《机实战》第2章 K近邻算法实战(KNN)
1.准备:使用Python导入数据
1.创建kNN.py文件,并在其中增加下面的代码:
from numpy import * #导入科学计算包
import operator #运算符模块,k近邻算法执行排序操作时将使用这个模块提供的函数 def createDataSet():
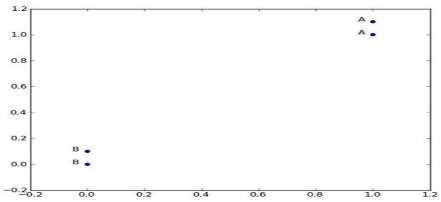
group=array([[1.0,1.1],[1.0,1.0],[0,0],[0,0.1]])
labels=['A','A','B','B']
return group,labels
##print(createDataSet())
2.在knn.py保存处,shift+右键——‘在此处打开命令窗口’,输入:python,再输入:import knn,导入刚编辑的knn.py模块:
>>> python
>>> import knn
3.为了确保输入相同的数据集,knn模块中定义了函数createDataSet,在Python命令提示符下输入下属命令:
>>> group,labels = knn.createDataSet()
4.再输入group,labels查看是否正确赋值:
>>> group '''
显示:
array([[1. , 1.1],
[1. , 1. ],
[0. , 0. ],
[0. , 0.1]])
'''
>>> labels #显示:['A', 'A', 'B', 'B']
5.上代码解析的数据如下图,array表示数据的定位,labels表示数据的对应分类
2.实施kNN分类算法
A.2-1函数伪代码:
对未知类别属性的数据集中的每个点依次执行以下操作:
1. 计算已知类别数据集中的点与当前点之间的距离;【测距】
2. 按照距离递增次序排序;【距离排序】
3. 选取与当前点距离最小的k个点;【选最小K个点】
4. 确定前k个点所在类别的出现频率;【k个点所在类别】
5. 返回前k个点出现频率最高的类别作为当前点的预测分类。【返回类别】
B.函数真正代码:
from numpy import * #导入科学计算包
import operator #运算符模块,k近邻算法执行排序操作时将使用这个模块提供的函数
def classify0(inX, dataSet, labels, k):
dataSetSize = dataSet.shape[0] #得到数据集行数
#print(dataSetSize) #结果:4
#❶(以下三行)距离计算
diffMat = tile(inX, (dataSetSize,1)) - dataSet #把待求值转为 (datasetsize列,1行)-训练集
#print(tile(inX, (dataSetSize,1))) #结果:[[2 1][2 1][2 1][2 1]]
#print(diffMat) #结果:[[ 1. -0.1] [ 1. 0. ] [ 2. 1. ] [ 2. 0.9]] sqDiffMat = diffMat**2 #求上式结果的平方
#print(sqDiffMat) #结果:[[1. 0.01] [1. 0. ] [4. 1. ] [4. 0.81]] sqDistances = sqDiffMat.sum(axis=1) #axis=0是按照行求和,axis=1是按照列进行求和
#print(sqDistances) #结果:[1.01 1. 5. 4.81] distances = sqDistances**0.5 #开根号
#print(distances) #结果[1.00498756 1. 2.23606798 2.19317122] sortedDistIndicies = distances.argsort()#把向量中每个元素进行排序,而它的结果是元素的索引形成的向量
#print(sortedDistIndicies)#结果:[1 0 3 2] classCount={}
#❷ (以下两行)选择距离最小的k个点
for i in range(k):
voteIlabel = labels[sortedDistIndicies[i]]
#print(voteIlabel) #结果:两次A classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1
#print(classCount[voteIlabel]) #结果:计数1,2 #❸ 排序。此处的排序为逆序,即按照从最大到最小次序排序 (注意,python3.5以上版本,原classCount.iteritems()变为classCount.items())
sortedClassCount = sorted(classCount.items(),key=operator.itemgetter(1), reverse=True)
#print(sortedClassCount) #结果:[('A', 2)] print(sortedClassCount[0][0]) #结果:A.返回发生频率最高的元素标签
return sortedClassCount[0][0] classify0((2,1),array([[1.0,1.1],[1.0,1.0],[0,0],[0,0.1]]),['A','A','B','B'],3)
解释:函数参数:
- inX:待分类数据
- dataSet:训练集
- labels:与训练集一一对应的标签
- k:要选取的 前k个值
解释❶
♥tile函数:
我们知道inX是个向量,而dataset是个矩阵,两者之间要进行相减的运算,需要把这个向量也补成一个和dataset有相同行数列数的矩阵,怎么个补法呢。这就要看tile()的第二个参数了,也就是上面的(datasetsize,1),这个参数的意思就是把inX补成有datasetsize行数的矩阵。然后和dataset相减就是根据矩阵的减法进行的
例:假如 inX是(1,2) datasetsize =3 那么经过 tile()转换后产生了一个这样的矩阵([1,2],[1,2],[1,2])
♠计算距离:
用【欧氏距离公式】,计算两个向量点xA和xB之间的距离:(xB0,xB1)和(xA0,xA1)
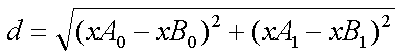
例1.如点(0, 0)与(1, 2)之间的距离计算为:
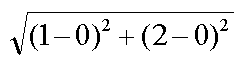
例2.如果数据集存在4个特征值,则点(1, 0, 0, 1)与(7, 6, 9, 4)之间的距离计算为:
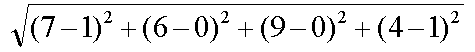
♠ sqdiffMat.sum(axis = 1)函数
假如sqdiffMat是([1,2],[0,1],[3,4])关注下axis这个参数,它影响了你对矩阵求和时候的顺序,axis=0是按照行求和,axis=1是按照列进行求和,因此这样的求和结果就是([4,7])
♠ argsort()函数
这个函数的作用很简单,就是把向量中每个元素进行排序,而它的结果是元素的索引形成的向量。sorted()函数返回的是一个list。
例如:
distance是这么个东西------([1,4,3])
经过distance.argsort()之后的结果是([0,2,1])
整合,并运行一下:
from numpy import * #导入科学计算包
import operator #运算符模块,k近邻算法执行排序操作时将使用这个模块提供的函数 def createDataSet():
group=array([[1.0,1.1],[1.0,1.0],[0,0],[0,0.1]])
labels=['A','A','B','B']
return group,labels
##print(createDataSet()) def classify0(inX, dataSet, labels, k):
dataSetSize = dataSet.shape[0] #得到数据集行数
#print(dataSetSize) #结果:4
#❶(以下三行)距离计算
diffMat = tile(inX, (dataSetSize,1)) - dataSet #把待求值转为 (datasetsize列,1行)-训练集
#print(tile(inX, (dataSetSize,1))) #结果:[[2 1][2 1][2 1][2 1]]
#print(diffMat) #结果:[[ 1. -0.1] [ 1. 0. ] [ 2. 1. ] [ 2. 0.9]] sqDiffMat = diffMat**2 #求上式结果的平方
#print(sqDiffMat) #结果:[[1. 0.01] [1. 0. ] [4. 1. ] [4. 0.81]] sqDistances = sqDiffMat.sum(axis=1) #axis=0是按照行求和,axis=1是按照列进行求和
#print(sqDistances) #结果:[1.01 1. 5. 4.81] distances = sqDistances**0.5 #开根号
#print(distances) #结果[1.00498756 1. 2.23606798 2.19317122] sortedDistIndicies = distances.argsort()#把向量中每个元素进行排序,而它的结果是元素的索引形成的向量
#print(sortedDistIndicies)#结果:[1 0 3 2] classCount={}
#❷ (以下两行)选择距离最小的k个点
for i in range(k):
voteIlabel = labels[sortedDistIndicies[i]]
#print(voteIlabel) #结果:两次A classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1
#print(classCount[voteIlabel]) #结果:计数1,2 #❸ 排序。 3.5以上版本,原classCount.iteritems()变为classCount.items()
sortedClassCount = sorted(classCount.items(),key=operator.itemgetter(1), reverse=True)
#print(sortedClassCount) #结果:[('A', 2)] #print(sortedClassCount[0][0]) #结果:A
return sortedClassCount[0][0]
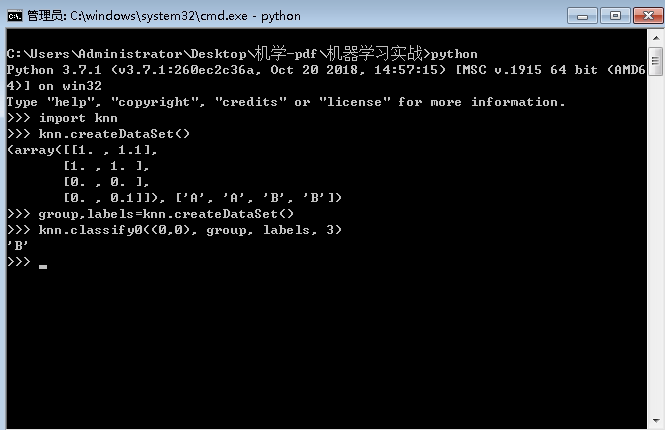
运行:进入文件所在目录:knn.py保存处,shift+右键——‘在此处打开命令窗口’,输入:python,然后输入:
C:\Users\Administrator\Desktop\机学-pdf\机器学习实战>python
Python 3.7.1 (v3.7.1:260ec2c36a, Oct 20 2018, 14:57:15) [MSC v.1915 64 bit (AMD6
4)] on win32
Type "help", "copyright", "credits" or "license" for more information. >>> import knn #导入文件
>>> knn.createDataSet() #调用数据集创建函数,创建数据
(array([[1. , 1.1],
[1. , 1. ],
[0. , 0. ],
[0. , 0.1]]), ['A', 'A', 'B', 'B']) >>> group,labels=knn.createDataSet() #把返回的值分别赋值给group,labels >>> knn.classify0((0,0), group, labels, 3) #运行分类函数,返回预测分类B
'B'
>>>
《机实战》第2章 K近邻算法实战(KNN)的更多相关文章
- 《机器学习实战》---第二章 k近邻算法 kNN
下面的代码是在python3中运行, # -*- coding: utf-8 -*- """ Created on Tue Jul 3 17:29:27 2018 @au ...
- 【机器学习】k近邻算法(kNN)
一.写在前面 本系列是对之前机器学习笔记的一个总结,这里只针对最基础的经典机器学习算法,对其本身的要点进行笔记总结,具体到算法的详细过程可以参见其他参考资料和书籍,这里顺便推荐一下Machine Le ...
- 数据挖掘算法(一)--K近邻算法 (KNN)
数据挖掘算法学习笔记汇总 数据挖掘算法(一)–K近邻算法 (KNN) 数据挖掘算法(二)–决策树 数据挖掘算法(三)–logistic回归 算法简介 KNN算法的训练样本是多维特征空间向量,其中每个训 ...
- 机器学习之K近邻算法(KNN)
机器学习之K近邻算法(KNN) 标签: python 算法 KNN 机械学习 苛求真理的欲望让我想要了解算法的本质,于是我开始了机械学习的算法之旅 from numpy import * import ...
- 1. K近邻算法(KNN)
1. K近邻算法(KNN) 2. KNN和KdTree算法实现 1. 前言 K近邻法(k-nearest neighbors,KNN)是一种很基本的机器学习方法了,在我们平常的生活中也会不自主的应用, ...
- 《机器学习实战》中的程序清单2-1 k近邻算法(kNN)classify0都做了什么
from numpy import * import operator import matplotlib import matplotlib.pyplot as plt from imp impor ...
- 第2章 K近邻算法
numpy中的tile函数: 遇到numpy.tile(A,(b,c))函数,重复复制A,按照行方向b次,列方向c次. >>> import numpy >>> n ...
- 《机器学习实战》读书笔记—k近邻算法c语言实现(win下)
#include <stdio.h> #include <io.h> #include <math.h> #include <stdlib.h> #de ...
- R语言学习笔记—K近邻算法
K近邻算法(KNN)是指一个样本如果在特征空间中的K个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性.即每个样本都可以用它最接近的k个邻居来代表.KNN算法适 ...
随机推荐
- 吴裕雄--天生自然JAVAIO操作学习笔记:File类
import java.io.File ; import java.io.IOException ; public class FileDemo01{ public static void main( ...
- NO29 用户提权sudo配置文件详解实践--志行为审计
用户提权sudo配置文件详解实践: 放到visudo里: 验证权限:
- Linux 安装 go 以及 arm linux 移植 go
背景 Go是一门全新的静态类型开发语言,具有自动垃圾回收,丰富的内置类型,函数多返回值,错误处理,匿名函数,并发编程,反射等特性. 从Go1.4之后Go语言的编译器完全由Go语言编写,所以为了从源代码 ...
- helloctf.exe ----攻防世界
下载附件之后,查壳发现没有壳,运行试试看 很平常的输入代码,然后ida查看一下,开始就发现一个注意的地方,但是还是继续向下看, 结果就是CrackMeJustForFun
- java#类的实例化顺序
关于类的实例化,不用弄的那么细致,这里只说单一类,没有其他父类(排除Obejct)的情况.要实例化一个类,需要加载class文件到jvm并且验证通过了是安全的字节码文件. 初始化大致上是按照如下步骤: ...
- html5,css3炫酷实例-元素
自动完成输入框下拉列表 使用的插件:jquery-ui 使用数据源实现文本框的自动完成功能 <link href="https://cdn.bootcss.com/jqueryui/1 ...
- 循环的N种写法
protype,json都算进去 先总结一下 伪数组的循环方式有,for,for-of 数组的循环方式有for,forEach,map,filter,find,some,every,reduce,fo ...
- Java If ... Else
章节 Java 基础 Java 简介 Java 环境搭建 Java 基本语法 Java 注释 Java 变量 Java 数据类型 Java 字符串 Java 类型转换 Java 运算符 Java 字符 ...
- 如何用hugo搭建个人博客
如何用hugo搭建个人博客 1. 安装 Hugo 点击跳转 Hugo Releases win10 步骤: 下载解压 , 然后添加环境变量 测试: #命令行测试 hugo version 2. 创建站 ...
- PHP页面跳转以及伪登录实例
PHP页面跳转一.header()函数header()函数是PHP中进行页面跳转的一种十分简单的方法.header()函数的主要功能是将HTTP协议标头(header)输出到浏览器. header() ...