Python 常用算法记录
一、递归
汉诺塔算法:把A柱的盘子,移动到C柱上,最少需要移动几次,大盘子只能在小盘子下面
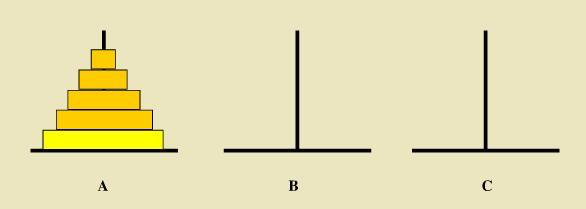
1、当盘子的个数为n时,移动的次数应等于2^n – 1
2、描述盘子从A到C:
(1)如果A只有一个圆盘,可以直接移动到C;
(2)如果A有N个圆盘,可以看成A有1个圆盘(底盘) + (N-1)个圆盘,首先需要把 (N-1) 个圆盘移动到 B,然后,将 A的最后一个圆盘移动到C,再将B的(N-1)个圆盘移动到C。
3、代码
i = 0 def move(n, a, b, c):
global i
if n == 1:
i += 1
print('移动第', i, '次', a, '-->', c)
else:
# 1.把A柱上n-1个圆盘移动到B柱上
move(n - 1, a, c, b)
# 2.把A柱上最大的移动到C柱子上
move(1, a, b, c)
# 3.把B柱子上n-1个圆盘移动到C柱子上
move(n - 1, b, a, c) move(4, 'A', 'B', 'C')
二、常用排序算法
1、冒泡排序 Bubble Sort
(1)两两比较,大元素往后排,类似水里的气泡从下面浮上来
(2)代码
def bubble_sort(alist):
"""冒泡排序"""
n = len(alist)
for j in range(n - 1):
count = 0
for i in range(0, n - 1 - j):
if alist[i] > alist[i + 1]:
alist[i], alist[i + 1] = alist[i + 1], alist[i]
count += 1
# count为0,表示数据本来就是有序的,无需多比较
if 0 == count:
return if __name__ == "__main__":
li = [8, 1, 5, 4, 3, 9, 0, 2, 7, 6]
bubble_sort(li)
print(li)
2、选择排序 Selection Sort
(1)设置一个标记位记录每一轮遍历后(内循环)最小数值的角标,在内循环一轮结束后,直接将标记位指向的元素,放到本轮遍历(内循环)的第一个位置。
(2)代码
def select_sort(alist):
"""选择排序"""
n = len(alist)
for j in range(n-1):
min_index = j # 这是标记位
for i in range(j+1, n):
if alist[min_index] > alist[i]:
min_index = i # 记录下最小的数值对应的角标
# 本轮内循环结束,本轮比较的数组的第一个元素为 alist[j]
alist[j], alist[min_index] = alist[min_index], alist[j] if __name__ == "__main__":
li = [54, 26, 93, 17, 77, 31, 44, 55, 20]
select_sort(li)
print(li)
3、插入排序 Insertion Sort
(1)逐个取出元素(比如从第二个开始),和前面的每个元素比较,插入到合适的位置。这样,保证一轮比较后,取出元素位置的左边都是排序过的有序数据。
(2)代码
def insert_sort(alist):
"""插入排序"""
n = len(alist)
# 需要取出每一个元素和左边的逐个比较,j就是每个元素的角标,控制外循环
for j in range(1, n):
# j = [1, 2, 3, n-1]
# i 代表内层循环起始值,每一次外循环更新内循环的起始值
i = j
while i > 0 and alist[i] < alist[i-1]:
# 插入到前面的正确位置中,依然需要逐个比较、交换
alist[i], alist[i-1] = alist[i-1], alist[i]
i -= 1 if __name__ == "__main__":
li = [54, 26, 93, 17, 77, 31, 44, 55, 20]
insert_sort(li)
print(li)
4、希尔排序 SHELL
(1)选择一个步长(gap) ,然后按间隔gap取元素,放到一个组里,以此将这个数据分成多组。每个组采用插入排序处理数据。紧接着步长逐渐变小,循环前面操作,直至为1。
(2)简单图示:
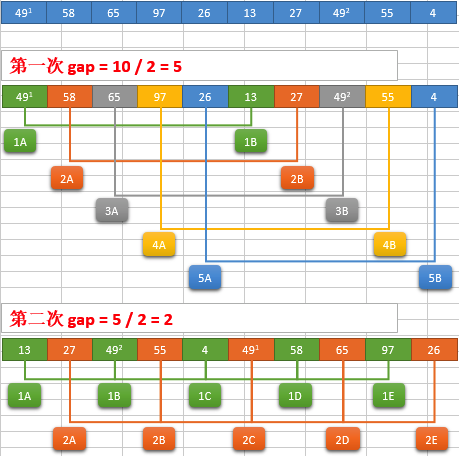
(3)代码
def shell_sort(alist):
"""希尔排序"""
n = len(alist)
gap = n // 2
while gap > 0:
# 插入算法,与普通的插入算法的区别就是gap步长
for j in range(gap, n):
# j = [gap, gap+1, gap+2, gap+3, ..., n-1]
i = j while i > 0 and alist[i] < alist[i - gap]:
alist[i], alist[i - gap] = alist[i - gap], alist[i]
i -= gap # 缩短gap步长,不一定必须折半
gap //= 2 if __name__ == "__main__":
li = [54, 26, 93, 17, 77, 31, 44, 55, 20]
shell_sort(li)
print(li)
5、快速排序 Quick Sort
(1)选择一个关键值,通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程递归进行。
(2)图示
<1> 详细拆解

<2> 代码中的low和high

(3)代码
def quick_sort(alist, first, last):
"""快速排序"""
if first < last: # 设置中间值,作为基数:最终比他小的元素放在左边,比他大的元素放在右边
# 此处就是取的第一个元素作为基数
mid_value = alist[first] # 设置高、低两个标记位
low,high = first,last # 每一次外循环完成的是:一次高、低位的交换(和中间值比较后)
while low < high: # Step1 high左移:如果高标记位所在的值大于等于中间值,则继续左移
while low < high and alist[high] >= mid_value:
high -= 1 # Step2 当高标记位的值小于中间值时:标记位不再移动,同时,将高标记位的值放到低标记位
alist[low] = alist[high] # Step3 low右移:如果低记位所在的值小于于中间值,则继续左移
# 注意:此处是没有等于mid_value的情况,目的是将同等大小情况的值,都放到一边,这是一种规范
while low < high and alist[low] < mid_value:
low += 1 # Step4 当低标记位的值大于中间值时:标记位不再移动,同时,将低标记位的值放到高标记位
alist[high] = alist[low] # 从循环退出时,low>=high,将中间值直接放到low位
# 此时,mid_value的左边都是比他小的,右边都是比他大的
alist[low] = mid_value # 递归一 :对中间值左边的列表执行快速排序
quick_sort(alist, first, low-1) # 递归二 :对中间值右边的列表排序
quick_sort(alist, low+1, last) return alist if __name__ == "__main__":
li = [54, 26, 93, 17, 77, 31, 44, 55, 20]
quick_sort(li, 0, len(li)-1)
print(li)
6、归并排序
(1)先递归分解数组,子数组之间比较后合并成有序数组,新合并的子数组之间再递归比较,直到最终合并成唯一一个新的有序数组。
(2)步骤:先将原数组分解最小之后,然后合并两个有序数组(依次重新合并,成为最终唯一的有序数组)。其中,每次两个小分组比较时,基本思路是比较两个数组的最前面的数,谁小就先取谁,取了后相应的指针就往后移一位。然后再比较,直至一个数组为空,最后把另一个数组的剩余部分复制过来即可。
(3)图示
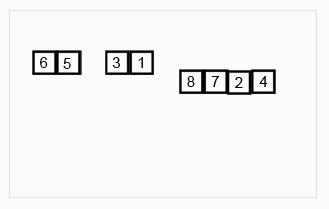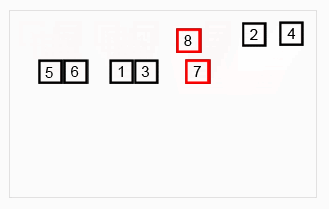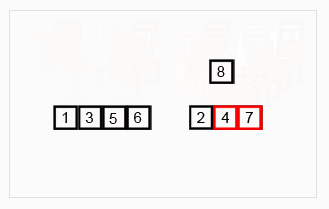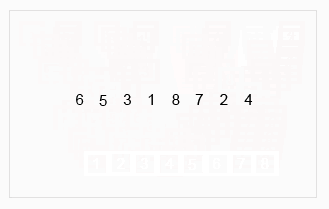
(4)代码
def merge_sort(alist):
"""归并排序"""
n = len(alist) # 个数大于一时进行比较,否则直接返回
if n > 1: # ---------- 递归分解数组 ---------- # 每次采用折半的方式进行拆分,直到拆成一个元素的数组
mid = n//2 # left:左半部分,递归,采用归并排序后形成的有序的新的列表
left_li = merge_sort(alist[:mid]) # right:右半部分,递归,采用归并排序后形成的有序的新的列表
right_li = merge_sort(alist[mid:]) # ---------- 递归排序子序列并且合并 ---------- # 将两个有序的子序列合并为一个新的整体
# 左、右指针,用于依次取出左右两个数组的每个元素进行比较
left_pointer, right_pointer = 0, 0 # 存放合并后的有序数组
result = [] # 循环,直到穷尽左、右其中一个数组
while left_pointer < len(left_li) and right_pointer < len(right_li): # 比较左右子序列,把小的依次放到result里,并且正确的移动相应的指针
if left_li[left_pointer] <= right_li[right_pointer]:
result.append(left_li[left_pointer])
left_pointer += 1
else:
result.append(right_li[right_pointer])
right_pointer += 1 # 跳出循环,不论左、右序列是否有剩余的元素,直接添加到结果最后
# 注意:python的数组切片时,如果越界,返回空数组
result += left_li[left_pointer:]
result += right_li[right_pointer:] # 返回新的有序数组
return result return alist if __name__ == "__main__":
li = [54, 26, 93, 17, 77, 31, 44, 55, 20]
sorted_li = merge_sort(li)
print(sorted_li)
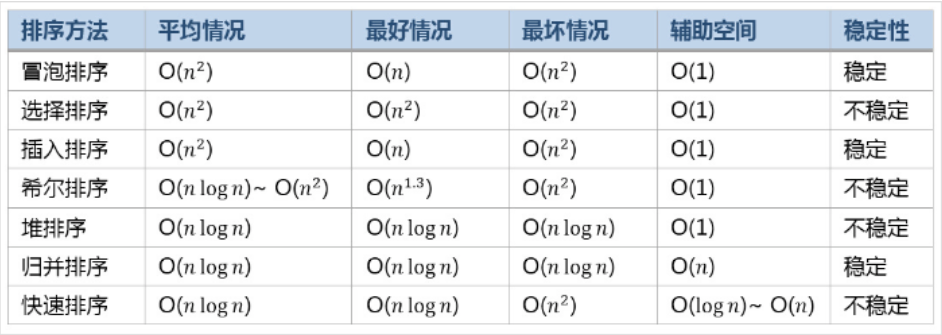
三、常见排序算法效率比较
四、搜索
1、二分法查找、折半查找
(1)针对有序序列,选择中间点,比较查找目标在左右哪个区间,然后递归在该区间查找目标,直到该目标和中间点的值相同(查找到了),否则无结果(没查找到)
(2)代码实现
<1> 递归版本
def binary_search(alist, item):
"""二分查找,递归"""
n = len(alist)
if n > 0: # 每次递归,设置中间角标
mid = n//2 # Section1 查找的值等于中间值,查找成功!
if alist[mid] == item:
return '找到了:' + str(item) # Section2 查找的值小于中间值,递归查找中间值左边的子序列
elif item < alist[mid]:
return binary_search(alist[:mid], item) # Section3 查找的值大于中间值,递归查找中间值右边的子序列
else:
return binary_search(alist[mid+1:], item) # 传入序列元素为空,结束,未查找到!
return '没有找到:' + str(item) if __name__ == "__main__":
li = [17, 20, 26, 31, 44, 54, 55, 77, 93]
print(binary_search(li, 55))
print(binary_search(li, 100))
<2> 非递归
def binary_search_2(alist, item):
"""二分查找, 非递归"""
n = len(alist)
first = 0
last = n-1 # 更改查找的左右区间,直到左指针超过了右指针,循环停止
while first <= last: # 取出中间值坐标
mid = (first + last)//2
if alist[mid] == item:
return "找到了:" + str(item)
elif item < alist[mid]:
# 右指针设置为中间值左边第一个
last = mid - 1
else:
# 左指针设置为中间值右边第一个
first = mid + 1 return "未找到:" + str(item) if __name__ == "__main__": li = [17, 20, 26, 31, 44, 54, 55, 77, 93]
print(binary_search_2(li, 55))
print(binary_search_2(li, 100))
五、树与树算法
1、树的特质
(1)完全二叉树:若设二叉树的高度为h,除第 h 层外,其它各层 (1~h-1) 的结点数都达到最大个数,第h层有叶子结点,并且叶子结点都是从左到右依次排布。
(2)满二叉树:除了叶结点外每一个结点都有左右子叶且叶子结点都处在最底层的二叉树。
(3)平衡二叉树:又被称为AVL树(区别于AVL算法),它是一棵空树或它的左右两个子树的高度差的绝对值不超过1,并且左右两个子树都是一棵平衡二叉树。
(3)特质:
<1>: 在二叉树的第i层上至多有2^(i-1)个结点(i>0)
<2>: 深度为k的二叉树至多有2^k - 1个结点(k>0)
<3>: 对于任意一棵二叉树,如果其叶结点数为N0,而度数为2的结点总数为N2,则N0=N2+1;
<4>: 具有n个结点的完全二叉树的深度必为 log2(n+1)
<5>: 对完全二叉树,若从上至下、从左至右编号,则编号为i 的结点,其左孩子编号必为2i,其右孩子编号必为2i+1;其双亲的编号必为i/2(i=1 时为根,除外)
(4)几种遍历方式:广度遍历,先序遍历(根左右),中序遍历(左根右),后续遍历(左右根)
(5)生成树(包括添加元素、广度遍历)时,使用队列,来存储每个待处理节点,通过队列的pop和append,逐步完成整二叉树的操作。
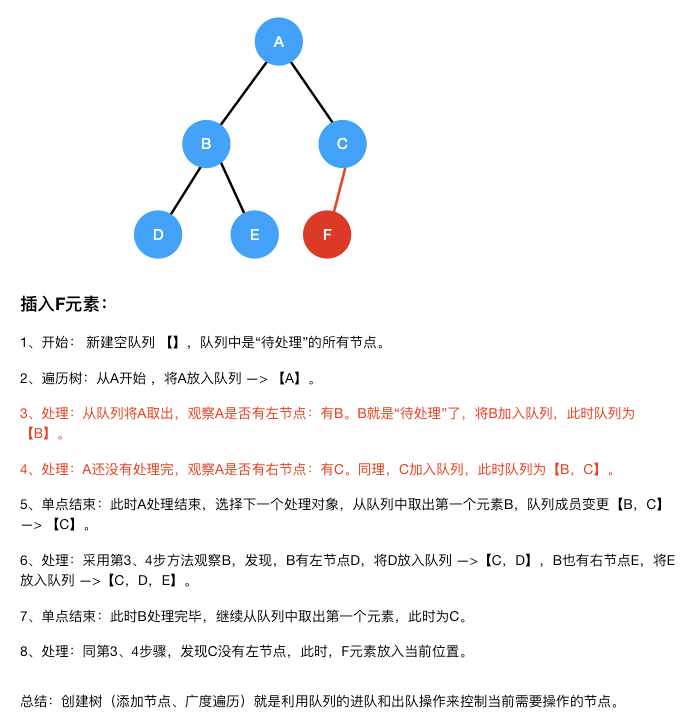
2、代码实现
class Node(object):
"""节点"""
def __init__(self, item):
self.elem = item
self.lchild = None
self.rchild = None class Tree(object):
"""二叉树"""
def __init__(self):
self.root = None def add(self, item):
"""添加节点"""
node = Node(item)
if self.root is None:
self.root = node
return # 取出根节点放到队列中
queue = [self.root] # 只要队列不为空,就一直从队列中取出节点处理
while queue: # 取出当前要处理节点
cur_node = queue.pop(0) # 如果左节点不存在,直接设置item到左节点
if cur_node.lchild is None:
cur_node.lchild = node
return
else:
# 如果左节点存在,将其加入队列中,作为"待处理"的节点
queue.append(cur_node.lchild) # 同上,判断右节点
if cur_node.rchild is None:
cur_node.rchild = node
return
else:
queue.append(cur_node.rchild) def breadth_travel(self):
"""广度遍历"""
if self.root is None:
return
queue = [self.root]
while queue:
cur_node = queue.pop(0)
print(cur_node.elem, end=" ")
if cur_node.lchild is not None:
queue.append(cur_node.lchild)
if cur_node.rchild is not None:
queue.append(cur_node.rchild) def preorder(self, node):
"""先序遍历"""
if node is None:
return
print(node.elem, end=" ")
self.preorder(node.lchild)
self.preorder(node.rchild) def inorder(self, node):
"""中序遍历"""
if node is None:
return
self.inorder(node.lchild)
print(node.elem, end=" ")
self.inorder(node.rchild) def postorder(self, node):
"""后序遍历"""
if node is None:
return
self.postorder(node.lchild)
self.postorder(node.rchild)
print(node.elem, end=" ") if __name__ == "__main__": tree = Tree()
print("\n创建数据结构 0 - 9 数字")
for index in range(10):
tree.add(index)
print("\n广度遍历:")
tree.breadth_travel()
print("\n前序遍历:")
tree.preorder(tree.root)
print("\n中序遍历:")
tree.inorder(tree.root)
print("\n后序遍历:")
tree.postorder(tree.root)
print("\n")
Python 常用算法记录的更多相关文章
- Python常用算法
本节内容 算法定义 时间复杂度 空间复杂度 常用算法实例 1.算法定义 算法(Algorithm)是指解题方案的准确而完整的描述,是一系列解决问题的清晰指令,算法代表着用系统的方法描述解决问题的策略机 ...
- Python常用函数记录
Python常用函数/方法记录 一. Python的random模块: 导入模块: import random 1. random()方法: 如上如可知该函数返回一个[0,1)(左闭右开)的一个随机的 ...
- 第四百一十四节,python常用算法学习
本节内容 算法定义 时间复杂度 空间复杂度 常用算法实例 1.算法定义 算法(Algorithm)是指解题方案的准确而完整的描述,是一系列解决问题的清晰指令,算法代表着用系统的方法描述解决问题的策略机 ...
- python常用算法学习(3)
1,什么是算法的时间和空间复杂度 算法(Algorithm)是指用来操作数据,解决程序问题的一组方法,对于同一个问题,使用不同的算法,也许最终得到的结果是一样的,但是在过程中消耗的资源和时间却会有很大 ...
- python常用算法学习(4)——数据结构
数据结构简介 1,数据结构 数据结构是指相互之间存在着一种或多种关系的数据元素的集合和该集合中数据元素之间的关系组成.简单来说,数据结构就是设计数据以何种方式组织并存贮在计算机中.比如:列表,集合与字 ...
- python 常用算法学习(2)
一,算法定义 算法(Algorithm)是指解题方案的准确而完整的描述,是一系列解决问题的清晰指令,算法代表着用系统的方法描述解决问题的策略机制.也就是说,能够对一定规范的输入,在有限时间内获得所要求 ...
- python常用算法(7)——动态规划,回溯法
引言:从斐波那契数列看动态规划 斐波那契数列:Fn = Fn-1 + Fn-2 ( n = 1,2 fib(1) = fib(2) = 1) 练习:使用递归和非递归的方法来求解斐波那契数 ...
- python 常用算法
算法就是为了解决某一个问题而采取的具体有效的操作步骤 算法的复杂度,表示代码的运行效率,用一个大写的O加括号来表示,比如O(1),O(n) 认为算法的复杂度是渐进的,即对于一个大小为n的输入,如果他的 ...
- python 常用算法学习(1)
算法就是为了解决某一个问题而采取的具体有效的操作步骤 算法的复杂度,表示代码的运行效率,用一个大写的O加括号来表示,比如O(1),O(n) 认为算法的复杂度是渐进的,即对于一个大小为n的输入,如果他的 ...
随机推荐
- Python之模块和包导入
Python之模块和包导入 模块导入: 1.创建名称空间,用来存放模块XX.py中定义的名字 2.基于创建的名称空间来执行XX.py. 3.创建名字XX.py指向该名称空间,XX.名字的操作,都是以X ...
- 对SpringMVC框架的理解(转)
SpringMVC概念: 他是一个轻量级的开源框架,应用于表现层,基于MVC的设计模式. SpringMVC的特点: 1.他是单例的可以设置成多例. 2.他的线程是安全的 ...
- 在 Sublime Text 直接运行 Javascript 调试控制台
转载自:http://www.jianshu.com/p/43b0726792f7 sublime text javascript Sublime Text是深受喜欢的多语言编辑器,很多开发人员都选择 ...
- Happy Three Friends
Happy Three Friends Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/65536 K (Java/Othe ...
- cmake打印变量值
看下面的例子,我们在cmake定义了一个变量“USER_KEY”,并打印此变量值.status表示这是一般的打印信息,我们还可以设置为“ERROR”,表示这是一种错误打印信息. SET(USER_KE ...
- [codevs3044][POJ1151]矩形面积求并
[codevs3044][POJ1151]矩形面积求并 试题描述 输入n个矩形,求他们总共占地面积(也就是求一下面积的并) 输入 可能有多组数据,读到n=0为止(不超过15组) 每组数据第一行一个数n ...
- poj 3648 2-sat 输出任意一组解模板
转载地址:http://blog.csdn.net/qq172108805/article/details/7603351 /* 2-sat问题,题意:有对情侣结婚,请来n-1对夫妇,算上他们自己共n ...
- XMLREADER/DOM/SIMPLEXML 解析大文件
DOM和simplexml处理xml非常的灵活方便,它们的内存组织结构与xml文件格式很相近.但是同时它们也有一个缺点,对于大文件处理起来力不从心,太耗内存了. 还好有xmlreader,基于流的解析 ...
- ZOJ3956 ZJU2017校赛(dp)
题意:给出n对(h,c) 记 sumh为选出的h的总和 sumc为选出的c的总和 你可以从中选出任意多对(可以不选) 使得 sumh^2-sumh*sumc-sumc^2 最大 输出最大值 输入 ...
- poj3511--A Simple Problem with Integers(线段树求和)
A Simple Problem with Integers Time Limit: 5000MS Memory Limit: 131072K Total Submissions: 60441 ...