MySQL对JSON类型UTF-8编码导致中文乱码探讨
前言
继上文发表之后,结合评论意见并亲自验证最终发现是编码的问题,但是对于字符编码还是有点不解,于是乎,有了本文,我们来学习字符编码,在学习的过程中,我发现对于MySQL中JSON类型的编码导致数据中文出现乱码还有可深挖之处,接下来我们来分析一下,若有错误之处,还请批评指出。
字符编码
评论中指出任何不在基本多文本平面的Unicode字符,都无法使用MySQL的utf8字符集存储,包括Emoji 表情(Emoji 是一种特殊的Unicode 编码,常见于IOS和Android 手机上)和很多不常用的汉字,以及任何新增的 Unicode 字符等等(utf8的缺点),然而啥是多文本平面,详情维基百科《https://en.wikipedia.org/wiki/Plane_(Unicode)》。首先我们了解下什么是Unicode,Unicode是通用字符集,它是一种标准,该标准在一处定义了编写在计算机上使用的大多数活动语言所需的所有字符,它的目标是成为并且在很大程度上已经是已编码的所有其他字符集的超集。在计算机或网络中的文本我们通过字符组成,字符代表字母、标点符号或其他符号。不同的组织收集了不同的字符集并为其创建了编码-一个字符集可能仅覆盖基于拉丁语的西欧语言(不包括保加利亚或希腊等欧盟国家),另一个可能覆盖特定的远东语言(例如(例如日语),其他语言可能是以特殊方式设计的,代表世界上某处其他语言的众多语言之一。但是我们并不能保证应用程序将支持所有编码,也不能保证给定的编码将满足我们代表给定语言的所有需求,另外,通常不可能在同一网页或数据库中组合不同的编码,因此使用“传统”编码方法来支持多语言页面通常非常困难,所以Unicode协会提供了一个大的,单字节字符集,旨在包括所有需要的世界上任何书写系统,包括古老的脚本(如楔形文字,哥特式和埃及的象形文字)的字符,所以统一字符编码,将其作为Web和操作系统体系结构的基础,并且得到所有主要Web浏览器和应用程序的支持。当前的Unicode字符分为17组编排,每组被称之为一个平面(Plane),所以将字符划分为0-16号的平面,而每平面拥有65536(即216)个代码点即范围区间在0x000到0xFFFF之间,而0号平面就是基本多语言平面(BMP:Basic Mutiingual Plane)。在基本多文本平面上针对每一种文字或者其补充或者其扩展都给出了一个编码范围,比如拉丁文【0000-007F】,拉丁文-补充【0080-00FF】等等。说了这么多,我们只需要记住一点即可:在Unicode字符集中前65536个代码点构成了基本多语言平面简称BMP,BMP中包含了大多常用的字符,另外Unicode字符集还包含了一百万个其他代码点的位置空间,我们称之为补充字符。我们需要区分字符集、编码字符集和编码的概念,字符集或字符串包含可能用于特定目的的字符集,它是支持计算机上的西欧语言所需的字符集,与计算机完全无关,而编码字符集是一组用于该唯一的号码被分配给每个字符的字符,有时候我们将编码字符集也可称作为代码页,编码字符集的单位称为代码点,代码点值表示字符在编码字符集中的位置。例如,Unicode编码字符集中字母á的代码点为十进制225,十六进制表示法为0xE1。而字符编码反映编码字符集被映射到用于在计算机操纵字节的方式。一个字符集可以有多种编码,许多字符编码标准,例如ISO 8859系列中定义的标准,都为给定字符使用单个字节,并且编码是对编码字符集中字符标量位置的直接映射。例如,ISO 8859-1编码字符集中的字母A在第65个字符位置(从零开始),并且使用值为65的字节进行编码并以此在计算机中表示,对于ISO 8859-1而言,这将永远不会再改变,但是,对于Unicode,事情并没有如此简单,尽管Unicode编码字符集中字母á的代码点始终为225(十进制),但在UTF-8中,它在计算机中由两个字节表示,换句话说,在此字符的编码字符集值和编码值之间不是简单的一对一映射,另外,在Unicode中,针对同一字符可以有多种编码的方式。例如,字母á可以用一种编码形式的两个字节表示,而用另一种编码形式的四个字节表示。可以与Unicode一起使用的编码形式称为UTF-8,UTF-16和UTF-32。
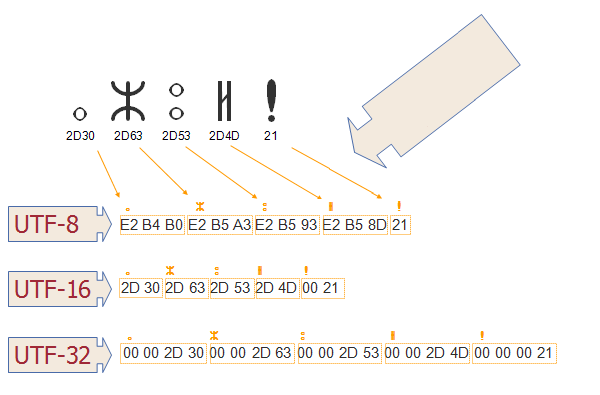
UTF-8使用1个字节表示ASCII集中的字符,使用2个字节表示其他几个字母块中的字符,使用3个字节表示BMP的其余部分,补充字符使用4个字节。UTF-16对BMP中的任何字符使用2个字节,对补充字符使用4个字节。UTF-32对所有字符使用4个字节。基本多语言平面对应代码点存储的是常用字符,上述针对不同字符在其对应代码点,然后计算出该字符的16进制的字符串,举个栗子,将【好】字进行UTF-8编码看看该字符的字节值和字节数,如下:
var bytes = Encoding.UTF8.GetBytes("好");
var hexString = BitConverter.ToString(bytes);

到此我们大概了解完了字符编码,接下来我们再次回到上一节的问题,上一节将我姓名作为JSON存储到数据库中去,但是最终获取数据时,将出现乱码,因为其表编码为utf8,最终将表编码修改为utf8mb4才好使,为啥utf8就不行呢?通过上述对utf8的定义最多可以有4个字节,支持补充字符,所以MySQL根本就没有实现标准的utf8编码,换句话说只是部分实现了utf8编码,MySQL中的utf8又名为utf8mb3,也就是一个字符最多可通过3个字节表示且包含BMP字符,而不包含补充字符。所以无论是我的姓还是名虽然是3个字节,但是并非常用BMP字符导致。但是针对列类型为JSON类型,事实是对于获取中文真的会乱码吗?上文我用到的MySQL版本为5.7+,如下:

接下来我们利用MySQL 8.0再来进行测试发现不会乱码,创建类和表配置编码如下:

public class t1
{
public int id { get; set; }
public string jdoc { get; set; }
}


static void Main(string[] args)
{ SetDialect(Dialect.MySQL); var con = new MySqlConnection(@"Server=localhost;Database=user;Uid=root;Pwd=root;"); var id = con.Insert(new t1() { jdoc = JsonConvert.SerializeObject(new { Data = "汪鹏" }) }); var result = con.QueryFirstOrDefault<t1>("select * from t1 where id = @id", new { id }); Console.ReadKey();
}

随着移动端的兴起,有了表情的出现,所以从MySQL 5.5.3开始,引入utf8mb4字符集每个字符最多可使用4个字节,支持补充字符,对于BMP字符,utf8 [utf8mb3]和utf8mb4具有相同的存储特征:相同的代码值,相同的编码,相同的长度,对于补充字符,utf8 [utf8mb3]根本无法存储该字符,而utf8mb4需要4个字节来存储它,由于utf8 [utf8mb3]根本无法存储字符,因此在utf8 [utf8mb3]列中没有任何补充字符。接下来我们在针对JSON类型配置为utf8编码的情况下,我们来插入表情,此时会发现也是可以的。我们是可以获取对应字符的字节数,比如如下哭笑不得的表情为4个字节:
var emotion = Encoding.UTF8.GetByteCount("
MySQL对JSON类型UTF-8编码导致中文乱码探讨的更多相关文章
- js ajax post提交 ie和火狐、谷歌提交的编码不一致,导致中文乱码
今天遇到一个问题找了很久发现: 使用js ajax post提交 ie和火狐.谷歌提交的编码不一致,导致中文乱码 //http://www.cnblogs.com/QGC88 $.ajax({ url ...
- 读取 properties 配置文件含有中文的value内容 导致中文乱码 的解决办法
1.前言 因为装系统的时候把中文写在了系统路径,现在我想把这个路径写在properties里面来读取,可是 发现java 读取会导致中文乱码成 问号????的乱码 ,百度找了好多博客,基本都是一摸一 ...
- 关于SpringMVC中text/plain的编码导致的乱码问题解决方法
有老铁的项目出现个问题,就是用SpringMVC给前台返回一句话,是String类型的,然后前台接收到是乱码. 然后以为是简单的response的编码问题,就在方法体中开始给response设置编码, ...
- MySQL:windows中困扰着我们的中文乱码问题
前言:什么是mysql中的中文乱码问题? 话不多说,直接上图 这个东西困扰了我好久,导致我现在对windows映像非常不好,所以就想改成Linux,行了,牢骚就发到这里,直接说问题,明眼人一眼就看出来 ...
- MySQL直接导出CSV文件,并解决中文乱码的问题
需求: 需要导出hr_users 表中的部分字段的数据,以前是用PHP写脚本,然后导出CSV文件. 在MySQL中,它自己就能导出CSV文件 ,只不过是有如下几个问题需要大家解决. 1. 生成文件不成 ...
- JQuery和JSON方式参数传递并处理JAVAWEB中文乱码问题
本文主要讲springMVC中视图和控制器之间常用的两种传递参数的方式: 1.JQuery 2.JSON 一.JQuery方式 思路:单击按钮后,触发JQuery事件,而提交整个表单 JSP中 < ...
- Transfer-Encoding:chunked 返回数据过长导致中文乱码
最近在写一个项目的后台时,前端请求指定资源后,返回JSON格式的数据,突然发现在返回的字节数过大时,最后的message中文数据乱码了,对于同一个接口的请求:当数据小时不会乱码,当数据量大了中文就乱码 ...
- Web开发的编码解决中文乱码
中文乱码有两个环节会出现 第一,从请求体中获得的数据 从请求体中获得的数据要为其进行编码,默认为ISO-8859-1,所以在使用getParameter()时先调用setCharacterEncodi ...
- MySQL 根据JSON类型的字段进行过滤数据的方式
第一种方式:JSON_CONTAINS 函数 : 执行相等形式的比较 注意:值的类型一定要相同,不然会报错 文档地址:https://dev.mysql.com/doc/refman/8.0/en/j ...
随机推荐
- git 学习 3
远程仓库 添加远程库 GitHub 注册账号并建立 repository,Clone with SSH 1 $ ssh-keygen -t rsa -C "youremail@example ...
- Seeing AI:计算机视觉十年磨一剑,打造盲人的“瑞士军刀”
Mary Bellard(左)和AnneTaylor(右)是Seeing AI开发团队的成员,SeeingAI成果的背后是计算机视觉数十年研究的支持. 当Anne Taylor走进一个房间时,她像其 ...
- SQL语句中in not in exits not exits用法比较
exists (sql 如果返回结果集为真) not exists (sql 如果没有返回结果集为真) 如下: 表A ID NAME 1 A1 2 A2 3 A3 表B ID AID NAME 1 1 ...
- 图形用户界面(GUI)应用程序开发——菜鸟的第一步
参考资源:贺老师博文 在看完贺老师的博文后,我就照葫芦画瓢的做了个求三角形面积的程序.这是我写的一篇所用时间最长博文(两个多小时,真心挺累,或许是我太笨吧),为了尽可能详细的把步骤写明白我截了二十一张 ...
- CSS的五种定位方式
CSS中一共有五种定位: position:static:默认值 position:absolute:绝对定位 position:relative:相对对定位 position:fixed:固定定位 ...
- optparse(命令行参数解析工具)
在用Python做自动化的时候,命令行的解析一定是少不了的,有很多命令行解析工具库,其中Python内建的一个库optparse,还是比较好用的 1.贴代码并注释 # coding=UTF-8 fro ...
- pika使用报错queue_declare() missing 1 required positional argument: 'queue'
报错如下截图,使用pika的版本太高导致,重新安装pika==0.10.0解决.
- 网站提权之MSF骚操作
当我们在进行web渗透测试的时候,拿到了webshell,但是在执行net user.whoami.类似的命令会发现怎么好像用不了,没有回显,权限不够,这可怎么办呐? 测试环境: 内网,没钱买服务器, ...
- 基于Noisy Channel Model和Viterbi算法的词性标注问题
给定一个英文语料库,里面有很多句子,已经做好了分词,/前面的是词,后面的表示该词的词性并且每句话由句号分隔,如下图所示 对于一个句子S,句子中每个词语\(w_i\)标注了对应的词性\(z_i\).现在 ...
- Python 【面向对象】
前言 Python从设计之初就已经是一门面向对象的语言,正因为如此,在Python中创建一个类和对象是很容易的.本章节我们将详细介绍Python的面向对象编程. 如果你以前没有接触过面向对象的编程语言 ...