【数据库内核】RocksDB:事务锁设计与实现
本文主要介绍 RocksDB 锁结构设计、加锁解锁过程,并与 InnoDB 锁实现做一个简单对比。
本文由作者授权发布,未经许可,请勿转载。
作者:王刚,网易杭研数据库内核开发工程师
MyRocks 引擎目前是支持行锁的,包括共享锁和排它锁,主要是在 RocksDB 层面实现的,与 InnoDB 引擎的锁系统相比,简单很多。
本文主要介绍 RocksDB 锁结构设计、加锁解锁过程,并与 InnoDB 锁实现做一个简单对比。
事务锁的实现类是:TransactionLockMgr ,它的主要数据成员包括:
private:
PessimisticTransactionDB* txn_db_impl_;
// 默认16个lock map 分片
const size_t default_num_stripes_;
// 每个column family 最大行锁数
const int64_t max_num_locks_;
// lock map 互斥锁
InstrumentedMutex lock_map_mutex_; // Map of ColumnFamilyId to locked key info
using LockMaps = std::unordered_map<uint32_t, std::shared_ptr<LockMap>>;
LockMaps lock_maps_;
std::unique_ptr<ThreadLocalPtr> lock_maps_cache_;
// Must be held when modifying wait_txn_map_ and rev_wait_txn_map_.
std::mutex wait_txn_map_mutex_;
// Maps from waitee -> number of waiters.
HashMap<TransactionID, int> rev_wait_txn_map_;
// Maps from waiter -> waitee.
HashMap<TransactionID, TrackedTrxInfo> wait_txn_map_;
DeadlockInfoBuffer dlock_buffer_;
// Used to allocate mutexes/condvars to use when locking keys
std::shared_ptr<TransactionDBMutexFactory> mutex_factory_;
加锁的入口函数是:TransactionLockMgr::TryLock
Status TransactionLockMgr::TryLock(PessimisticTransaction* txn, //加锁的事务
uint32_t column_family_id, //所属的CF
const std::string& key, //加锁的健 Env* env,
bool exclusive //是否排它锁) {
// Lookup lock map for this column family id
std::shared_ptr<LockMap> lock_map_ptr = GetLockMap(column_family_id); //1. 根据 cf id 查找其 LockMap
LockMap* lock_map = lock_map_ptr.get();
if (lock_map == nullptr) {
char msg[];
snprintf(msg, sizeof(msg), "Column family id not found: %" PRIu32,
column_family_id); return Status::InvalidArgument(msg);
} // Need to lock the mutex for the stripe that this key hashes to
size_t stripe_num = lock_map->GetStripe(key);// 2. 根据key 的哈希获取 stripe_num,默认16个stripe
assert(lock_map->lock_map_stripes_.size() > stripe_num);
LockMapStripe* stripe = lock_map->lock_map_stripes_.at(stripe_num); LockInfo lock_info(txn->GetID(), txn->GetExpirationTime(), exclusive);
int64_t timeout = txn->GetLockTimeout(); return AcquireWithTimeout(txn, lock_map, stripe, column_family_id, key, env,
timeout, lock_info); // 实际加锁函数
}
GetLockMap(column_family_id) 函数根据 cf id 查找其 LockMap , 其逻辑包括两步:
- 在 thread 本地缓存 lock_maps_cache 中查找;
- 第1步没有查找到,则去全局的 lock_map_ 中查找。
std::shared_ptr<LockMap> TransactionLockMgr::GetLockMap(
uint32_t column_family_id) {
// First check thread-local cache
if (lock_maps_cache_->Get() == nullptr) {
lock_maps_cache_->Reset(new LockMaps());
}
auto lock_maps_cache = static_cast<LockMaps*>(lock_maps_cache_->Get());
auto lock_map_iter = lock_maps_cache->find(column_family_id);
if (lock_map_iter != lock_maps_cache->end()) {
// Found lock map for this column family.
return lock_map_iter->second;
}
// Not found in local cache, grab mutex and check shared LockMaps
InstrumentedMutexLock l(&lock_map_mutex_);
lock_map_iter = lock_maps_.find(column_family_id);
if (lock_map_iter == lock_maps_.end()) {
return std::shared_ptr<LockMap>(nullptr);
} else {
// Found lock map. Store in thread-local cache and return.
std::shared_ptr<LockMap>& lock_map = lock_map_iter->second;
lock_maps_cache->insert({column_family_id, lock_map});
return lock_map;
}
}
lock_maps_ 是全局锁结构:
// Map of ColumnFamilyId to locked key info
using LockMaps = std::unordered_map<uint32_t, std::shared_ptr<LockMap>>;
LockMaps lock_maps_;
LockMap 是每个 CF 的锁结构:
struct LockMap {
// Number of sepearate LockMapStripes to create, each with their own Mutex
const size_t num_stripes_;
// Count of keys that are currently locked in this column family.
// (Only maintained if TransactionLockMgr::max_num_locks_ is positive.)
std::atomic<int64_t> lock_cnt{};
std::vector<LockMapStripe*> lock_map_stripes_;
};
为了减少加锁时mutex 的争用,LockMap 内部又进行了分片,num_stripes_ = 16(默认值),
LockMapStripe 是每个分片的锁结构:
struct LockMapStripe {
// Mutex must be held before modifying keys map
std::shared_ptr<TransactionDBMutex> stripe_mutex;
// Condition Variable per stripe for waiting on a lock
std::shared_ptr<TransactionDBCondVar> stripe_cv;
// Locked keys mapped to the info about the transactions that locked them.
// TODO(agiardullo): Explore performance of other data structures.
std::unordered_map<std::string, LockInfo> keys;
};
LockMapStripe 内部还是一个 unordered_map, 还包括 stripe_mutex、stripe_cv 。这样设计避免了一把大锁的尴尬,减小锁的粒度常用的方法,LockInfo 包含事务id:
struct LockInfo {
bool exclusive;
autovector<TransactionID> txn_ids;
// Transaction locks are not valid after this time in us
uint64_t expiration_time;
};
LockMaps 、LockMap、LockMapStripe 、LockInfo就是RocksDB 事务锁用到的数据结构了,可以看到并不复杂,代码实现起来简单,代价当然也有,后文在介绍再介绍。
AcquireWithTimeout 函数内部先获取 stripe mutex ,获取到了在进入AcquireLocked 函数:
if (timeout < ) {
// If timeout is negative, we wait indefinitely to acquire the lock
result = stripe->stripe_mutex->Lock();
} else {
result = stripe->stripe_mutex->TryLockFor(timeout);
}
获取了 stripe_mutex之后,准备获取锁:
// Acquire lock if we are able to
uint64_t expire_time_hint = ;
autovector<TransactionID> wait_ids;
result = AcquireLocked(lock_map, stripe, key, env, lock_info,
&expire_time_hint, &wait_ids);
AcquireLocked 函数实现获取锁逻辑,它的实现逻辑是:
- 在 stripe 的 map 中查找该key 是否已经被锁住。
- 如果key没有被锁住,判断是否超过了max_num_locks_,没超过则在 stripe的map 中插入{key, txn_lock_info},超过了max_num_locks_,加锁失败,返回状态信息。
- 如果key已经被锁住了,要判断加在key上的锁是排它锁还是共享锁,如果是共享锁,那事务的加锁请求可以满足;
- 如果是排它锁,如果是同一事务,加锁请求可以满足,如果不是同一事务,如果锁没有超时,则加锁请求失败,否则抢占过来。
- 以上是加锁过程,解锁过程类似,也是需要根据cf_id 和 key 计算出落到哪个stripe上,然后就是从map中把数据清理掉,同时还要唤醒该stripe上的等待线程,这个唤醒的粒度有点大。
void TransactionLockMgr::UnLock(PessimisticTransaction* txn,
uint32_t column_family_id,
const std::string& key, Env* env) {
std::shared_ptr<LockMap> lock_map_ptr = GetLockMap(column_family_id);//通过cf_id 获取Lock_Map
LockMap* lock_map = lock_map_ptr.get();
if (lock_map == nullptr) {
// Column Family must have been dropped.
return;
}
// Lock the mutex for the stripe that this key hashes to
size_t stripe_num = lock_map->GetStripe(key);//根据key 计算落到哪个stripe上
assert(lock_map->lock_map_stripes_.size() > stripe_num);
LockMapStripe* stripe = lock_map->lock_map_stripes_.at(stripe_num);
stripe->stripe_mutex->Lock();
UnLockKey(txn, key, stripe, lock_map, env); //从锁的map中清理掉该key
stripe->stripe_mutex->UnLock();
// Signal waiting threads to retry locking
stripe->stripe_cv->NotifyAll();
}
ocksdb lock整体结构如下:
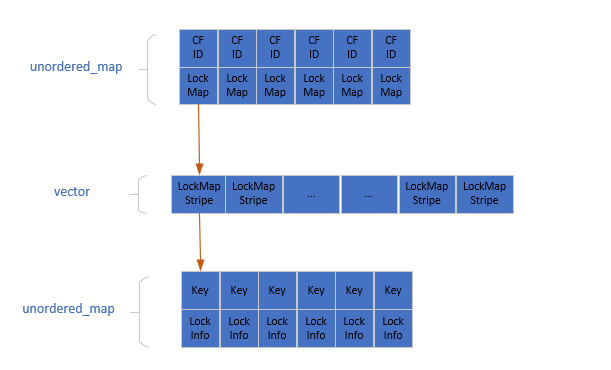
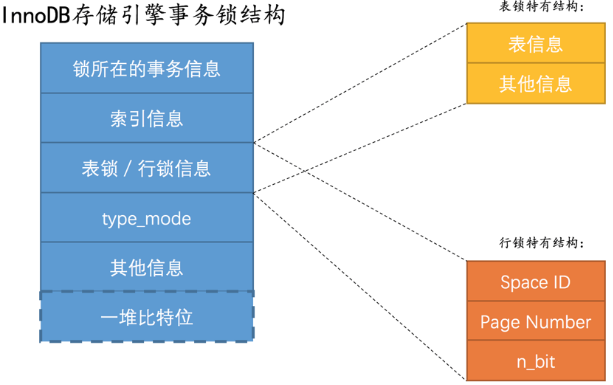
如果一个事务需要锁住大量记录,rocksdb 锁的实现方式可能要比innodb 消耗更多的内存,innodb 的锁结构如下图所示:
由于锁信息是常驻内存,我们简单分析下RocksDB锁占用的内存。每个锁实际上是unordered_map中的一个元素,则锁占用的内存为key_length+8+8+1,假设key为bigint,占8个字节,则100w行记录,需要消耗大约22M内存。但是由于内存与key_length正相关,导致RocksDB的内存消耗不可控。我们可以简单算算RocksDB作为MySQL存储引擎时,key_length的范围。对于单列索引,最大值为2048个字节,具体可以参考max_supported_key_part_length实现;对于复合索引,索引最大长度为3072个字节,具体可以参考max_supported_key_length实现。
假设最坏的情况,key_length=3072,则100w行记录,需要消耗3G内存,如果是锁1亿行记录,则需要消耗300G内存,这种情况下内存会有撑爆的风险。因此RocksDB提供参数配置rocksdb_max_row_locks,确保内存可控,默认rocksdb_max_row_locks设置为1048576,对于大部分key为bigint场景,极端情况下,也需要消耗22G内存。而在这方面,InnoDB则比较友好,hash表的key是(space_id, page_no),所以无论key有多大,key部分的内存消耗都是恒定的。InnoDB在一个事务需要锁大量记录场景下是有优化的,多个记录可以公用一把锁,这样也间接可以减少内存。
总结
RocksDB 事务锁的实现整体来说不复杂,只支持行锁,还不支持gap lock ,锁占的资源也比较大,可通过rocksdb_max_row_locks 限制事务施加行锁的数量。
利益相关:
网易轻舟微服务,提供分布式事务框架GTXS,支持跨服务事务、跨数据源事务、混合事务、事务状态监控、异常事务处理等能力,应用案例 工商银行。
【数据库内核】RocksDB:事务锁设计与实现的更多相关文章
- DTCC 2019 | 深度解码阿里数据库实现 数据库内核——基于HLC的分布式事务实现深度剖析
摘要:分布式事务是分布式数据库最难攻克的技术之一,分布式事务为分布式数据库提供一致性数据访问的支持,保证全局读写原子性和隔离性,提供一体化分布式数据库的用户体验.本文主要分享分布式数据库中的时钟解决方 ...
- 数据库内核——基于HLC的分布式事务实现深度剖析
DTCC 2019 | 深度解码阿里数据库实现 数据库内核--基于HLC的分布式事务实现深度剖析-阿里云开发者社区 https://developer.aliyun.com/article/70355 ...
- 【转】MSSQLServer数据库事务锁机制分析
锁是网络数据库中的一个非常重要的概念,它主要用于多用户环境下保证数据库完整性和一致性.各种大型数据库所采用的锁的基本理论是一致的,但在具体实现上各有差别.目前,大多数数据库管理系统都或多或少具有自我调 ...
- c#数据库事务锁类型
一.脏读.不可重复读.幻象读的区别 1.脏读:包含未提交数据的读取.例如,事务 a 更改了某行(数据库已发生更改,但尚未提交,有可能发生回滚),事务 b 在事务 a 提交更改之前读取已更改的行.如 ...
- MySQL数据库引擎、事务隔离级别、锁
MySQL数据库引擎.事务隔离级别.锁 数据库引擎InnoDB和MyISAM有什么区别 大体区别为: MyISAM类型不支持事务处理等高级处理,而InnoDB类型支持.MyISAM类型的表强调的是性能 ...
- oracle 事务 锁机制
原文地址:http://www.cnblogs.com/quanweiru/archive/2013/05/24/3097367.html 本课内容属于Oracle高级课程范畴,内容略微偏向理论性,但 ...
- innodb事务锁
计算机程序锁 控制对共享资源进行并发访问 保护数据的完整性和一致性 lock 主要是事务,数据库逻辑内容,事务过程 latch/mutex 内存底层锁: 更新丢失 原因: B的更改还没有 ...
- MySQL事务锁等待超时 Lock wait timeout exceeded; try restarting transaction
工作中处理定时任务分发消息时出现的问题,在查找并解决问题的时候,将相关的问题博客收集整理,在此记录下,以便之后再遇到相同的问题,方便查阅. 问题场景 问题出现的场景: 在消息队列处理消息时,同一事务内 ...
- 查看事务锁:innodb_trx+innodb_locks+innodb_lock_waits
当出现:ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction,要解决是一件麻烦的事情:特别是当一个SQL ...
随机推荐
- Java实现 LeetCode 791 自定义字符串排序(桶排序)
791. 自定义字符串排序 字符串S和 T 只包含小写字符.在S中,所有字符只会出现一次. S 已经根据某种规则进行了排序.我们要根据S中的字符顺序对T进行排序.更具体地说,如果S中x在y之前出现,那 ...
- Java实现 LeetCode 556 下一个更大元素 III(数组的翻转)
556. 下一个更大元素 III 给定一个32位正整数 n,你需要找到最小的32位整数,其与 n 中存在的位数完全相同,并且其值大于n.如果不存在这样的32位整数,则返回-1. 示例 1: 输入: 1 ...
- Java实现 LeetCode 47 全排列 II(二)
47. 全排列 II 给定一个可包含重复数字的序列,返回所有不重复的全排列. 示例: 输入: [1,1,2] 输出: [ [1,1,2], [1,2,1], [2,1,1] ] class Solut ...
- Java实现 LeetCode 13 罗马数字转整数
13. 罗马数字转整数 罗马数字包含以下七种字符: I, V, X, L,C,D 和 M. 字符 数值 I 1 V 5 X 10 L 50 C 100 D 500 M 1000 例如, 罗马数字 2 ...
- Java实现第九届蓝桥杯全球变暖
全球变暖 题目描述 你有一张某海域NxN像素的照片,"."表示海洋."#"表示陆地,如下所示: ....... .##.... .##.... ....##. ...
- 真香,撸一个SpringBoot在线代码修改器
前言 项目上线之后,如果是后端报错,只能重新编译打包部署然后重启:如果仅仅是前端页面.样式.脚本修改,只需要替换到就可以了. 小公司的话可能比较自由,可以随意替换,但是有些公司权限设置的比较严格,需要 ...
- 案例:DG主库未设置force logging导致备库坏块
DG搭建时,官方文档手册有明确提到要设置数据库为force_logging,防止有nologging操作日志记录不全导致备库应用时出现问题. 虽然是老生常谈的安装规范,但现实中总会遇到不遵守规范的场景 ...
- MYSQL 实现ROWNO功能
select tt.rowno from( select (@rownum:=@rownum+1) as rowno, t.id from news t ,(select (@rownum : ...
- mysql 双机互备份
//1.创建用户CREATE USER 'dump'@'%' IDENTIFIED BY 'dump'; //2.开放权限GRANT ALL ON *.* TO 'dump'@'%'; //3.刷新权 ...
- centos6 升级python2.6 到 python2.7
由于开发库依赖于python27,而自己安装的centos6.8自带的python是2.6.6. 因为centos的yum依赖于python26因此不打算覆盖26. 步骤如下: 1.官网下载源码压缩包 ...