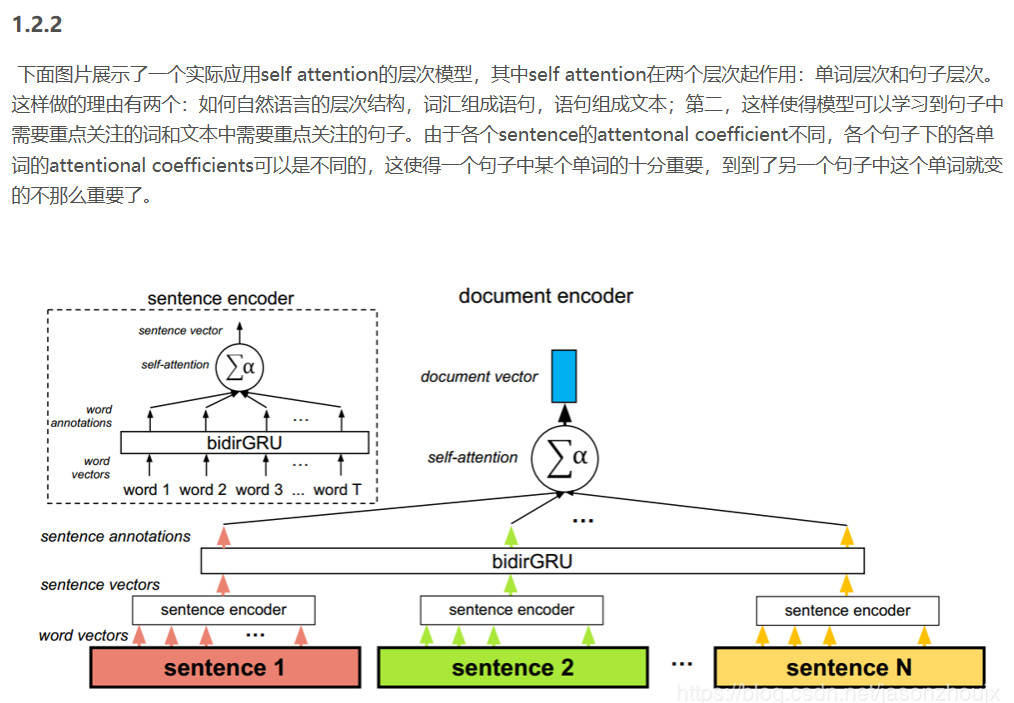
Self-Attetion
四、self-attention
1、是什么?
attention机制通常用在encode与decode之间,但是self-attention则是输入序列与输出序列相同,寻找序列内部元素的关系即 K=V=Q。l例如《Attention Is All You Need》在编码器中使用self-attention,利用上一步的input值计算当前该位置input的值。如下图:

2、为什么?
尽管attention机制由来已久,但真正令其声名大噪的是google 2017年的这篇名为《attention is all your need》的论文。
让我们从一个简单的例子看起:
假设我们想用机器翻译的手段将下面这句话翻译成中文:
“The animal didn’t cross the street because it was too tired”
当机器读到“it”时,“it”代表“animal”还是“street”呢?对于人类来讲,这是一个极其简单的问题,但是对于机器或者说算法来讲却十分不容易。
self-Attention则是处理此类问题的一个解决方案,也是目前看起来一个比较好的方案。当模型处理到“it”时,self-Attention可以将“it”和“animal‘联系到一起。
3、怎么做?
通俗地讲,当模型处理一句话中某一个位置的单词时,self-Attention允许它看一看这句话中其他位置的单词,看是否能够找到能够一些线索,有助于更好地表示(或者说编码)这个单词。
如果你对RNN比较熟悉的话,我们不妨做一个比较。RNN通过保存一个隐藏态,将前面词的信息编码后依次往后面传递,达到利用前面词的信息来编码当前词的目的。而self-Attention仿佛有个上帝之眼,纵观全局,看看上下文中每个词对当前词的贡献。

下面来看下具体是怎么实现的。
首先,来看下怎样使用向量来计算self-attention,紧接着看如何用矩阵来计算self-attention。
使用向量
如下图所示,一般而言,输入的句子进入模型的第一步是对单词进行embedding,每个单词对应一个embedding。对于每个embedding,我们创建三个向量,Query、Key和Value向量。我们如何来创建三个向量呢?如图,我们假设embedding的维度为4,我们希望得到一个维度为3的Query、Key和Value向量,只需将每个embedding乘上一个维度为4*3的矩阵即可。这些矩阵就是训练过程中要学习的。

那么,Query、Key和Value向量代表什么呢?他们在attention的计算中发挥了什么样的作用呢?
我们用一个例子来说明:
首先要明确一点,self-attention其实是在计算每个单词对当前单词的贡献,也就是对每个单词对当前单词的贡献进行打分score。假设我们现在要计算下图中所有单词对第一个单词”Thinking”的打分。那么分分数如何计算呢,只需要将该单词的Query向量和待打分单词的Key向量做点乘即可。比如,第一个单词对第一个单词的分数为q1× k1,第二个单词对第一个单词的分数为q1×k2。

我们现在得到了两个单词对第一个单词的打分(分数是个数字了),然后将其进行softmax归一化。需要注意的是,在BERT模型中,作者在softmax之前将分数除以了Key的维度的平方根(据说可以保持梯度稳定)。softmax得到的是每个单词在Thinking这个单词上的贡献的权重。显然,当前单词对其自身的贡献肯定是最大的。
接着就是Value向量登场的地方了。将上面的分数分别和Value向量相乘,注意这里是对应位置相乘。

最后,将相乘的结果求和,这就得到了self-attention层对当前位置单词的输出。对每个单词进行如上操作,就能得到整个句子的attention输出了。在实际使用过程中,一般采用矩阵计算使整个过程更加高效。

在开始矩阵计算之前,先回顾总结一下上面的步骤:
- 创建Query、Key、Value向量
- 计算每个单词在当前单词的分数
- 将分数归一化后与Value相乘
- 求和
值得注意的是,上面阐述的过程实际上是Attention机制的计算流程,对于self-Attention,Query=Key=Value。
Matrix Calculation of Self-Attention
其实矩阵计算就是将上面的向量放在一起,同时参与计算。
首先,将embedding向量pack成一个矩阵X。假设我们有一句话有长度为10,embedding维度为4,那么X的维度为(10 × 4).

假设我们设定Q、K、V的维度为3.第二步我们构造一个维度为(4×3)的权值矩阵。将其与X做矩阵乘法,得到一个10×3的矩阵,这就能得到Query了。依样画葫芦,同样可以得到Key和Value。

最后,将Query和Key相乘,得到打分,然后经过softmax,接着乘上V的到最终的输出。

4、self-attention的计算

4.1、《Self-Attention with Relative Position Representations》
参考:
https://www.cnblogs.com/robert-dlut/p/5952032.html
https://www.cnblogs.com/robert-dlut/p/8638283.html
https://blog.csdn.net/jasonzhoujx/article/details/83386627
https://state-of-art.top/2019/01/06/BERT系列(一)Self-attention/
Self-Attetion的更多相关文章
- Abstract Factory Step by Step --- 抽象工厂
抽象工厂是创建型模式的代表,其他的还有单件(Singleton).生成器(Builder).工厂方法(Factory Method)以及原型(Prototype),模式本身没有好坏之分,只有适用不适用 ...
- JStorm之Nimbus简介
本文导读: ——JStorm之Nimbus简介 .简介 .系统框架与原理 .实现逻辑和代码剖析 )Nimbus启动 )Topology提交 )任务调度 )任务监控 .结束语 .参考文献 附:JStor ...
- django.test.client 使用随记
import os,sys,django; sys.path.append("\\path\\to\\mysite")#ATTETION!,Err: "unable to ...
- RNN: Feed Forward, Back Propagation Through Time and Truncated Backpropagation Through Time
原创作品,转载请注明出处哦~ 了解RNN的前向.后向传播算法的推导原理是非常重要的,这样, 1. 才会选择正确的激活函数: 2. 才会选择合适的前向传播的timesteps数和后向传播的timeste ...
- Transformer各层网络结构详解!面试必备!(附代码实现)
1. 什么是Transformer <Attention Is All You Need>是一篇Google提出的将Attention思想发挥到极致的论文.这篇论文中提出一个全新的模型,叫 ...
- BERT解析及文本分类应用
目录 前言 BERT模型概览 Seq2Seq Attention Transformer encoder部分 Decoder部分 BERT Embedding 预训练 文本分类试验 参考文献 前言 在 ...
- Transform详解(超详细) Attention is all you need论文
一.背景 自从Attention机制在提出 之后,加入Attention的Seq2 Seq模型在各个任务上都有了提升,所以现在的seq2seq模型指的都是结合rnn和attention的模型.传统的基 ...
- poj3728 The merchant[倍增]
给一棵点带权树,$q$次询问,问树上$x$到$y$路径上,两点权之差(后面的减去前面的)的最大值. 这个是在树链上找点,如果沿路径的最小值在最大值之前出现那肯定答案就是$maxx-minx$,但是反之 ...
- Task10.Bert
Transformer原理 论文地址:Attention Is All You Need:https://arxiv.org/abs/1706.03762 Transformer是一种完全基于Atte ...
- 【转载】Abstract Factory Step by Step --- 抽象工厂
抽象工厂是创建型模式的代表,其他的还有单件(Singleton).生成器(Builder).工厂方法(Factory Method)以及原型(Prototype),模式本身没有好坏之分,只有适用不适用 ...
随机推荐
- duilib-Ex-Debug
因为一些事件google无法訪问,托管在其上的项目也无法检出也基本无人更新,因此维护了一个版本号,用于排除已有的bug和扩展一些功能.这样能够避免反复造轮子和反复的修车子.欢迎大家一起维护.本人能力和 ...
- 深圳MPD大会 讲师演讲稿 2014-10
深圳MPD大会 讲师演讲稿 2014-10 互联网下的蛋-姜志辉.pdf: http://www.t00y.com/file/76704370 俞炜-互联网研发整形术 终于版.pdf: htt ...
- js 里面的 function 与 Function
function 是 js 的标识符 Function 是 js 里面的一个 构造函数 1.new function 与 new Function 的区别 new 运算符在 js 里面是 创建一个自定 ...
- CAGradientLayer功能
一.CAGradientLayer介绍 .CAGradientLayer是用于处理渐变色的层结构 .CAGradientLayer的渐变色能够做隐式动画 .大部分情况下.CAGradientLayer ...
- 对数据html文本 的处理
对数据html文本 的处理 : 提取文字.图片.分句 ''' SELECT * FROM Info_Roles WHERE Flag=1 LIMIT 2; select top y * from 表 ...
- java 多线程——同步 学习笔记
一.实例的同步方法 public synchronized void add(int value){ this.count += value; } Java 实例方法同步是同步在拥有该方法的对象上 ...
- Codeforces--14D--Two Paths(树的直径)
Two Paths Time Limit: 2000MS Memory Limit: 65536KB 64bit IO Format: %I64d & %I64u Submit ...
- 2018.2.24Test总结
T1(luogu3434) comment:水题,考试时我想的是开一个数组在读入时预处理出该长度什么时候会被拦住,但这样数组开不下,剩下只能模拟. 实际上应该把圆筒变成递减序列,再二分该长度即可. T ...
- opensStack
- 【Hibernate总结系列】使用举例
本节讲述如何使用Hibernate实现记录的增.删.改和查功能. 1 查询 在Hibernate中使用查询时,一般使用Hql查询语句. HQL(Hibernate Query Language),即H ...