urllib2使用2
Timeout 设置
- import urllib2
- response = urllib2.urlopen('http://www.google.com', timeout=10)
在 HTTP Request 中加入特定的 Header
要加入 header,需要使用 Request 对象:
import urllib2
request = urllib2.Request('http://www.baidu.com/')
request.add_header('User-Agent', 'fake-client')
response = urllib2.urlopen(request)
print response.read()
对有些 header 要特别留意,服务器会针对这些 header 做检查
User-Agent : 有些服务器或 Proxy 会通过该值来判断是否是浏览器发出的请求
Content-Type : 在使用 REST 接口时,服务器会检查该值,用来确定 HTTP Body 中的内容该怎样解析。常见的取值有:
application/xml : 在 XML RPC,如 RESTful/SOAP 调用时使用
application/json : 在 JSON RPC 调用时使用
application/x-www-form-urlencoded : 浏览器提交 Web 表单时使用
在使用服务器提供的 RESTful 或 SOAP 服务时, Content-Type 设置错误会导致服务器拒绝服务
Redirect
urllib2 默认情况下会针对 HTTP 3XX 返回码自动进行 redirect 动作,无需人工配置。要检测是否发生了 redirect 动作,只要检查一下 Response 的 URL 和 Request 的 URL 是否一致就可以了。
import urllib2
my_url = 'http://www.google.cn'
response = urllib2.urlopen(my_url)
redirected = response.geturl() == my_url
print redirected my_url = 'http://rrurl.cn/b1UZuP'
response = urllib2.urlopen(my_url)
redirected = response.geturl() == my_url
print redirected
如果不想自动 redirect,除了使用更低层次的 httplib 库之外,还可以自定义HTTPRedirectHandler 类。
import urllib2
class RedirectHandler(urllib2.HTTPRedirectHandler):
def http_error_301(self, req, fp, code, msg, headers):
print ""
pass
def http_error_302(self, req, fp, code, msg, headers):
print ""
pass opener = urllib2.build_opener(RedirectHandler)
opener.open('http://rrurl.cn/b1UZuP')
Cookie
urllib2 对 Cookie 的处理也是自动的。如果需要得到某个 Cookie 项的值,可以这么做:
import urllib2
import cookielib
cookie = cookielib.CookieJar()
opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cookie))
response = opener.open('http://www.baidu.com')
for item in cookie:
print 'Name = '+item.name
print 'Value = '+item.value
运行之后就会输出访问百度的Cookie值:

得到 HTTP 的返回码
对于 200 OK 来说,只要使用 urlopen 返回的 response 对象的 getcode() 方法就可以得到 HTTP 的返回码。但对其它返回码来说,urlopen 会抛出异常。这时候,就要检查异常对象的 code 属性了:
import urllib2
try:
response = urllib2.urlopen('http://bbs.csdn.net/why')
except urllib2.HTTPError, e:
print e.code
Debug Log
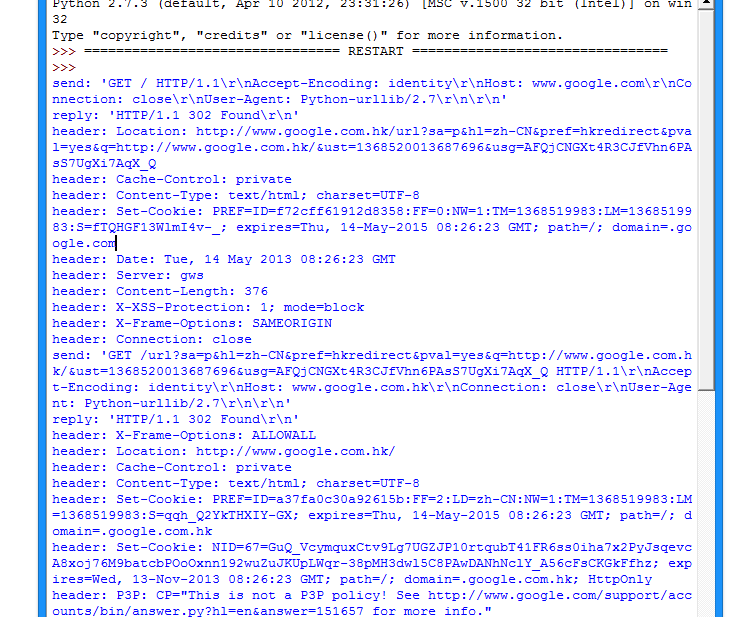
使用 urllib2 时,可以通过下面的方法把 debug Log 打开,这样收发包的内容就会在屏幕上打印出来,方便调试,有时可以省去抓包的工作
import urllib2
httpHandler = urllib2.HTTPHandler(debuglevel=1)
httpsHandler = urllib2.HTTPSHandler(debuglevel=1)
opener = urllib2.build_opener(httpHandler, httpsHandler)
urllib2.install_opener(opener)
response = urllib2.urlopen('http://www.google.com')
这样就可以看到传输的数据包内容了:
表单的处理
登录必要填表,表单怎么填?
首先利用工具截取所要填表的内容。
比如我一般用firefox+httpfox插件来看看自己到底发送了些什么包。
以verycd为例,先找到自己发的POST请求,以及POST表单项。
可以看到verycd的话需要填username,password,continueURI,fk,login_submit这几项,其中fk是随机生成的(其实不太随机,看上去像是把epoch时间经过简单的编码生成的),需要从网页获取,也就是说得先访问一次网页,用正则表达式等工具截取返回数据中的fk项。continueURI顾名思义可以随便写,login_submit是固定的,这从源码可以看出。还有username,password那就很显然了:
# -*- coding: utf-8 -*-
import urllib
import urllib2
postdata=urllib.urlencode({
'username':'汪小光',
'password':'why888',
'continueURI':'http://www.verycd.com/',
'fk':'',
'login_submit':'登录'
})
req = urllib2.Request(
url = 'http://secure.verycd.com/signin',
data = postdata
)
result = urllib2.urlopen(req)
print result.read()
伪装成浏览器访问
某些网站反感爬虫的到访,于是对爬虫一律拒绝请求
这时候我们需要伪装成浏览器,这可以通过修改http包中的header来实现
#…
headers = {
'User-Agent':'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6'
}
req = urllib2.Request(
url = 'http://secure.verycd.com/signin/*/http://www.verycd.com/',
data = postdata,
headers = headers
)
#...
对付"反盗链"
某些站点有所谓的反盗链设置,其实说穿了很简单,
就是检查你发送请求的header里面,referer站点是不是他自己,
所以我们只需要像把headers的referer改成该网站即可,以cnbeta为例:
#...
headers = {
'Referer':'http://www.cnbeta.com/articles'
}
#...
headers是一个dict数据结构,你可以放入任何想要的header,来做一些伪装。
例如,有些网站喜欢读取header中的X-Forwarded-For来看看人家的真实IP,可以直接把X-Forwarde-For改了。
http://outofmemory.cn/code-snippet/1653/python-pachong-zhua-wangye-summary
http://www.crifan.com/use_python_urllib-urlretrieve_download_picture_speed_too_slow_add_user_agent_for_urlretrieve/
http://hi.baidu.com/554151688/item/331476bce8559cf762388ede
http://www.douban.com/group/topic/16925000/ 很好的资源
http://blog.csdn.net/dongnanyanhai/article/details/5552431
http://www.crifan.com/emulate_login_website_using_python/
http://blog.csdn.net/column/details/why-bug.html 系列教材
urllib2使用2的更多相关文章
- 【Python网络爬虫二】使用urllib2抓去网页内容
在Python中通过导入urllib2组件,来完成网页的抓取工作.在python3.x中被改为urllib.request. 爬取具体的过程类似于使用程序模拟IE浏览器的功能,把URL作为HTTP请求 ...
- Python urllib2 调试
#!/usr/bin/env python # coding=utf-8 __author__ = 'zhaoyingnan' import urllib import urllib2 import ...
- 使用urllib2打开网页的三种方法
#coding:utf-8 import urllib2 import cookielib url="http://www.baidu.com" print '方法 1' resp ...
- No module named 'urllib2'
import urllib2 response = urllib2.urlopen('http://www.baidu.com/') html = response.read() print html ...
- Python自动化测试 (九)urllib2 发送HTTP Request
urllib2 是Python自带的标准模块, 用来发送HTTP Request的. 类似于 .NET中的, HttpWebRequest类 urllib2 的优点 Python urllib2 ...
- urllib2抓取HTML存入Excel
通过urllib2抓取HTML网页,然后过滤出包含特定字符的行,并写入Excel文件: # -*- coding: utf-8 -*- import sys #import urllib import ...
- [Python] urllib2.HTTPError: HTTP Error 403: Forbidden
搬运自http://www.2cto.com/kf/201309/242273.html,感谢原作. 之所以出现上面的异常,是因为如果用 urllib.request.urlopen 方式打开一个UR ...
- python urllib2 发起http请求post
使用urllib2发起post请求 def GetCsspToken(): data = json.dumps({"userName":"wenbin", &q ...
- cookielib和urllib2模块相结合模拟网站登录
1.cookielib模块 cookielib模块的主要作用是提供可存储cookie的对象,以便于与urllib2模块配合使用来访问Internet资源.例如可以利用 本模块的CookieJar类的对 ...
- 使用python标准库urllib2访问网页
#访问不需要登录的网页import urllib2target_page_url='http://10.224.110.118/myweb/view.jsp' f = urllib2.urlopen( ...
随机推荐
- 那些年我们写过的三重循环----CodeForces 295B Greg and Graph 重温Floyd算法
Greg and Graph time limit per test 3 seconds memory limit per test 256 megabytes input standard inpu ...
- Ext2文件系统布局,文件数据块寻址,VFS虚拟文件系统
注:本分类下文章大多整理自<深入分析linux内核源代码>一书,另有参考其他一些资料如<linux内核完全剖析>.<linux c 编程一站式学习>等,只是为了更好 ...
- No.1小白的HTML+CSS心得篇
一个web前端的小白,听前辈说写好笔记很关键,so 特此用博客来开始记录自己的旅程——Web之路 最近几天看的HTML 1.纠正一个认知错误 “HTML是一种编程语言” ————(错) HTML ( ...
- iOS 自定义各类bar的属性
在iOS应用开发中,经常需要为导航栏和标签栏设置相同的主题,一个一个去设置的话,就太麻烦了,可以通过对应用中所有的导航栏和标签栏同意设置背景.字体等属性. 如:创建一个继承自“UINavigation ...
- Android应用开发基础篇(7)-----BroadcastReceiver
链接地址:http://www.cnblogs.com/lknlfy/archive/2012/02/22/2363644.html 一.概述 BroadcastReceiver,意思就是广播信息接收 ...
- BZOJ 1058: [ZJOI2007]报表统计( 链表 + set )
这种题用数据结构怎么写都能AC吧...按1~N弄个链表然后每次插入时就更新答案, 用set维护就可以了... --------------------------------------------- ...
- BZOJ 3444: 最后的晚餐( )
把暗恋关系看成无向边, 那某个点度数超过2就无解.存在环也是无解.有解的话对连通分量进行排列就行了. ------------------------------------------------- ...
- Spring--依赖注入
Spring 能有效地组织J2EE应用各层的对象.不管是控 制层的Action对象,还是业务层的Service对象,还是持久层的DAO对象,都可在Spring的 管理下有机地协调.运行.Spring将 ...
- Linux下nc命来实现文件传输
发送端:cat test.txt | nc -l -p 6666或者nc -l -p 6666 < test.txt 有些版本不要在 -p[监听6666端口,等待连接](设发送端IP为10.20 ...
- 读书笔记: nodejs API 参考
>> bufferBuffer对象是全局对象Buffer支持的编码方式:ascii, utf8, base64, binarynew Buffer(size)new Buffer(arra ...