Spark函数详解系列之RDD基本转换
object Map {
def main(args: Array[String]) {
val conf = new SparkConf().setMaster("local").setAppName("map")
val sc = new SparkContext(conf)
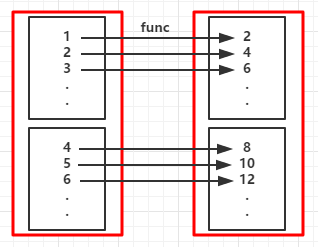
val rdd = sc.parallelize(1 to 10) //创建RDD
val map = rdd.map(_*2) //对RDD中的每个元素都乘于2
map.foreach(x => print(x+" "))
sc.stop()
}
}

//...省略sc
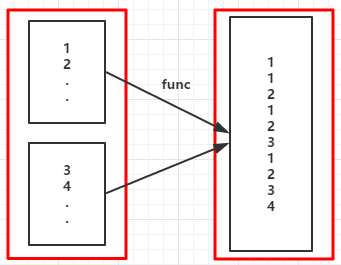
val rdd = sc.parallelize(1 to 5)
val fm = rdd.flatMap(x => (1 to x)).collect()
fm.foreach( x => print(x + " "))
1 1 2 1 2 3 1 2 3 4 1 2 3 4 5
Range(1) Range(1, 2) Range(1, 2, 3) Range(1, 2, 3, 4) Range(1, 2, 3, 4, 5)
(RDD依赖图)

object MapPartitions {
//定义函数
def partitionsFun(/*index : Int,*/iter : Iterator[(String,String)]) : Iterator[String] = {
var woman = List[String]()
while (iter.hasNext){
val next = iter.next()
next match {
case (_,"female") => woman = /*"["+index+"]"+*/next._1 :: woman
case _ =>
}
}
return woman.iterator
}
def main(args: Array[String]) {
val conf = new SparkConf().setMaster("local").setAppName("mappartitions")
val sc = new SparkContext(conf)
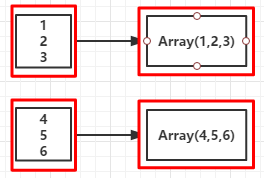
val l = List(("kpop","female"),("zorro","male"),("mobin","male"),("lucy","female"))
val rdd = sc.parallelize(l,2)
val mp = rdd.mapPartitions(partitionsFun)
/*val mp = rdd.mapPartitionsWithIndex(partitionsFun)*/
mp.collect.foreach(x => (print(x +" "))) //将分区中的元素转换成Aarray再输出
}
}
kpop lucy
val mp = rdd.mapPartitions(x => x.filter(_._2 == "female")).map(x => x._1)

[0]kpop [1]lucy
//省略
val rdd = sc.parallelize(1 to 10)
val sample1 = rdd.sample(true,0.5,3)
sample1.collect.foreach(x => print(x + " "))
sc.stop
//省略sc
val rdd1 = sc.parallelize(1 to 3)
val rdd2 = sc.parallelize(3 to 5)
val unionRDD = rdd1.union(rdd2)
unionRDD.collect.foreach(x => print(x + " "))
sc.stop
1 2 3 3 4 5
//省略sc
val rdd1 = sc.parallelize(1 to 3)
val rdd2 = sc.parallelize(3 to 5)
val unionRDD = rdd1.intersection(rdd2)
unionRDD.collect.foreach(x => print(x + " "))
sc.stop
3 4
//省略sc
val list = List(1,1,2,5,2,9,6,1)
val distinctRDD = sc.parallelize(list)
val unionRDD = distinctRDD.distinct()
unionRDD.collect.foreach(x => print(x + " "))
1 6 9 5 2
//省略
val rdd1 = sc.parallelize(1 to 3)
val rdd2 = sc.parallelize(2 to 5)
val cartesianRDD = rdd1.cartesian(rdd2)
cartesianRDD.foreach(x => println(x + " "))
(1,2)
(1,3)
(1,4)
(1,5)
(2,2)
(2,3)
(2,4)
(2,5)
(3,2)
(3,3)
(3,4)
(3,5)
(RDD依赖图)


//省略
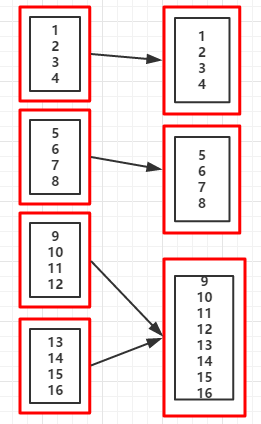
val rdd = sc.parallelize(1 to 16,4)
val coalesceRDD = rdd.coalesce(3) //当suffle的值为false时,不能增加分区数(即分区数不能从5->7)
println("重新分区后的分区个数:"+coalesceRDD.partitions.size)
重新分区后的分区个数:3
//分区后的数据集
List(1, 2, 3, 4)
List(5, 6, 7, 8)
List(9, 10, 11, 12, 13, 14, 15, 16)
//...省略
val rdd = sc.parallelize(1 to 16,4)
val coalesceRDD = rdd.coalesce(7,true)
println("重新分区后的分区个数:"+coalesceRDD.partitions.size)
println("RDD依赖关系:"+coalesceRDD.toDebugString)
重新分区后的分区个数:5
RDD依赖关系:(5) MapPartitionsRDD[4] at coalesce at Coalesce.scala:14 []
| CoalescedRDD[3] at coalesce at Coalesce.scala:14 []
| ShuffledRDD[2] at coalesce at Coalesce.scala:14 []
+-(4) MapPartitionsRDD[1] at coalesce at Coalesce.scala:14 []
| ParallelCollectionRDD[0] at parallelize at Coalesce.scala:13 []
//分区后的数据集
List(10, 13)
List(1, 5, 11, 14)
List(2, 6, 12, 15)
List(3, 7, 16)
List(4, 8, 9)
(RDD依赖图:coalesce(3,flase))

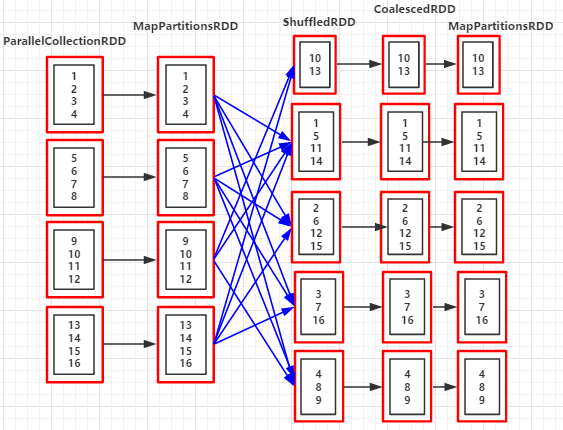
//省略
val rdd = sc.parallelize(1 to 16,4)
val glomRDD = rdd.glom() //RDD[Array[T]]
glomRDD.foreach(rdd => println(rdd.getClass.getSimpleName))
sc.stop
int[] //说明RDD中的元素被转换成数组Array[Int]
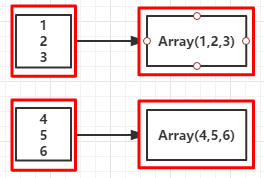

//省略sc
val rdd = sc.parallelize(1 to 10)
val randomSplitRDD = rdd.randomSplit(Array(1.0,2.0,7.0))
randomSplitRDD(0).foreach(x => print(x +" "))
randomSplitRDD(1).foreach(x => print(x +" "))
randomSplitRDD(2).foreach(x => print(x +" "))
sc.stop
2 4
3 8 9
1 5 6 7 10
5.
Spark函数详解系列之RDD基本转换的更多相关文章
- ThinkPHP函数详解系列
为了能方便大家学习和掌握,在这里汇总下ThinkPHP中的经典函数用法 A 函数:实例化控制器R 函数:直接调用控制器的操作方法C 函数:设置和获取配置参数L 函数:设置和获取语言变量D 函数:实例化 ...
- spark wordcont Spark: sortBy和sortByKey函数详解
//统计单词top10def main(args: Array[String]): Unit = { val conf = new SparkConf().setAppName("tst&q ...
- PHP输出缓存ob系列函数详解
PHP输出缓存ob系列函数详解 ob,输出缓冲区,是output buffering的简称,而不是output cache.ob用对了,是能对速度有一定的帮助,但是盲目的加上ob函数,只会增加CPU额 ...
- C++ list容器系列功能函数详解
C++ list函数详解 首先说下eclipse工具下怎样debug:方法:你先要设置好断点,然后以Debug方式启动你的应用程序,不要用run的方式,当程序运行到你的断点位置时就会停住,也会提示你进 ...
- Spark:常用transformation及action,spark算子详解
常用transformation及action介绍,spark算子详解 一.常用transformation介绍 1.1 transformation操作实例 二.常用action介绍 2.1 act ...
- JDBC详解系列(三)之建立连接(DriverManager.getConnection)
在JDBC详解系列(一)之流程中,我将数据库的连接分解成了六个步骤. JDBC流程: 第一步:加载Driver类,注册数据库驱动: 第二步:通过DriverManager,使用url,用户名和密码 ...
- Android高效率编码-第三方SDK详解系列(三)——JPush推送牵扯出来的江湖恩怨,XMPP实现推送,自定义客户端推送
Android高效率编码-第三方SDK详解系列(三)--JPush推送牵扯出来的江湖恩怨,XMPP实现推送,自定义客户端推送 很久没有更新第三方SDK这个系列了,所以更新一下这几天工作中使用到的推送, ...
- Spark参数详解 一(Spark1.6)
Spark参数详解 (Spark1.6) 参考文档:Spark官网 在Spark的web UI在"Environment"选项卡中列出Spark属性.这是一个很有用的地方,可以检查 ...
- 【转载】C语言itoa()函数和atoi()函数详解(整数转字符C实现)
本文转自: C语言itoa()函数和atoi()函数详解(整数转字符C实现) 介绍 C语言提供了几个标准库函数,可以将任意类型(整型.长整型.浮点型等)的数字转换为字符串. int/float to ...
随机推荐
- HDOJ 1316 How Many Fibs?
JAVA大数.... How Many Fibs? Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Jav ...
- Cortex-A9 PWM Timer
PWM定时器 4412时钟为我们提供了PWM定时器,在4412中共有5个32位的定时器,这些定时器可发送中断信号给ARM子系统.另外,定时器0.1.2.3包含了脉冲宽度调制(PWM),并 ...
- ListView小坑
ListView的addHeaderView()和addFooterView()方法需要“Call this before calling setAdapter”,否则崩溃. 但是在KITKAT(ap ...
- C#调用进程
Process process = new Process(); process.StartInfo.FileName = "123.exe"; process.StartInfo ...
- 用document.onreadystatechange和document.readyState确保文档加载完毕才获取DOM
document.onreadystatechange = function(){ //document.readyState有“interactive”和“complate”两个值 if(docum ...
- 第一次碰到try-except(core python programming 2nd Edition 3.6)
# coding: utf-8 # 使用Windows系统,首行'#!/usr/bin/env Pyton'无用,全部改为'# coding: utf-8' 'readtextfile.py -- r ...
- Monkey and Banana(HDU 1069 动态规划)
Monkey and Banana Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others ...
- 如何实现SQL事务的提交,又不对外进行污染
一.以下是本人的一点思路: 1.在事务方法中,参数运用委托Func,选用Func 的原因是多入参,单一出参2.事务传参运用泛型,选用泛型的原因是可以减少代码量,类型安全 二.说明中涉及4个类:1.Or ...
- NPM下载出错 No compatible version found
前言 NPM大家都熟,天天都在用.最近,NPM不断出现的下载出错 “npm ERR! Error: No compatible version found” ,已经影响到正常的开发工作,到了不得不解决 ...
- Scala学习笔记--隐式转换
隐式转换的规则:1.无歧义规则:隐式转换唯有不存在其他可插入转换的前提下才能插入 若编译器有两种方法修正x+y 如convert1(x)+y,convert2(x)+y,会报错2.单一调用规则:只尝 ...