数据结构之栈(Stack)
什么是栈(Stack)

实现和操作概述
栈的主要操作有以下5种
栈的实现
疑问
|
|
数组
|
链表
|
|
内存浪费
|
无浪费
|
有浪费:需存如额外引用信息 |
|
动态
|
非动态:大小无法运行时随意变动
|
动态的:可以随意增加或缩小
|
|
push操作
|
当数组大小超过时,需要扩容O(n)。
数组大小足够时,直接push完成 O(1)
|
直接链表首部插入O(1). 但需新建节点
|
单链表实现
public class StackTest<E> {
public static void main(String[] args) {
StackTest<Integer> stackTest = new StackTest<>();
for (int i = 4; i > 0; i--) {
System.out.println("push:" + stackTest.push(Integer.valueOf(i)).intValue());
}
System.out.println("peek:" + stackTest.peek());
System.out.println("pop:" + stackTest.pop());
System.out.println("isEmpty:" + stackTest.isEmpty());
for (int i = 4; i > 0; i--) {
System.out.println("search " + i + ":" + stackTest.search(Integer.valueOf(i)));
}
}
//栈顶定义
StackNode<E> top;
//节点定义:
static class StackNode<E> {
E data;
StackNode<E> next;
StackNode(E data, StackNode<E> next) {
this.data = data;
this.next = next;
}
}
//向栈顶push一个元素,即向链表首部添加元素
public E push(E data) {
top = new StackNode<E>(data, top);
return top.data;
}
//返回栈顶的值。即链表首部节点的值。
public E peek() {
if (isEmpty())
throw new RuntimeException("fail,stack is null!");
return top.data;
}
//从栈顶pop一个元素,即返回栈顶的值 并删除链表第一个节点。
public E pop() {
E preTopData = peek();
top = top.next;
return preTopData;
}
//判空
public boolean isEmpty() {
return top == null;
}
//查找数据为data的节点位置,栈顶为1.没找到返回-1.
public int search(E data) {
int position = 1;
StackNode<E> currNode = top;
while (currNode != null && !currNode.data.equals(data)) {
position++;
currNode = currNode.next;
}
if (currNode == null)
position=-1;
return position;
}
}

push:4
push:3
push:2
push:1
peek:1
pop:1
isEmpty:false
search 4:3
search 3:2
search 2:1
search 1:-1
栈的数组实现
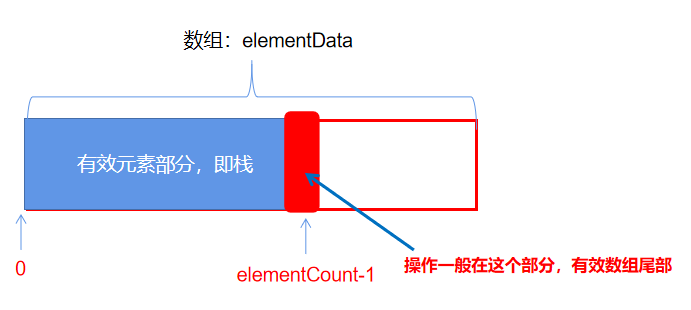
push()操作
public E push(E item) {
addElement(item);
return item;
}
//数组变量定义
protected Object[] elementData;
//有效元素个数,在栈中即表示栈的个数
protected int elementCount;
//当数组溢出时,扩容 增加的大小。
protected int capacityIncrement;
//3种构造方式,默认构造方式的 数组大小初始化为10.
public Vector(int initialCapacity, int capacityIncrement) {
super();
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
this.elementData = new Object[initialCapacity];
this.capacityIncrement = capacityIncrement;
} public Vector(int initialCapacity) {
this(initialCapacity, 0);
} public Vector() {
this(10);
} //增加元素
public synchronized void addElement(E obj) {
modCount++;
ensureCapacityHelper(elementCount + 1);
elementData[elementCount++] = obj;
}
数组扩容
private void ensureCapacityHelper(int minCapacity) {
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + ((capacityIncrement > 0) ?
capacityIncrement : oldCapacity);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
elementData = Arrays.copyOf(elementData, newCapacity);
}
private static int hugeCapacity(int minCapacity) {
if (minCapacity < 0) // overflow
throw new OutOfMemoryError();
return (minCapacity > MAX_ARRAY_SIZE) ?
Integer.MAX_VALUE :
MAX_ARRAY_SIZE;
}
peek()操作
public synchronized E peek() {
int len = size();
if (len == 0)
throw new EmptyStackException();
return elementAt(len - 1);
}
Vector类:
public synchronized int size() {
return elementCount;
}
public synchronized E elementAt(int index) {
if (index >= elementCount) {
throw new ArrayIndexOutOfBoundsException(index + " >= " + elementCount);
}
return elementData(index);
}
@SuppressWarnings("unchecked")
E elementData(int index) {
return (E) elementData[index];
}
pop()操作
public synchronized E pop() {
E obj;
int len = size();
obj = peek();
removeElementAt(len - 1);
return obj;
}
public synchronized void removeElementAt(int index) {
modCount++;
if (index >= elementCount) {
throw new ArrayIndexOutOfBoundsException(index + " >= " +
elementCount);
}
else if (index < 0) {
throw new ArrayIndexOutOfBoundsException(index);
}
int j = elementCount - index - 1;
if (j > 0) {
System.arraycopy(elementData, index + 1, elementData, index, j);
}
elementCount--;
elementData[elementCount] = null; /* to let gc do its work */
}
search()操作
public synchronized int search(Object o) {
int i = lastIndexOf(o);
if (i >= 0) {
return size() - i;
}
return -1;
}
public synchronized int lastIndexOf(Object o) {
return lastIndexOf(o, elementCount-1);
}
public synchronized int lastIndexOf(Object o, int index) {
if (index >= elementCount)
throw new IndexOutOfBoundsException(index + " >= "+ elementCount);
if (o == null) {
for (int i = index; i >= 0; i--)
if (elementData[i]==null)
return i;
} else {
for (int i = index; i >= 0; i--)
if (o.equals(elementData[i]))
return i;
}
return -1;
}
empty()操作
public boolean empty() {
return size() == 0;
}
栈的使用
符号匹配问题
public class StackTest<E> {
public static void main(String[] args) {
System.out.println(symbolMatch("{for(int i=0;i<10;i++)}"));
System.out.println(symbolMatch("[5(3*2)+(2+2)]*(2+0)"));
System.out.println(symbolMatch("([5(3*2)+(2+2))]*(2+0)"));
}
public static boolean symbolMatch(String expression) {
final char CHAR_NULL = ' ';
if (expression == null || expression.equals(""))
throw new RuntimeException("expression is nothing or null");
//StackTest<Character> stack = new StackTest<Character>();
Stack<Character> stack = new Stack<Character>();
char[] exps = expression.toCharArray();
for (int i = 0; i < exps.length; i++) {
char matchRight = CHAR_NULL;
switch (exps[i]) {
case '(':
case '[':
case '{':
stack.push(Character.valueOf(exps[i]));
break;
case ')':
matchRight = '(';
break;
case ']':
matchRight = '[';
break;
case '}':
matchRight = '{';
break;
}
if(matchRight == CHAR_NULL)
continue;
if (stack.isEmpty())
return false;
if (stack.peek().charValue() == matchRight)
stack.pop();
}
if (stack.isEmpty())
return true;
return false;
}
}
true
true
false
数据结构之栈(Stack)的更多相关文章
- Python与数据结构[1] -> 栈/Stack[0] -> 链表栈与数组栈的 Python 实现
栈 / Stack 目录 链表栈 数组栈 栈是一种基本的线性数据结构(先入后出FILO),在 C 语言中有链表和数组两种实现方式,下面用 Python 对这两种栈进行实现. 1 链表栈 链表栈是以单链 ...
- [ACM训练] 算法初级 之 数据结构 之 栈stack+队列queue (基础+进阶+POJ 1338+2442+1442)
再次面对像栈和队列这样的相当基础的数据结构的学习,应该从多个方面,多维度去学习. 首先,这两个数据结构都是比较常用的,在标准库中都有对应的结构能够直接使用,所以第一个阶段应该是先学习直接来使用,下一个 ...
- 数据结构11: 栈(Stack)的概念和应用及C语言实现
栈,线性表的一种特殊的存储结构.与学习过的线性表的不同之处在于栈只能从表的固定一端对数据进行插入和删除操作,另一端是封死的. 图1 栈结构示意图 由于栈只有一边开口存取数据,称开口的那一端为“栈顶”, ...
- Python与数据结构[1] -> 栈/Stack[1] -> 中缀表达式与后缀表达式的转换和计算
中缀表达式与后缀表达式的转换和计算 目录 中缀表达式转换为后缀表达式 后缀表达式的计算 1 中缀表达式转换为后缀表达式 中缀表达式转换为后缀表达式的实现方式为: 依次获取中缀表达式的元素, 若元素为操 ...
- 线性数据结构之栈——Stack
Linear data structures linear structures can be thought of as having two ends, whose items are order ...
- C# 数据结构 栈 Stack
栈和队列是非常重要的两种数据结构,栈和队列也是线性结构,线性表.栈和队列这三种数据结构的数据元素和元素的逻辑关系也相同 差别在于:线性表的操作不受限制,栈和队列操作受限制(遵循一定的原则),因此栈和队 ...
- 【Java数据结构学习笔记之二】Java数据结构与算法之栈(Stack)实现
本篇是java数据结构与算法的第2篇,从本篇开始我们将来了解栈的设计与实现,以下是本篇的相关知识点: 栈的抽象数据类型 顺序栈的设计与实现 链式栈的设计与实现 栈的应用 栈的抽象数据类型 栈是 ...
- 数据结构之栈(stack)
1,栈的定义 栈:先进后出的数据结构,如下图所示,先进去的数据在底部,最后取出,后进去的数据在顶部,最先被取出. 栈常用操作: s=Stack() 创建栈 s.push(item) 将数据item放在 ...
- 数据结构与算法:栈(Stack)的实现
栈在程序设计当中是一个十分常见的数据结构,它就相当于一个瓶子,可以往里面装入各种元素,最先装进这个瓶子里的元素,要把后装进这个瓶子里的全部元素拿出来完之后才能够把他给拿出来.假设这个瓶子在桌上平放,左 ...
随机推荐
- Intel FPGA Clock Region概念以及用法
目录 Intel FPGA 的Clock Region概念 Intel 不同系列FPGA 的Clock Region 1. Clock Region Assignments in Intel Stra ...
- python 串口 透传
python正常情况通过串口 serial 传输数据的时候,都是以字符串的形式发送的 str = ‘abcd’ ser.write(str.encode())#直接发送str报错,需要发送byte类 ...
- 快速上手Alibaba Arthas
点击返回上层目录 原创声明:作者:Arnold.zhao 博客园地址:https://www.cnblogs.com/zh94 Arthas 本文主要聚焦于快速上手并使用Arthas,所以对于基本的概 ...
- SVN强制添加备注
1.进入仓库project1/hooks目录,找到pre-commit.tmpl文件 cp pre-commit.tmpl pre-commit 2.编辑pre-commit文件, 将: $SVNLO ...
- wordpress获取当前分类的子分类
1.现在function.php里面添加下面的代码 function get_category_root_id($cat) { $this_category = get_category($cat); ...
- python的生成器和迭代器
三.推倒式从时间上比较:集合 字典 元祖 列表 (从小到大)占用内存比较:字典 集合 列表 元祖 (从大到小) 字典是可进行hash操作,操作的是字典的key ,而对list进行hash操作的时候操作 ...
- Tortoise svn 基础知识
1 不跟踪文件.文件夹 1.1 文件.文件夹已经被svn跟踪 将本地文件.文件夹删除(windows删除文件的删除,快捷键是shift+delete),然后执行svn update 将服务器同步到 ...
- linux高级管理第十四章--kvm虚拟化
案例 安装kvm所需软件 验证 注:虚拟机要开启虚拟引擎 开启服务 环境准备 安装相关软件包 启动 创建网桥 重启,reboot 安装虚拟机 完成.
- eatwhatApp开发实战(四)
之前我们做了添加店铺了功能,接下来我们做删除功能,并介绍对话框的使用方法. 在init()中注册listview的item点击监听 //注册监听 shop_lv.setOnItemClickListe ...
- spring boot 整合 poi 导出excel
一. 第一种方式 1.首先从中央仓库中导入架包Poi3.14以及Poi-ooxml3.14. <dependency> <groupId>org.apache.poi</ ...