像素缓冲区对象PBO 记录
像素缓冲区对象PBO 记录
和所有的缓冲区对象一样,它们都存储在GPU内存中,我们可以访问和填充PBO,方法和其他的缓冲区一样。
- 当一个PBO被绑定到GL_PIXEL_PACK_BUFFER,任何读取像素的OpenGL操作都会从PBO中获取它们的数据,如glReadPixels,glGetTexImage和glGetCompressedTexImage。通常的操作会从FBO或纹理中抽取数据,并将它们读取客户端内存中。当PBO绑定到GL_PIXEL_PACK_BUFFER时,像素数据在GPU内存中的PBO,而不会下载到客户端的内存。
- 当一个PBO绑定点是GL_PIXEL_UNPACK_BUFFER,任何绘制像素的OpenGL操作都会向一个绑定的PBO对象写入数据。如glTexImage*D,glTexSubImage*D等等。通常的这些操作将数据和纹理从CPU内存中上传到帧缓冲区中,当PBO绑定到GL_PIXEL_UNPACK_BUFFER时,上传数据和纹理过程经过PBO。如图(from:http://www.songho.ca/opengl/gl_pbo.html)
PBO的主要优势:
- 可以通过DMA (Direct Memory Access) 快速地在显卡上传递像素数据,而不需要耗费CPU的时钟周期。
- 另一个优势是它还具备异步DMA传输。
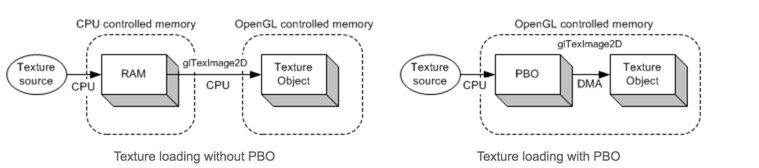
左侧图是从图像文件或视频中加载纹理。首先,资源被加载到系统内存(Client)中,然后使用glTexImage2D()函数从系统内存上传到OpenGL纹理对象中(Client->Server)。这两次数据传输(加载和复制)完全由CPU执行。
右侧图中图像可以直接加载到PBO中,而PBO是由OpenGL控制的。虽然CPU有参与加载纹理到PBO,但不涉及将像素数据从PBO传输到纹理对象的工作,而是由GPU(OpenGL驱动)来负责PBO到纹理对象的数据传输的,这也就意味着OpenGL执行DMA传输操作不会占用CPU的时钟周期。此外,OpenGL还可以安排稍后执行的异步DMA传输。所以glTexImage2D立即返回,CPU也无需等待像素数据的传输了,可以继续其他工作。
使用
当绘制内容在屏幕上显示时,可能需要在像素彻底消失之前再次取回,原因可能是检查实际的渲染情况,也可能是应用到后续帧的效果需要使用前面帧的像素进行合成;总之这时需要glReadPixels函数发挥作用。
glReadPixels本身是同步操作,需要操作完成后才返回,这期间对程序性能会有很大冲击,是影响性能的关键点。
//从缓存区中读取像素数据到PBO,避免了复制到客户端的内存上可能带来的性能问题
glBindBuffer(GL_PIXEL_PACK_BUFFER, pixBufferObj[]);
glReadPixels(, , width, height, GL_RGB, GL_UNSIGNED_BYTE, NULL);
glBindBuffer(GL_PIXEL_PACK_BUFFER, ); //接下来将PBO绑定为解包缓冲区,然后直接将像素读取到PBO,然后直接将像素加载到纹理中
glBindBuffer(GL_PIXEL_UNPACK_BUFFER, pixBufferObj[]);
glActiveTexture(GLTexture0 + X);
glTexImage2D(GL_Texture_2D,
,
GL_RGB8,
width,
height,
,
GL_RGB,
GL_UNSIGNED_BYTE,
NULL);
glBindBuffer(GL_PIXEL_UNPACK_BUFFER, );
这样能将像素重定向到GPU中的PBO中,避免复制到客户端内存可能带来的性能问题。
参考
- 《OpenGL 超级宝典 (第5版))》
- http://www.songho.ca/opengl/gl_pbo.html
像素缓冲区对象PBO 记录的更多相关文章
- [译]OpenGL像素缓冲区对象
目录概述创建PBO映射PBO例子:Streaming Texture Uploads with PBO例子:Asynchronous Readback with PBO 概述 OpenGL ARB_p ...
- OpenGL顶点缓冲区对象(VBO)
转载 http://blog.csdn.net/dreamcs/article/details/7702701 创建VBO GL_ARB_vertex_buffer_object 扩展可 ...
- OPenGL中的缓冲区对象
引自:http://blog.csdn.net/mzyang272/article/details/7655464 在许多OpenGL操作中,我们都向OpenGL发送一大块数据,例如向它传递需要处理的 ...
- OpenGL ES 3.0 帧缓冲区对象基础知识
最近在帧缓冲区对象这里卡了一下,不过前面已经了解了相关的OpenGL ES的知识,现在再去了解就感觉轻松多了.现在就进行总结. 基础知识 我们知道,在应用程序调用任何的OpenGL ES命令之前,需要 ...
- WebGl 利用缓冲区对象画多个点
效果: 代码: <!DOCTYPE html> <html lang="en"> <head> <meta charset="U ...
- OpenGL学习笔记3——缓冲区对象
在GL中特别提出了缓冲区对象这一概念,是针对提高绘图效率的一个手段.由于GL的架构是基于客户——服务器模型建立的,因此默认所有的绘图数据均是存储在本地客户端,通过GL内核渲染处理以后再将数据发往GPU ...
- OpenGL顶点缓冲区对象
[OpenGL顶点缓冲区对象] 显示列表可以快速简单地优化立即模式(glBegin/glEnd)的代码.在最坏的情况下,显示列表的命令被预编译存到命令缓冲区中,然后发送给图形硬件.在最好的情况下,是编 ...
- WebGL简易教程(三):绘制一个三角形(缓冲区对象)
目录 1. 概述 2. 示例:绘制三角形 1) HelloTriangle.html 2) HelloTriangle.js 3) 缓冲区对象 (1) 创建缓冲区对象(gl.createBuffer( ...
- node 全局对象global —— 记录在线人员
最近做毕设的时候,在做查看在线人员这个功能的时候,一直卡顿,我的思路是数据库保存 是否在线 字段,可以在登录时和退出系统修改状态,但如果用户之间关闭窗口时候就没办法向后台发出修改在线状态的请求.我想到 ...
随机推荐
- Centos7二进制文件安装MySQL5.7.25
1.删除centos系统自带的mariadb数据库防止发生冲突 rpm -qa|grep mariadb rpm -e mariadb-libs --nodeps 2.安装libaio库 yum -y ...
- Python学习第二阶段Day2(json/pickle)、 shelve、xml、PyYAML、configparser、hashlib模块
1.json/pickle 略. 2.shelve模块 import shelve # shelve 以key value的形式序列化,value为对象 class Foo(object): de ...
- linux less-分屏上下翻页浏览文件内容
博主推荐:获取更多 linux文件内容查看命令 收藏:linux命令大全 less命令的作用与more十分相似,都可以用来浏览文字档案的内容,不同的是less命令允许用户向前或向后浏览文件,而more ...
- python爬虫28 | 你爬下的数据不分析一波可就亏了啊,使用python进行数据可视化
通过这段时间 小帅b教你从抓包开始 到数据爬取 到数据解析 再到数据存储 相信你已经能抓取大部分你想爬取的网站数据了 恭喜恭喜 但是 数据抓取下来 要好好分析一波 最好的方式就是把数据进行可视化 这样 ...
- Oracle学习总结(4)——MySql、SqlServer、Oracle数据库行转列大全
MySql行转列 以id分组,把name字段的值打印在一行,逗号分隔(默认) select CustomerDrugCode,group_concat(AuditItemName) from noau ...
- SQL 快速参考-----http://www.runoob.com/sql/sql-quickref.html
http://www.runoob.com/sql/sql-quickref.html SQL 快速参考
- pat甲级 1107. Social Clusters (30)
When register on a social network, you are always asked to specify your hobbies in order to find som ...
- hrbust oj 1536 Leonardo's Notebook 置换群问题
题目大意: 给出一个A~Z的置换G,问能否找到一个A~Z的置换G' 能够用来表示为 G = G'*G' 由定理: 任意一个长为 L 的置换的k次幂,都会把自己的每一个循环节分裂成gcd(L, K)份, ...
- hdu 3062 2-sat
#include<stdio.h> #include<string.h> #define N 2100 struct node { int u,v,next; }bian[N* ...
- [COGS309] [USACO 3.2] 香甜的黄油
★★ 输入文件:butter.in 输出文件:butter.out 简单对比 时间限制:1 s 内存限制:128 MB 描述 农夫John发现做出全威斯康辛州最甜的黄油的方法:糖.把糖 ...