Flink| 实时需要分析
========================实时流量统计
1. 实时热门商品HotItems
每隔 5 分钟输出最近一小时内点击量最多的前 N 个商品。
抽取出业务时间戳,告诉 Flink 框架基于业务时间做窗口
• 过滤出点击行为数据
• 按一小时的窗口大小,每 5 分钟统计一次,做滑动窗口聚合( Sliding Window)
• 按每个窗口聚合,输出每个窗口中点击量前 N 名的商品
2. 实时流量统计 NetworkFlow
"实时流量统计" 对于一个电商平台而言,用户登
录的入口流量、不同页面的访问流量 都是值得分析的重要数据,而这些数据,可以
简单地从 web 服务器的日志中提取出来。 实现"热门页面浏览数"的统计,也就是读取服务器日志中的每
一行log统计在一段时间内用户访问每一个url的次数,然后排序输出显示。
具体做法为:
每隔 5 秒,输出最近 10 分钟内访问 量最多的前 N 个 URL。可以看出,这个需求与之前“实时热门商品统计”非常类似,
所以我们完全可以借鉴此前的代码。
3. PV 网站页面流量 - PageView
衡量网站流量一个最简单的指标,就是网站的页面浏览量(Page View PV );
用户每次打开一个页面便记录 1 次 PV ,多次打开同一页面则浏览量累计。一般来说PV 与来访者的数量成正比,但是 PV 并不直接决定页面的真实来访者数量,
如同一个来访者通过不断的刷新页面,也可以制造出非常高的 PV 。
我们知道,用户浏览页面时,会从浏览器向网络服务器 发出一个请求 Request网络服务器接到这个请求后,会将该请求对应的一个网页( Page )发送给浏览器
从而产生了一个 PV。所以我们的统计方法,可以是从 web 服务器的日志中去提取对应的页面访问然后统计,就向上一节中的做法一样;也可以直接从埋点日志中提
取用户发来的页面请求,从而统计出总浏览量。 实现一个网站总浏览量的统计。可以设置滚动时间窗口,实时统计每小时内的网站 PV
4. UV 独立访客数
* 上例中,我们统计的是所有用户对页面的所有浏览行为,也就是说,同一用户的浏览行为会被重复统计。而在实际应用中,我们往往还会关注,在一段
* 时间内到底有多少不同的用户访问了网站。另外一个统计流量的重要指标是网站的独立访客数(Unique Visitor UV )。 UV指的是一段时间(比如一小时)内访问网站 的 总人数, 1 天内同一访客的多次访问
* 只记录为一个访客。通过 IP 和 cookie 一般 是判断 UV 值的两种方式。 当客户端第一次访问某个网站服务器的时候,网站服务器会给这个客户端的电脑发出 一个 Cookie
* 通常放在这个客户端电脑的 C 盘当中。在这个 Cookie 中会分配一个独一无二的编号,这其中会记录一些访问服务器的信息,如访问时间,访问了哪些页面等等。当你下次再访问这个服务器的时候,服务器就可以直接从你的电脑中找到上一次放进去的
* Cookie 文件,并且对其进行一些更新,但那个独一无二的编号是不会变的。
* 此例中可以根据 userId 来区分不同的用户。
5. 使用布隆过滤器查重-过滤的UV统计
/**
* 上例中,把所有数据的userId 都存在了窗口计算的状态里,在窗口收集数据的过程中,状态会不断增大。一般情况下,只要不超出内存的承受范围,
* 这种做法也没什么问题;但如果我们遇到的数据量很大呢?把所有数据暂存放到内存里,显然不是一个好注意。我们会想到,可以利用 redis这种内存级 k v 数据库,为我们做一个缓存。
* 但如果我们遇到的情况非常极端,数据大到惊人呢?比如上亿级的用户,要去重计算 UV 。
* 如果放到redis 中,亿级的用户id (每个 20 字节左右的话)可能需要几G甚至几十G的空间来存储。当然放到 redis 中,用集群进行扩展也不是不可以,但明显
* 代价太大了。一个更好的想法是,其实我们不需要完整地存储用户ID 的信息,只要知道他在不在就行了。所以其实我们可以进行压缩处理,用一位( bit )就可以表示一个用户
* 的状态。这个思想的具体实现就是布隆过滤器( Bloom Filter )。
* 本质上布隆过滤器是一种数据结构,比较巧妙的概率型数据结构(probabilisticdata structure ),特点是高效地插入和查询,可以用来告诉你 “某样东西一定不存在或者可能存在”。
* 它本身是一个很长的二进制向量,既然是二进制的向量,那么显而易见的,存放的不是 0 ,就是 1 。 相比于传统的 List 、 Set 、 Map 等数据结构,它更高效、占用空间更少,
* 但是缺点是其返回的结果是概率性的,而不是确切的。
* 我们的目标就是,利用某种方法(一般是Hash 函数)把每个数据,对应到一个位图的某一位上去;如果数据存在,那一位就是1,不存在则为 0 。
*/

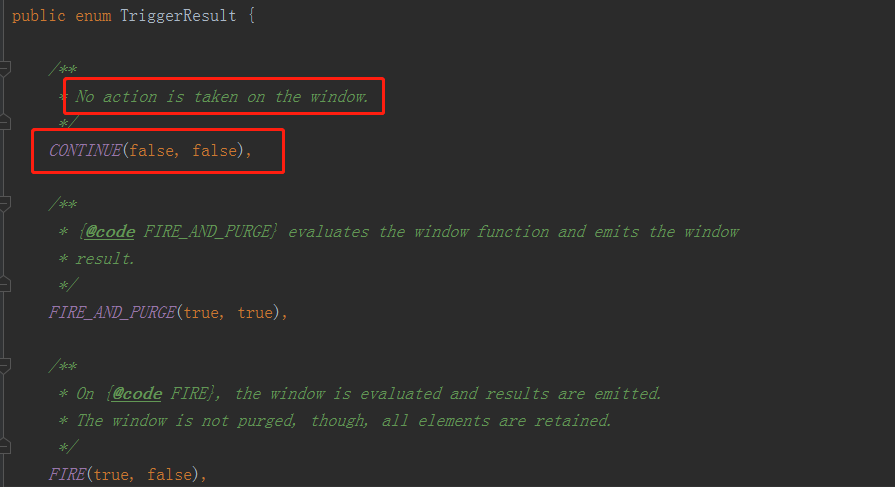
判断当前最大的时间戳 <= 当前的watermark,就返回一个TriggerResult.FIRE(触发);否则就注册一个定时器(关窗的操作)
TriggerResult的类型:CONTINUE-什么都不做继续处理窗口;FIRE触发窗口的计算操作但并不会关闭窗口清除它的状态;PURGE清除窗口的状态;FIRE_AND_PURGE触发并清除掉;


redis:

==========================市场营销商业指标统计分析===========
* 对于电商企业来说,一般会通过各种不同的渠道对自己的APP进行市场推广,而这些渠道的统计数据(比如,不同网站上广告链接的点击量、APP下载量)就成了市场营销的重要商业指标。
* 首先考察分渠道的市场推广统计。
* 需要自定义一个测试源SimulatedEventSource来生成用户行为的事件流。
*1. 分渠道统计 AppMarketingByChannel.scala
/**
* 2. 不分渠道(总量)统计
* 同样我们还可以考察不分渠道的市场推广统计,这样得到的就是所有渠道推广的总量 AppMarketing.scala 。
* /
/**
* 电商网站的市场营销商业指标中,除了自身的APP 推广,还会考虑到页面上的广告投放(包括自己经营的产品和其它网站的广告)。 所以广告相关的统计分析,也是市场营销的重要指标。
* 对于广告的统计,最简单也最重要的就是页面广告的点击量,网站往往需要根据广告点击量来制定定价策略和调整推广方式,而且也可以借此收集用户的偏好信息。
* 更加具体的应用是,我们可以根据用户的地理位置进行划分,从而总结出不同省份用户对不同广告的偏好,这样更有助于广告的精准投放。
* 3. 页面广告点击量统计
* 接下来我们就进行页面广告按照省份划分的点击量的统计。AdStatisticsByGeo .scala 文件 。
* 自定义一些测试数据AdClickLog,用来生成用户点击广告行为的事件流。
* 主函数以 province 进行 keyBy ,然后开一小时的时间窗口,滑动距离为5秒,统计窗口内的点击事件数量。
*
* 广告点击量统计,同一用户的重复点击是会叠加计算的。在实际场景中,同一用户确实可能反复点开同一个广告,这也说明了用户对广告更大的兴趣;
* 但是如果用户在一段时间非常频繁地点击广告,这显然不是一个正常行为,有刷点击量的嫌疑。所以我们可以对一段时间内(比如一天内)的用户点击行为进行约束,
* 如果对同一个广告点击超过一定限额(比如 100 次),应该把该用户加入黑名单并报警,此后其点击行为不应该再统计。
* 4. 黑名单过滤
==========================恶意登录监控==================
* 对于网站而言,用户登录并不是频繁的业务操作。如果一个用户短时间内频繁登录失败,就有可能是出现了程序的恶意攻击,比如密码暴力破解。因此我们考虑,
* 应该对用户的登录失败动作进行统计,具体来说,如果同一用户(可以是不同 IP)在2秒之内连续两次登录失败,就认为存在恶意登录的风险,输出相关的信息进行
* 报警提示。这是电商网站、也是几乎所有 网站风控的基本一环。
* 1. 状态编程的方式实现:LoginFail .scala
* 由于同样引入了时间,我们可以想到,最简单的方法其实与之前的热门统计类似,只需要按照用户 ID 分流,然后遇到登录失败的事件时将其保存在 ListState 中,
* 然后设置一个定时器,2秒后触发。定时器触发时检查状态中的登录失败事件个数,如果大于等于2,那么就输出报警信息。
*
* 新建一个单例对象。 定义样例类LoginEvent ,这是输入的登录事件流。登录数据本应该从UserBehavior日志里提取
* 由于UserBehavior.csv中没有做相关埋点,从另一个文件 LoginLog.csv 中读取登录数据 。
*
*
* 2. 优化操作:
* 第一次的代码实现中我们可以看到,直接把每次登录失败的数据存起来、设置定时器一段时间后再读取,这种做法尽管简单,但和我们开始的需求还是略有差异
* 的。这种做法只能隔 2 秒之后去判断一下这期间是否有多次失败登录,而不是在一次登录失败之后、再一次登录失败时就立刻报警。这个需求如果严格实现起来,相
* 当于要判断任意紧邻的事件,是否符合某种模式。于是我们可以想到,这个需求其实可以不用定时器触发,直接在状态中存取上一次登录失败的事件,每次都做判断和比对,就可以实现最初的需求。
* 在代码MatchFunction中删掉onTimer processElement
*
* 我们通过对状态编程的改进,去掉了定时器,在 process function 中做了
* 更多的逻辑处 理,实现了最初的需求。不过这种方法里有很多的条件判断,目前仅仅实现的是检测“连续2次登录失败”,这是最简单的情形。
* 如果需要检测更多次,内部逻辑显然会变得非常复杂。那有什么方式可以方便地实现呢?
* flink为我们提供了CEP Complex Event Processing ,复杂事件处理库,用于在流中筛选符合某种复杂模式的事件。
* 3. 基于 CEP 来完成这个模块的实现。
========================订单支付实时监控=========================
在电商网站中,订单的支付作为直接与营销收入挂钩的一环,在业务流程中非常重要。对于订单而言,为了正确控制业务流程,也为了增加用户的支付意愿,网
站一般会设置一个支付失效时间,超过一段时间不支付的订单就会被取消。另外,对于订单的支付,我们还应保证用户支付的正确性,这可以通过第三方支付平台的
对于订单的支付,我们还应保证用户支付的正确性,这可以通过第三方支付平台的交易数据来做一个实时对账。
将实现这两个需求。交易数据来做一个实时对账。
* 在电商平台中最终创造收入和利润的是用户下单购买的环节;更具体一点,是用户真正完成支付动作的时候。用户下单的行为可以表明用户对商品的需求,但
* 在现实中,并不是每次下单都会被用户立刻支付。当拖延一段时间后,用户支付的意愿会降低。所以为了让用户更有紧迫感从而提高支付转化率,同时也为了防范订
* 单支付环节的安全风险,电商网站往往会对订单状态进行监控,设置一个失效时间(比如 15 分钟),如果下单后一段时间仍未支付,订单就会被 取消。
* 使用 CEP 实现
* 利用 CEP 库来实现这个功能。我们先将事件流按照订单号orderId分流,
* 定义这样的一个事件模式:在15分钟内,事件“create”与pay非严格紧邻,这样调用.select 方法时,就可以同时获取到匹配出的事件和超时未匹配的事件。
* 1. CEP实现订单超时报警
* 2. 用状态编程来实现:
* 我们同样可以利用Process Function ,自定义实现检测订单超时的功能。为了简化问题,我们只考虑超时报警的情形,在 pay 事件超时未发生的情况下,输出超时报警信息。
* 一个简单的思路是,可以在订单的create 事件到来后注册定时器,15分钟后触发;然后再用一个布尔类型的 Value 状态来作为标识位,表明 pay 事件是否发生过。
* 如果 pay 事件已经发生,状态被置为 true ,那么就不再需要 做什么操作;而如果 pay事件一直没来,状态一直为 false,到定时器触发时,就应该输出超时报警信息。
* 现在只考虑两种情况:①来一个create,来一个pay create后边有pay就正常匹配,如果没来就超时报警
* 乱序的数据,有可能create和pay的先后顺序
* 超时报警的情况: 遇到create设一个定时器,遇到pay改一个状态(或者不删定时器,直接设定一个状态看有没有pay来过,有则定时器触发时说是正常的,没有就超时报警
-----来自两条流的订单交易匹配----------
* 对于订单支付事件,用户支付完成其实并不算完,我们还得确认平台账户上是否到账了。而往往这会来自不同的日志信息,所以我们要同时读入两条流的数据来
* 做合并处理。这里我们利用 connect 将两条流进行连接,
* 1. 用自定义的CoProcessFunction 进行处理。
* 2. 双流join
* window join(Tumbling Window Join、 Sliding Window Join)适用于两条流join,后边还要开窗口的分析
*Interval join(区间join)适用于传感器报警(温度烟雾出现异常,它俩时间得匹配上在同一时间范围内同时出现,温度又升高的很快)
* Join中当做状态保存起来
*此需求是两条流匹配上就可以了
统计类:读取数据、做简单包装转换map、filter、按某个字段分组,开窗,做聚合
排序| TopN:再做一个ProcessFunction,把所有数据都收集到排序输出;
以上是基于DataStreamAPI,也可以用高级API、TableAPI和FlinkSQL
业务流程中的状态做检测输出和警告:自定义编程、状态
事件逻辑、风控:CEP
Flink| 实时需要分析的更多相关文章
- 基于Xenomai的实时Linux分析与研究
转自:http://blog.csdn.net/cyberlabs/article/details/6967192 引 言 随着嵌入式设备的快速发展,嵌入式设备的功能和灵活性要求越来越高,很多嵌入式设 ...
- 【转】ELK(ElasticSearch, Logstash, Kibana)搭建实时日志分析平台
[转自]https://my.oschina.net/itblog/blog/547250 摘要: 前段时间研究的Log4j+Kafka中,有人建议把Kafka收集到的日志存放于ES(ElasticS ...
- Hermes实时检索分析平台
一.序言 随着TDW的发展,公司在大数据离线分析方面已经具备了行业领先的能力.但是,很多应用场景往往要求在数秒内完成对几亿.几十亿甚至几百上千亿的数据分析,从而达到不影响用户体验的目的.如何能够及时有 ...
- Hermes:来自腾讯的实时检索分析平台
实时检索分析平台(Hermes)是腾讯数据平台部为大数据分析业务提供一套实时的.多维的.交互式的查询.统计.分析系统,为各个产品在大数据的统计分析方面提供完整的解决方案,让万级维度.千亿级数据下的秒级 ...
- Flink源码分析 - 源码构建
原文地址:https://mp.weixin.qq.com/s?__biz=MzU2Njg5Nzk0NQ==&mid=2247483692&idx=1&sn=18cddc1ee ...
- 苏宁基于Spark Streaming的实时日志分析系统实践 Spark Streaming 在数据平台日志解析功能的应用
https://mp.weixin.qq.com/s/KPTM02-ICt72_7ZdRZIHBA 苏宁基于Spark Streaming的实时日志分析系统实践 原创: AI+落地实践 AI前线 20 ...
- ELK实时日志分析平台环境部署--完整记录
在日常运维工作中,对于系统和业务日志的处理尤为重要.今天,在这里分享一下自己部署的ELK(+Redis)-开源实时日志分析平台的记录过程(仅依据本人的实际操作为例说明,如有误述,敬请指出)~ ==== ...
- 【Big Data - ELK】ELK(ElasticSearch, Logstash, Kibana)搭建实时日志分析平台
摘要: 前段时间研究的Log4j+Kafka中,有人建议把Kafka收集到的日志存放于ES(ElasticSearch,一款基于Apache Lucene的开源分布式搜索引擎)中便于查找和分析,在研究 ...
- [Big Data - ELK] ELK(ElasticSearch, Logstash, Kibana)搭建实时日志分析平台
ELK平台介绍 在搜索ELK资料的时候,发现这篇文章比较好,于是摘抄一小段: 以下内容来自: http://baidu.blog.51cto.com/71938/1676798 日志主要包括系统日志. ...
随机推荐
- vue_相同组件,不同url跳转不重新渲染的解决方法
最近写的这个项目,有很多下拉菜单,每个菜单会有相应的两种类型.现在产品的需求是,跳转到不同的类型 需要页面重新渲染数据 那么问题来了. 我试了好几种方法,用watch监听路由去判断,但是发现输在inp ...
- IntelliJ IDEA神器使用技巧
说明:详情请参考慕课网课程:IntelliJ IDEA神器使用技巧:http://www.imooc.com/learn/924(感谢课程作者:闪电侠) 推荐: 1. 课程老师(闪电侠)IDEA快捷键 ...
- xcode制作越狱包
1.将运行目标选为iOS Device 2.Edit Scheme -> 选择 Run [App Name] -> Build Configuration下拉框中选择Release 3.生 ...
- Sublime text 3 运行python3
要在Sublime text3编译器中成功运行 python3,需要在编译器设置中将python3添加至编译器中 新建编译系统 编辑弹出的文件,添加如下内容: { "cmd":[& ...
- Simulink仿真入门到精通(二) Simulink模块
2.1 Simulink模块的组成要素 用户构建系统模型时无需直接面对成千上万行的代码,而是通过模块化图形界面以模块化的方式构建,能够使理解变得容易,让大脑减负.通过层次化模块分布将系统功能模块化,而 ...
- 搭建Java开发环境之配置环境变量
前言 初学Java不久的二胖在搭建Java开发环境一步就遇到问题,他不由得感叹:万事开头难啊!但感叹之后它还是鼓足了劲去努力解决它,二胖在电脑上Google了一番,最终环境是搭建成功了,但他心中对&q ...
- Spark实战--搭建我们的Spark分布式架构
Spark的分布式架构 如我们所知,spark之所以强大,除了强大的数据处理功能,另一个优势就在于良好的分布式架构.举一个例子在Spark实战--寻找5亿次访问中,访问次数最多的人中,我用四个spar ...
- django 和 七牛云 交互
django 和 七牛云 交互 七牛开发文档 安装 pip install qiniu 初始化 # access_key 个人中心的 ak # secret_key 个人中心的 sk from qin ...
- vscode 自动修复 setting.json 修改完,得重启浏览器 # 新版(>1.41.0)配置 vscode #解决了
vscode 自动修复 setting.json 修改完,得重启浏览器,不用 npm run dev 就能看到效果 "editor.codeActionsOnSave": { &q ...
- 0402数据放入集合进行查询-Java(新手)
JDBC工具类: package cn.Wuchang.zyDome; import java.sql.*; public class JDBCUtils { private static final ...