一致性 Hash 算法分析

当我们在做数据库分库分表或者是分布式缓存时,不可避免的都会遇到一个问题:
如何将数据均匀的分散到各个节点中,并且尽量的在加减节点时能使受影响的数据最少。
Hash 取模
随机放置就不说了,会带来很多问题。通常最容易想到的方案就是 hash 取模了。
可以将传入的 Key 按照 index = hash(key) % N 这样来计算出需要存放的节点。其中 hash 函数是一个将字符串转换为正整数的哈希映射方法,N 就是节点的数量。
这样可以满足数据的均匀分配,但是这个算法的容错性和扩展性都较差。
比如增加或删除了一个节点时,所有的 Key 都需要重新计算,显然这样成本较高,为此需要一个算法满足分布均匀同时也要有良好的容错性和拓展性。
一致 Hash 算法
一致 Hash 算法是将所有的哈希值构成了一个环,其范围在 0 ~ 2^32-1。如下图:
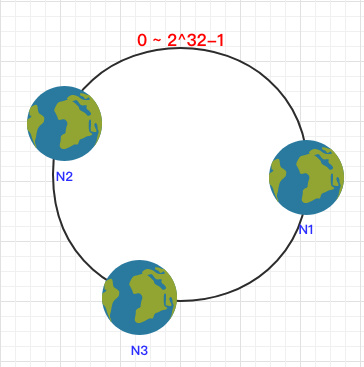
之后将各个节点散列到这个环上,可以用节点的 IP、hostname 这样的唯一性字段作为 Key 进行 hash(key),散列之后如下:
之后需要将数据定位到对应的节点上,使用同样的 hash 函数 将 Key 也映射到这个环上。
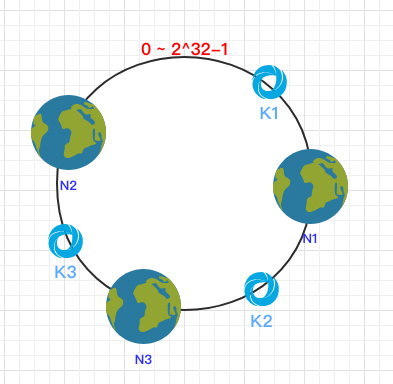
这样按照顺时针方向就可以把 k1 定位到 N1节点,k2 定位到 N3节点,k3 定位到 N2节点。
容错性
这时假设 N1 宕机了:
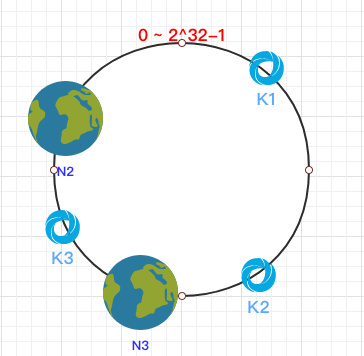
依然根据顺时针方向,k2 和 k3 保持不变,只有 k1 被重新映射到了 N3。这样就很好的保证了容错性,当一个节点宕机时只会影响到少少部分的数据。
拓展性
当新增一个节点时:
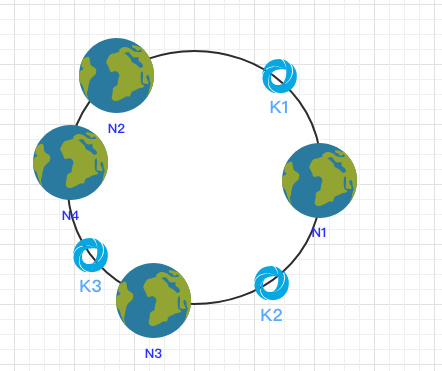
在 N2 和 N3 之间新增了一个节点 N4 ,这时会发现受印象的数据只有 k3,其余数据也是保持不变,所以这样也很好的保证了拓展性。
虚拟节点
到目前为止该算法依然也有点问题:
当节点较少时会出现数据分布不均匀的情况:
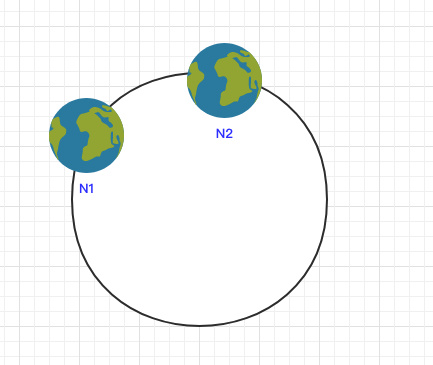
这样会导致大部分数据都在 N1 节点,只有少量的数据在 N2 节点。
为了解决这个问题,一致哈希算法引入了虚拟节点。将每一个节点都进行多次 hash,生成多个节点放置在环上称为虚拟节点:
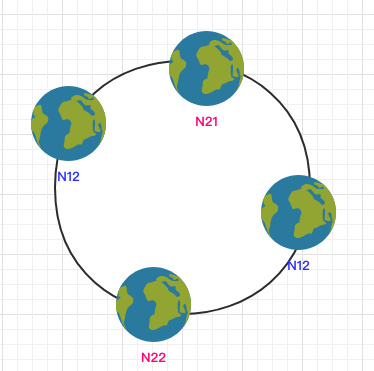
计算时可以在 IP 后加上编号来生成哈希值。
这样只需要在原有的基础上多一步由虚拟节点映射到实际节点的步骤即可让少量节点也能满足均匀性。
号外
最近在总结一些 Java 相关的知识点,感兴趣的朋友可以一起维护。
一致性 Hash 算法分析的更多相关文章
- 一致性 Hash 算法的实际应用
前言 记得一年前分享过一篇<一致性 Hash 算法分析>,当时只是分析了这个算法的实现原理.解决了什么问题等. 但没有实际实现一个这样的算法,毕竟要加深印象还得自己撸一遍,于是本次就当前的 ...
- 一致性hash应用到redis
理解分布式存储的本质 有一个经典的实践经验: 数(值)据大了, 什么都是问题! 如果要求128B或更大数值计算, 哪么四则运算会是个大问题! 如果要求128T或更大日志存储, 哪么文件存储会是个大问题 ...
- 对一致性Hash算法,Java代码实现的深入研究
一致性Hash算法 关于一致性Hash算法,在我之前的博文中已经有多次提到了,MemCache超详细解读一文中"一致性Hash算法"部分,对于为什么要使用一致性Hash算法.一致性 ...
- 转载自lanceyan: 一致性hash和solr千万级数据分布式搜索引擎中的应用
一致性hash和solr千万级数据分布式搜索引擎中的应用 互联网创业中大部分人都是草根创业,这个时候没有强劲的服务器,也没有钱去买很昂贵的海量数据库.在这样严峻的条件下,一批又一批的创业者从创业中获得 ...
- 一致性hash算法详解
转载请说明出处:http://blog.csdn.net/cywosp/article/details/23397179 一致性哈希算法在1997年由麻省理工学院提出的一种分布式哈希(DHT) ...
- 探索c#之一致性Hash详解
阅读目录: 使用场景 算法原理 虚拟节点 代码示例 使用场景 以Redis为例,当系统需要缓存的内容超过单机内存大小时,例如要缓存100G数据,单机内存仅有16G时.这时候就需要考虑进行缓存数据分片, ...
- 一致性hash算法简介
一致性哈希算法在1997年由麻省理工学院提出的一种分布式哈希(DHT)实现算法,设计目标是为了解决因特网中的热点(Hot spot)问题,初衷和CARP十分类似.一致性哈希修正了CARP使用的简单哈希 ...
- 分布式缓存技术memcached学习(四)—— 一致性hash算法原理
分布式一致性hash算法简介 当你看到“分布式一致性hash算法”这个词时,第一时间可能会问,什么是分布式,什么是一致性,hash又是什么.在分析分布式一致性hash算法原理之前,我们先来了解一下这几 ...
- 关于Memcached一致性hash的探究
参考文章 http://blog.chinaunix.net/uid-20498361-id-4303232.html http://blog.csdn.net/kongqz/article/deta ...
随机推荐
- FullPage.js中文帮助文档API
fullPage.js的方法: 1. moveSectionUp() 功能:向上滚动一页. 2. moveSectionDown() 功能:向下滚动一页. 3. moveTo(section, sli ...
- 吴裕雄--天生自然 JAVA开发学习:异常处理
try { // 程序代码 }catch(ExceptionName e1) { //Catch 块 } import java.io.*; public class ExcepTest{ publi ...
- python基础——散列类型
集合 集合具有不重复性,无序性的可变对象. 集合定义 直接定义 如:a = {'a','b',2} 别的类型转换,利用set a = set(b) 其中b可以是一个列表或字符串等 增 add ...
- python学习笔记(26)-request模块
python学习笔记 #requests import requests #from class_005.http_resuest import HttpRequest login_url = &qu ...
- Git内部原理(1)
Git本质上是一套内容寻址文件系统,在此之上提供了VCS的用户界面. Git底层命令(plumbing) vs 高层命令(porcelain) Git的高层命令包括checkout.branch.re ...
- Mysql计算时间最近多久
-- DATE_SUB(CURDATE(), INTERVAL 3 MONTH)计算结果为当前时间的前推三个月,time字段可为时间型字符串 select * form t_user where ti ...
- Python语言学习前提:python安装和pycharm安装
一.Windows系统python安装 1.python官网:https://www.python.org/downloads/ 2.官网首页:点击Downloads > Windows > ...
- django框架进阶-CSRF认证
############################################### """ django中csrf的实现机制 #第一步:django第一次响应 ...
- TCP与UDP 笔记
本文整理自:<图解TCP/IP 第5版>作者:[日] 竹下隆史,[日] 村山公保,[日] 荒井透,[日] 苅田幸雄 著译者:乌尼日其其格出版时间:2013-07 TCP提供可靠的通信传输, ...
- 吴裕雄--天生自然 HADOOP大数据分布式处理:使用WinSCP连接本机与虚拟机