基于python的request库,模拟登录csdn博客
以前爬虫用urllib2来实现,也用过scrapy的爬虫框架,这次试试requests,刚开始用,用起来确实比urllib2好,封装的更好一些,使用起来简单方便很多。
安装requests库
最简便的方法就是使用pip来安装:pip install requests;如果需要安装特定版本,则在后面加上版本号即可:pip install requests == 1.9.7,这样就搞定了。
快速上手的小例子
下面说一个最简单的例子:

第一行,引入requests库,这是必然的。
第二行,通过get方法获取百度首页的内容。
第三行,把返回的response内容,输出出来。
果然很简单,这样就可以发送一个get请求,同理,也可以使用requests.post,requests.put,requests.options,requests.head,发送请求。
模拟登录csdn
我们需要其他的辅助工具
浏览器:Firefox
浏览器插件:tamper data,firebug
我们需要tamper data来拦截请求,因为chrome没有这个功能的插件,所以这个只能使用firefox来做(除了拦截请求chrome没有,其他的工作都可以使用chrome)。
分析登录过程
1.打开登录页面
我们首先打开csdn的登录页面:https://passport.csdn.net/account/login?ref=toolbar,这个链接,前面的部分是登录的网址,问号后面的参数,referer,就是你从哪里跳过来的,也许是一个页面跳转到登录的,toolbar就是我自己点击顶部导航栏,然后跳转到登录页面的。
2.清除相关的cookie
为了清除不必要的干扰,我们先清除掉所有的相关的cookie,这样方便我们分析哪些参数是必须的。

3.登录过程分析
清除了cookie后,我们刷新一下页面,https://passport.csdn.net/account/login?ref=toolbar,重新获取对应的cookie。
然后我们就开始用tamper data来拦截请求。

我们点击start tamper ,在网页中填写用户名和密码,点击“登录”,会发出一个请求,然后tamper data 会拦截下这个请求,询问我们是否拦截,点击tamper,我们可以在这个请求提交之前,查看请求的内容,还可以做删除。
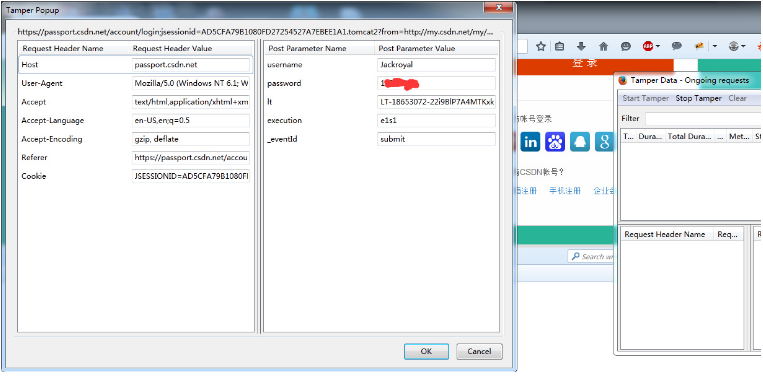
发送一个登录表单过去,就登录成功了。
4.开始模拟登录
知道登录过程了,我们就开始写登录的代码。

至此,登录就成功了。
5.优化
当你登录成功后,你会问,我怎么知道登录成功了呢?当你试图去抓取http://write.blog.csdn.net/postlist的内容的时候,你会发现一个403的错误,这是为啥呢?
很简单,user agent没有修改,我们用的是默认的user agent,这不是一个正常的用户,所以被网站拒绝了。我们加上它就好了:

后话
我们都知道cookie是有有效期的,在做调试时,每修改一次,就要模拟登录一次,这样不好,我们要保存cookie,这样下次就不需要重新发送登录请求了。
完整代码如下:

基于python的request库,模拟登录csdn博客的更多相关文章
- 在Python中用Request库模拟登录(一):字幕库(无加密,无验证码)
字幕库的登录表单如下所示,其中省去了无关紧要的内容: <form class="login-form" action="/User/login.html" ...
- 在Python中用Request库模拟登录(四):哔哩哔哩(有加密,有验证码)
!已失效! 抓包分析 获取验证码 获取加密公钥 其中hash是变化的,公钥key不变 登录 其中用户名没有被加密,密码被加密. 因为在获取公钥的时候同时返回了一个hash值,推测此hash值与密码加密 ...
- 在Python中用Request库模拟登录(三):Discuz论坛(未加密,有验证码,有隐藏验证)
以Discuz的官方站为例.直接点击网页右上角的登录按钮,会弹出一个带验证码的登录窗口.输入验证码之后,会检查验证码是否正确.然后登录.首先,通过抓包分析,这些过程浏览器和服务器交换了哪些数据. 抓包 ...
- VC使用libcurl模拟登录CSDN并自动评论资源以获取积分
环境:Win7 64位+VC2008 软件及源码下载:(http://pan.baidu.com/s/1jGE52pK) 涉及到的知识点: C++多线程编程 libcurl的使用(包括发送http请求 ...
- libcurl模拟登录CSDN并自动评论资源以获取积分
软件及源码下载:(http://pan.baidu.com/s/1jGE52pK) 涉及到的知识点: C++多线程编程 libcurl的使用(包括发送http请求.发送cookie给服务器.保存coo ...
- 3 使用selenium模拟登录csdn
之前通过F12开发者模式调试,获取网站后台服务器验证用户名和密码的URL之后,再构造post数据的方式会存在一个问题,就是对目标网站的验证机制不明确,构造post数据除了用户名和密码之外,还可能有更复 ...
- Python爬取CSDN博客文章
0 url :http://blog.csdn.net/youyou1543724847/article/details/52818339Redis一点基础的东西目录 1.基础底层数据结构 2.win ...
- python实战--csdn博客专栏下载器
打算利用业余时间好好研究Python的web框架--web.py,深入剖析其实现原理,体会web.py精巧之美.但在研究源码的基础上至少得会用web.py.思前想后,没有好的Idea,于是打算开发一个 ...
- Python采集CSDN博客排行榜数据
文章目录 前言 网络爬虫 搜索引擎 爬虫应用 谨防违法 爬虫实战 网页分析 编写代码 运行效果 反爬技术 前言 很多人学习python,不知道从何学起.很多人学习python,掌握了基本语法过后,不知 ...
随机推荐
- dp求顺序hdu1160
题意是仅仅求一次的顺序.先依照速度从大到小排序,速度想等到按体重增序排列. 然后基本就变成了求已定顺序序列的最长递增序列递增,跟那个求一致最大序列和的基本一致. dp[i]里存储的是到当前i最大的递增 ...
- JSP复习笔记
1.注释 <!--这个注释会显示在HTML源码中--> <%--隐藏注释,不会显示在HTML源码中--%> 2.声明 <%! java声明 声明变量,方法等 %> ...
- TGraphiControl响应WM_MOUSEMOVE的过程(以TPaintBox为例)good
起因:非Windows句柄控件也可以处理鼠标消息,我想知道是怎么处理的:并且想知道处理消息的顺序(比如TPaintBox和TForm都响应WM_Mouse消息该怎么办)界面:把TPaintBox放到T ...
- BZOJ5379: Tree
BZOJ5379: Tree Description JudgeOnline/upload/201806/1.pdf 题解Here! 题目大意就是:1. 换根.2. 对$LCA(u,v)$的子树修改. ...
- [翻译]理解Unity的自动内存管理
当创建对象.字符串或数组时,存储它所需的内存将从称为堆的中央池中分配.当项目不再使用时,它曾经占用的内存可以被回收并用于别的东西.在过去,通常由程序员通过适当的函数调用明确地分配和释放这些堆内存块.如 ...
- ubuntu gcc低版本过低引起错误
错误内容: 正在读取软件包列表... 完成正在分析软件包的依赖关系树 正在读取状态信息... 完成 您可能需要运行“apt-get -f install”来纠正下列错误:下列软件包有未满足的依赖关系: ...
- ios实现倒计时的两种方法
方法1:使用NSTimer来实现 主要使用的是NSTimer的scheduledTimerWithTimeInterval方法来每1秒执行一次timeFireMethod函数,timeFireMeth ...
- CentOS 7.2安装Jenkins自动构建Git项目
1.环境 本文使用VMWare虚拟机进行实验. 最终实现目标,在Jenkins服务器上新建构建任务,从Git服务器上拉取master HEAD(不编译,仅演示),部署到"目标服务器" ...
- Linux内核日志开关
Linux内核日志开关 1.让pr_debug能输出 --- a/kernel/printk/printk.c +++ b/kernel/printk/printk.c @@ -59,7 +59,7 ...
- 51Nod 1089 最长回文子串 V2 —— Manacher算法
题目链接:https://vjudge.net/problem/51Nod-1089 1089 最长回文子串 V2(Manacher算法) 基准时间限制:1 秒 空间限制:131072 KB 分值: ...