TensorFlow从0到1之浅谈感知机与神经网络(18)
最近十年以来,神经网络一直处于机器学习研究和应用的前沿。深度神经网络(DNN)、迁移学习以及计算高效的图形处理器(GPU)的普及使得图像识别、语音识别甚至文本生成领域取得了重大进展。
神经网络受人类大脑的启发,也被称为连接模型。像人脑一样,神经网络是大量被称为权重的突触相互连接的人造神经元的集合。
就像我们通过年长者提供的例子来学习一样,人造神经网络通过向它们提供的例子来学习,这些例子被称为训练数据集。有了足够数量的训练数据集,人造神经网络可以提取信息,并用于它们没有见过的数据。
神经网络并不是最近才出现的。第一个神经网络模型 McCulloch Pitts(MCP)(http://vordenker.de/ggphilosophy/mcculloch_a-logical-calculus.pdf)早在 1943 年就被提出来了,该模型可以执行类似与、或、非的逻辑操作。
MCP 模型的权重和偏置是固定的,因此不具备学习的可能。这个问题在若干年后的 1958 年由 Frank Rosenblatt 解决(https://blogs.umass.edu/brain-wars/files/2016/03/rosenblatt-1957.pdf)。他提出了第一个具有学习能力的神经网络,称之为感知机(perceptron)。
从那时起,人们就知道添加多层神经元并建立一个深的、稠密的网络将有助于神经网络解决复杂的任务。就像母亲为孩子的成就感到自豪一样,科学家和工程师对使用神经网络(https://www.youtube.com/watch?v=jPHUlQiwD9Y)所能实现的功能做出了高度的评价。
这些评价并不是虚假的,但是由于硬件计算的限制和网络结构的复杂,当时根本无法实现。这导致了在 20 世纪 70 年代和 80 年代出现了被称为 AI 寒冬的时期。在这段时期,由于人工智能项目得不到资助,导致这一领域的进展放缓。
随着 DNN 和 GPU 的出现,情况发生了变化。今天,可以利用一些技术通过微调参数来获得表现更好的网络,比如 dropout 和迁移学习等技术,这缩短了训练时间。最后,硬件公司提出了使用专门的硬件芯片快速地执行基于神经网络的计算。
人造神经元是所有神经网络的核心。它由两个主要部分构成:一个加法器,将所有输入加权求和到神经元上;一个处理单元,根据预定义函数产生一个输出,这个函数被称为激活函数。每个神经元都有自己的一组权重和阈值(偏置),它通过不同的学习算法学习这些权重和阈值:
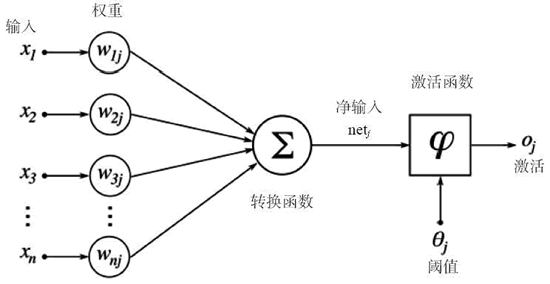
当只有一层这样的神经元存在时,它被称为感知机。输入层被称为第零层,因为它只是缓冲输入。存在的唯一一层神经元形成输出层。输出层的每个神经元都有自己的权重和阈值。
当存在许多这样的层时,网络被称为多层感知机(MLP)。MLP有一个或多个隐藏层。这些隐藏层具有不同数量的隐藏神经元。每个隐藏层的神经元具有相同的激活函数:
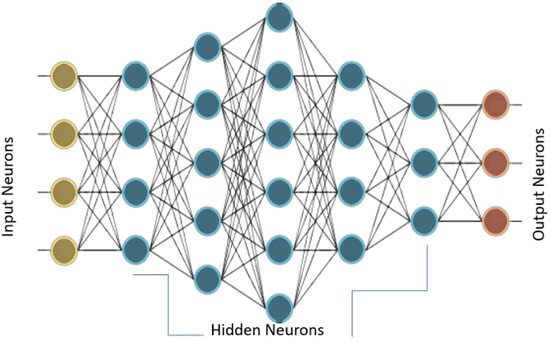
上图的 MLP 具有一个有 4 个输入的输入层,5 个分别有 4、5、6、4 和 3 个神经元的隐藏层,以及一个有 3 个神经元的输出层。在该 MLP 中,下层的所有神经元都连接到其相邻的上层的所有神经元。因此,MLP 也被称为全连接层。MLP 中的信息流通常是从输入到输出,目前没有反馈或跳转,因此这些网络也被称为前馈网络。
感知机使用梯度下降算法进行训练。前面章节已经介绍了梯度下降,在这里再深入一点。感知机通过监督学习算法进行学习,也就是给网络提供训练数据集的理想输出。在输出端,定义了一个误差函数或目标函数 J(W),这样当网络完全学习了所有的训练数据后,目标函数将是最小的。
输出层和隐藏层的权重被更新,使得目标函数的梯度减小:
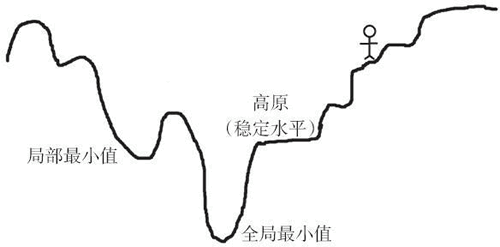
为了更好地理解它,想象一个充满山丘、高原和凹坑的地形。目标是走到地面(目标函数的全局最小值)。如果你站在最上面,必须往下走,那么很明显你将会选择下山,即向负坡度(或负梯度)方向移动。相同的道理,感知机的权重与目标函数梯度的负值成比例地变化。
梯度的值越大,权值的变化越大,反之亦然。现在,这一切都很好,但是当到达高原时,可能会遇到问题,因为梯度是零,所以权重没有变化。当进入一个小坑(局部最小值)时,也会遇到问题,因为尝试移动到任何一边,梯度都会增加,迫使网络停留在坑中。
正如前面所述,针对增加网络的收敛性提出了梯度下降的各种变种使得网络避免陷入局部最小值或高原的问题,比如添加动量、可变学习率。
TensorFlow 会在不同的优化器的帮助下自动计算这些梯度。然而,需要注意的重要一点是,由于 TensorFlow 将计算梯度,这也将涉及激活函数的导数,所以你选择的激活函数必须是可微分的,并且在整个训练场景中具有非零梯度。
感知机中的梯度下降与梯度下降的一个主要不同是,输出层的目标函数已经被定义好了,但它也用于隐藏层神经元的权值更新。这是使用反向传播(BPN)算法完成的,输出中的误差向后传播到隐藏层并用于确定权重变化。
TensorFlow从0到1之浅谈感知机与神经网络(18)的更多相关文章
- TensorFlow 2.0 深度学习实战 —— 浅谈卷积神经网络 CNN
前言 上一章为大家介绍过深度学习的基础和多层感知机 MLP 的应用,本章开始将深入讲解卷积神经网络的实用场景.卷积神经网络 CNN(Convolutional Neural Networks,Conv ...
- TensorFlow从0到1之浅谈深度学习(10)
DNN(深度神经网络算法)现在是AI社区的流行词.最近,DNN 在许多数据科学竞赛/Kaggle 竞赛中获得了多次冠军. 自从 1962 年 Rosenblat 提出感知机(Perceptron)以来 ...
- [C#]6.0新特性浅谈
原文:[C#]6.0新特性浅谈 C#6.0出来也有很长一段时间了,虽然新的特性和语法趋于稳定,但是对于大多数程序猿来说,想在工作中用上C#6.0估计还得等上不短的一段时间.所以现在再来聊一聊新版本带来 ...
- 浅谈Android Studio3.0更新之路(遇坑必入)
>可以参考官网设置-> 1 2 >> Fantasy_Lin_网友评论原文地址是:简书24K纯帅豆写的我也更新一下出处[删除]Fa 转自脚本之家 浅谈Android Studi ...
- 浅谈linux中shell变量$#,$@,$0,$1,$2,$?的含义解释
浅谈linux中shell变量$#,$@,$0,$1,$2,$?的含义解释 下面小编就为大家带来一篇浅谈linux中shell变量$#,$@,$0,$1,$2的含义解释.小编觉得挺不错的,现在就分享给 ...
- 浅谈[0,1]区间内的n个随机实数变量中增加偏序关系类题目的解法
浅谈[0,1]区间内的n个随机实数变量中增加偏序关系类题目的解法 众所周知,把[0,1]区间内的n个随机.相互独立的实数变量\(x_i\)之间的大小关系写成一个排列\(\{p_i\}\),使得\(\f ...
- Spring5.0源码学习系列之浅谈BeanFactory创建
Spring5.0源码学习系列之浅谈BeanFactory创建过程 系列文章目录 提示:Spring源码学习专栏链接 @ 目录 系列文章目录 博客前言介绍 一.获取BeanFactory主流程 二.r ...
- Spring5.0源码学习系列之浅谈循环依赖问题
前言介绍 附录:Spring源码学习专栏 在上一章的学习中,我们对Bean的创建有了一个粗略的了解,接着本文浅谈Spring循环依赖问题,这是一个面试比较常见的问题 1.什么是循环依赖? 所谓的循环依 ...
- 浅谈new operator、operator new和placement new 分类: C/C++ 2015-05-05 00:19 41人阅读 评论(0) 收藏
浅谈new operator.operator new和placement new C++中使用new来产生一个存在于heap(堆)上对象时,实际上是调用了operator new函数和placeme ...
随机推荐
- 工作中遇到的SQL
1.根据a表中的字段col,修改b表中的col UPDATE a INNER JOIN b ON a.id = b.id SET b.col = xx WHERE a.col = xx 2.模糊查询 ...
- afert和b的伪类画三角形
/* 提示信息 */ .content-tishi{ width: 6.93rem; margin: 0 auto; background: #e9eaea; display: flex; flex- ...
- Spring 使用注解对事务控制详解与实例
1.什么是事务 一荣俱荣,一损俱损,很多复杂的操作我们可以把它看成是一个整体,要么同时成功,要么同时失败. 事务的四个特征ACID: 原子性(Atomic):表示组成一个事务的多个数据库的操作的不可分 ...
- spring设计模式之applicationContext.getBean("beanName")思想
1.背景 在实际开发中我们会经常遇到不同的业务类型对应不同的业务处理,而这个业务类型又是经常变动的; 比如说,我们在做支付业务的时候,可能刚开始需要实现支付宝支付和微信支付,那么代码逻辑可能如下 /* ...
- [FlashDevelop] 001.FlashDevelop + LayaFlash环境搭建
产品简介: 唯一使用Flash直接开发或转换大型HTML5游戏的全套解决方案. 开发工具 FlashDevelop + JDK + flashplayer_18_sa_debug + LayaFlas ...
- HTML转义字符&url编码表
ISO Latin-1字符集: — 制表符Horizontal tab — 换行Line feed — 回车Carriage Return — Space ! ! — 惊叹号Exclamati ...
- 【Java8新特性】关于Java8中的日期时间API,你需要掌握这些!!
写在前面 Java8之前的日期和时间API,存在一些问题,比如:线程安全的问题,跨年的问题等等.这些问题都在Hava8中的日期和时间API中得到了解决,而且Java8中的日期和时间API更加强大.立志 ...
- Rocket - debug - Example: DMI
https://mp.weixin.qq.com/s/7suuJ7m2BKCpsHk1K2FzJQ 介绍riscv-debug的使用实例:如何使用DMI. 1. dm Debug Module实现了调 ...
- Java实现 LeetCode 476 数字的补数
476. 数字的补数 给定一个正整数,输出它的补数.补数是对该数的二进制表示取反. 示例 1: 输入: 5 输出: 2 解释: 5 的二进制表示为 101(没有前导零位),其补数为 010.所以你需要 ...
- Java实现 LeetCode 233 数字 1 的个数
233. 数字 1 的个数 给定一个整数 n,计算所有小于等于 n 的非负整数中数字 1 出现的个数. 示例: 输入: 13 输出: 6 解释: 数字 1 出现在以下数字中: 1, 10, 11, 1 ...