般武艺之SQL改写
【这次高斯不是数学家】有奖征文火热进行中:https://bbs.huaweicloud.com/blogs/345260
解析数仓lazyagg查询重写优化规则的更多相关文章
- ByteHouse云数仓版查询性能优化和MySQL生态完善
ByteHouse云数仓版是字节跳动数据平台团队在复用开源 ClickHouse runtime 的基础上,基于云原生架构重构设计,并新增和优化了大量功能.在字节内部,ByteHouse被广泛用于各类 ...
- 解析数仓OLAP函数:ROLLUP、CUBE、GROUPING SETS
摘要:GaussDB(DWS) ROLLUP,CUBE,GROUPING SETS等OLAP函数的原理解析. 本文分享自华为云社区<GaussDB(DWS) OLAP函数浅析>,作者: D ...
- 技术专家说 | 如何基于 Spark 和 Z-Order 实现企业级离线数仓降本提效?
[点击了解更多大数据知识] 市场的变幻,政策的完善,技术的革新--种种因素让我们面对太多的挑战,这仍需我们不断探索.克服. 今年,网易数帆将持续推出新栏目「金融专家说」「技术专家说」「产品专家说」等, ...
- 【离线数仓】Day02-用户行为数据仓库:分层介绍、环境搭建(hive、tez)、LZO压缩、建表查询导入加索引、编写脚本
一.数仓分层概念 1.为什么要分层 ODS:原始数据层 DWD层:明细数据层 DWS:服务数据层 ADS:数据应用层 2.数仓分层 3.数据集市与数据仓库概念 4.数仓命名规范 ODS层命名为odsD ...
- 【离线数仓CDH版本】即席查询工具(Presto、Druid、Kylin)、CDH数仓、Impala查询
1.即席查询 一.Presto 大数据量.秒级.多数据源的查询引擎[支持各种数据源work的内存级查询] 由coordinator和多个work构成,work对应不同数据源Catalog 特点:基于内 ...
- MySQL 子查询(四)子查询的优化、将子查询重写为连接
MySQL 5.7 ref ——13.2.10.10优化子查询 十.子查询的优化 开发正在进行中,因此从长远来看,没有什么优化建议是可靠的.以下列表提供了一些您可能想要使用的有趣技巧.See also ...
- 高性能MySQL笔记 第6章 查询性能优化
6.1 为什么查询速度会慢 查询的生命周期大致可按照顺序来看:从客户端,到服务器,然后在服务器上进行解析,生成执行计划,执行,并返回结果给客户端.其中“执行”可以认为是整个生命周期中最重要的阶段. ...
- mysql笔记03 查询性能优化
查询性能优化 1. 为什么查询速度会慢? 1). 如果把查询看作是一个任务,那么它由一系列子任务组成,每个子任务都会消耗一定的时间.如果要优化查询,实际上要优化其子任务,要么消除其中一些子任务,要么减 ...
- MySQL之查询性能优化(二)
查询执行的基础 当希望MySQL能够以更高的性能运行查询时,最好的办法就是弄清楚MySQL是如何优化和执行查询的.MySQL执行一个查询的过程,根据图1-1,我们可以看到当向MySQL发送一个请求时, ...
- 看SparkSql如何支撑企业数仓
企业级数仓架构设计与选型的时候需要从开发的便利性.生态.解耦程度.性能. 安全这几个纬度思考.本文作者:惊帆 来自于数据平台 EMR 团队 前言 Apache Hive 经过多年的发展,目前基本已经成 ...
随机推荐
- 多维评测指标解读第17届MSU世界编码器大赛全高清10bit赛道结果
超高清视频纤毫毕现的关键一环. 01 主要指标多项第一,带宽节省48% 近日,第17届MSU世界编码器大赛全高清10bit赛道成绩揭晓,阿里自研的H.266/VVC编码器Ali266在该赛道最高效的1 ...
- 下载kubernetes
前言 页面介绍了k8s的组件下载的方法 二进制文件 二进制文件的下载链接在CHANGELOG文件中,这里有一个技巧是直接下载Server Binaries,这个是包含了所有的二进制文件.下载后记得比对 ...
- 使用aop(肉夹馍)为BlazorServer实现统一异常处理
背景 用户做一个操作往往对应一个方法的执行,而方法内部会调用别的方法,内部可能又会调用别的方法,从而形成一个调用链.我们一般是在最顶层的方法去加try,而不是调用链的每一层都去加try. 在web开发 ...
- centos服务器搭建https
一.环境 OS:CentOS Linux release 8.2.2004 (Core) 硬件:某外网云服务器虚拟机 二.安装命令 1.安装nginx yum install nginx 2.安装签发 ...
- 如何恢复win10/11音量条为默认样式?
保存为reg: Windows Registry Editor Version 5.00 [HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Windows NT\Curre ...
- 数据结构与算法(LeetCode) 第二节 链表结构、栈、队列、递归行为、哈希表和有序表
一.链表结构 1.单向链表节点结构 public class Node{ public int value; public Node next; public Node(int data){ valu ...
- Xmind思维导图工具2023最新专业版破解思路
工具介绍 XMind 是一款最为流行的专业级思维_导图_制作与编辑软件,它现在在全球范围内都已极具名气,可谓是办公.学习.团队交流必备工具之一. 准备工作 1,官方Xmind软件 2,一个心意的编辑器 ...
- JavaScript 语法:运算符号
作者:WangMin 格言:努力做好自己喜欢的每一件事 JavaScript要进行各种各样的运算,就要使用不同的运算符号. JavaScript 算数运算符 算数运算符用于对数字执行算数运算,分别有以 ...
- JZYZ作业好题
文章目录 敲砖块 Circle 敲砖块 首先把砖块向左对齐, 这样选择第 ( i , j ) (i,j) (i,j)块的前提是第 ( i − 1 , j ) , ( i − 1 , j + 1 ) ( ...
- JavaWeb项目中web.xml配置文件<servlet-class>…</servlet-class>中的路径出现问题以及服务器错误的解决办法
问题如图 原因: 1.改变了 WEB-INF 文件夹下 lib 文件夹下 servlet-api.jar 的路径2.缺失lib文件夹下的 servlet-api.jar,没有添加到库中 解决办法: 不 ...