分析Android-Universal-Image-Loader的缓存处理机制
最近看了UIL中的缓存实现,才发现其实这个东西不难,没有太多的进程调度,没有各种内存读取控制机制、没有各种异常处理。反正UIL中不单代码写的简单,连处理都简单。但是这个类库这么好用,又有这么多人用,那么非常有必要看看他是怎么实现的。先了解UIL中缓存流程的原理图。
原理示意图
主体有三个,分别是UI,缓存模块和数据源(网络)。它们之间的关系如下:
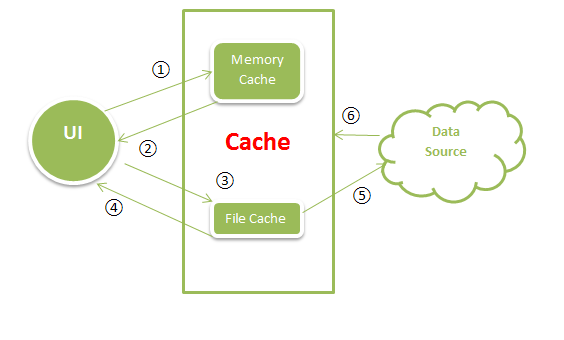
① UI:请求数据,使用唯一的Key值索引Memory Cache中的Bitmap。
② 内存缓存:缓存搜索,如果能找到Key值对应的Bitmap,则返回数据。否则执行第三步。
③ 硬盘存储:使用唯一Key值对应的文件名,检索SDCard上的文件。
④ 如果有对应文件,使用BitmapFactory.decode*方法,解码Bitmap并返回数据,同时将数据写入缓存。如果没有对应文件,执行第五步。
⑤ 下载图片:启动异步线程,从数据源下载数据(Web)。
⑥ 若下载成功,将数据同时写入硬盘和缓存,并将Bitmap显示在UI中。
接下来,我们回顾一下UIL中缓存的配置(具体的见《UNIVERSAL IMAGE LOADER.PART 2》)。重点关注注释部分,我们可以根据自己需要配置内存、磁盘缓存的实现。
File cacheDir = StorageUtils.getCacheDirectory(context, "UniversalImageLoader/Cache"); ImageLoaderConfiguration config = new ImageLoaderConfiguration .Builder(getApplicationContext()) .maxImageWidthForMemoryCache(800) .maxImageHeightForMemoryCache(480) .httpConnectTimeout(5000) .httpReadTimeout(20000) .threadPoolSize(5) .threadPriority(Thread.MIN_PRIORITY + 3) .denyCacheImageMultipleSizesInMemory() .memoryCache(new UsingFreqLimitedCache(2000000)) // 你可以传入自己的内存缓存 .discCache(new UnlimitedDiscCache(cacheDir)) // 你可以传入自己的磁盘缓存 .defaultDisplayImageOptions(DisplayImageOptions.createSimple()) .build();
UIL中的内存缓存策略
1. 只使用的是强引用缓存
- LruMemoryCache(这个类就是这个开源框架默认的内存缓存类,缓存的是bitmap的强引用,下面我会从源码上面分析这个类)
2.使用强引用和弱引用相结合的缓存有
UsingFreqLimitedMemoryCache(如果缓存的图片总量超过限定值,先删除使用频率最小的bitmap)
- LRULimitedMemoryCache(这个也是使用的lru算法,和LruMemoryCache不同的是,他缓存的是bitmap的弱引用)
- FIFOLimitedMemoryCache(先进先出的缓存策略,当超过设定值,先删除最先加入缓存的bitmap)
- LargestLimitedMemoryCache(当超过缓存限定值,先删除最大的bitmap对象)
- LimitedAgeMemoryCache(当 bitmap加入缓存中的时间超过我们设定的值,将其删除)
3.只使用弱引用缓存
WeakMemoryCache(这个类缓存bitmap的总大小没有限制,唯一不足的地方就是不稳定,缓存的图片容易被回收掉)
我们直接选择UIL中的默认配置缓存策略进行分析。
ImageLoaderConfiguration config = ImageLoaderConfiguration.createDefault(context);
ImageLoaderConfiguration.createDefault(…)这个方法最后是调用Builder.build()方法创建默认的配置参数的。默认的内存缓存实现是LruMemoryCache,磁盘缓存是UnlimitedDiscCache。
LruMemoryCache解析
LruMemoryCache:一种使用强引用来保存有数量限制的Bitmap的cache(在空间有限的情况,保留最近使用过的Bitmap)。每次Bitmap被访问时,它就被移动到一个队列的头部。当Bitmap被添加到一个空间已满的cache时,在队列末尾的Bitmap会被挤出去并变成适合被GC回收的状态。
注意:这个cache只使用强引用来保存Bitmap。
LruMemoryCache实现MemoryCache,而MemoryCache继承自MemoryCacheAware。
public interface MemoryCache extends MemoryCacheAware<String, Bitmap>
下面给出继承关系图

LruMemoryCache.get(…)
我相信接下去你看到这段代码的时候会跟我一样惊讶于代码的简单,代码中除了异常判断,就是利用synchronized进行同步控制。
/**
* Returns the Bitmap for {@code key} if it exists in the cache. If a Bitmap was returned, it is moved to the head
* of the queue. This returns null if a Bitmap is not cached.
*/
@Override
public final Bitmap get(String key) {
if (key == null) {
throw new NullPointerException("key == null");
}
synchronized (this) {
return map.get(key);
}
}
我们会好奇,这不是就简简单单将Bitmap从map中取出来吗?但LruMemoryCache声称保留在空间有限的情况下保留最近使用过的Bitmap。不急,让我们细细观察一下map。他是一个LinkedHashMap<String, Bitmap>型的对象。
LinkedHashMap中的get()方法不仅返回所匹配的值,并且在返回前还会将所匹配的key对应的entry调整在列表中的顺序(LinkedHashMap使用双链表来保存数据),让它处于列表的最后。当然,这种情况必须是在LinkedHashMap中accessOrder==true的情况下才生效的,反之就是get()方法不会改变被匹配的key对应的entry在列表中的位置。
@Override public V get(Object key) {
/*
* This method is overridden to eliminate the need for a polymorphic
* invocation in superclass at the expense of code duplication.
*/
if (key == null) {
HashMapEntry<K, V> e = entryForNullKey;
if (e == null)
return null;
if (accessOrder)
makeTail((LinkedEntry<K, V>) e);
return e.value;
}
// Replace with Collections.secondaryHash when the VM is fast enough (http://b/8290590).
int hash = secondaryHash(key);
HashMapEntry<K, V>[] tab = table;
for (HashMapEntry<K, V> e = tab[hash & (tab.length - 1)];
e != null; e = e.next) {
K eKey = e.key;
if (eKey == key || (e.hash == hash && key.equals(eKey))) {
if (accessOrder)
makeTail((LinkedEntry<K, V>) e);
return e.value;
}
}
return null;
}
代码第11行的makeTail()就是调整entry在列表中的位置,其实就是双向链表的调整。它判断accessOrder
。到现在我们就清楚LruMemoryCache使用LinkedHashMap来缓存数据,在LinkedHashMap.get()方法执行后,LinkedHashMap中entry的顺序会得到调整。那么我们怎么保证最近使用的项不会被剔除呢?接下去,让我们看看LruMemoryCache.put(...)。
LruMemoryCache.put(...)
注意到代码第8行中的size+= sizeOf(key, value),这个size是什么呢?我们注意到在第19行有一个trimToSize(maxSize),trimToSize(...)这个函数就是用来限定LruMemoryCache的大小不要超过用户限定的大小,cache的大小由用户在LruMemoryCache刚开始初始化的时候限定。
@Override
public final boolean put(String key, Bitmap value) {
if (key == null || value == null) {
throw new NullPointerException("key == null || value == null");
}
synchronized (this) {
size += sizeOf(key, value);
//map.put()的返回值如果不为空,说明存在跟key对应的entry,put操作只是更新原有key对应的entry
Bitmap previous = map.put(key, value);
if (previous != null) {
size -= sizeOf(key, previous);
}
}
trimToSize(maxSize);
return true;
}
其实不难想到,当Bitmap缓存的大小超过原来设定的maxSize时应该是在trimToSize(...)这个函数中做到的。这个函数做的事情也简单,遍历map,将多余的项(代码中对应toEvict)剔除掉,直到当前cache的大小等于或小于限定的大小。
private void trimToSize(int maxSize) {
while (true) {
String key;
Bitmap value;
synchronized (this) {
if (size < 0 || (map.isEmpty() && size != 0)) {
throw new IllegalStateException(getClass().getName() + ".sizeOf() is reporting inconsistent results!");
}
if (size <= maxSize || map.isEmpty()) {
break;
}
Map.Entry<String, Bitmap> toEvict = map.entrySet().iterator().next();
if (toEvict == null) {
break;
}
key = toEvict.getKey();
value = toEvict.getValue();
map.remove(key);
size -= sizeOf(key, value);
}
}
}
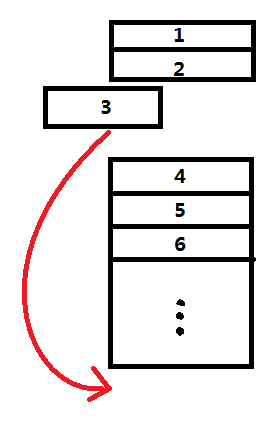
这时候我们会有一个以为,为什么遍历一下就可以将使用最少的bitmap缓存给剔除,不会误删到最近使用的bitmap缓存吗?首先,我们要清楚,LruMemoryCache定义的最近使用是指最近用get或put方式操作到的bitmap缓存。其次,之前我们直到LruMemoryCache的get操作其实是通过其内部字段LinkedHashMap.get(...)实现的,当LinkedHashMap的accessOrder==true时,每一次get或put操作都会将所操作项(图中第3项)移动到链表的尾部(见下图,链表头被认为是最少使用的,链表尾被认为是最常使用的。),每一次操作到的项我们都认为它是最近使用过的,当内存不够的时候被剔除的优先级最低。需要注意的是一开始的LinkedHashMap链表是按插入的顺序构成的,也就是第一个插入的项就在链表头,最后一个插入的就在链表尾。假设只要剔除图中的1,2项就能让LruMemoryCache小于原先限定的大小,那么我们只要从链表头遍历下去(从1→最后一项)那么就可以剔除使用最少的项了。

至此,我们就知道了LruMemoryCache缓存的整个原理,包括他怎么put、get、剔除一个元素的的策略。接下去,我们要开始分析默认的磁盘缓存策略了。
UIL中的磁盘缓存策略
像新浪微博、花瓣这种应用需要加载很多图片,本来图片的加载就慢了,如果下次打开的时候还需要再一次下载上次已经有过的图片,相信用户的流量会让他们的叫骂声很响亮。对于图片很多的应用,一个好的磁盘缓存直接决定了应用在用户手机的留存时间。我们自己实现磁盘缓存,要考虑的太多,幸好UIL提供了几种常见的磁盘缓存策略,当然如果你觉得都不符合你的要求,你也可以自己去扩展
- FileCountLimitedDiscCache(可以设定缓存图片的个数,当超过设定值,删除掉最先加入到硬盘的文件)
- LimitedAgeDiscCache(设定文件存活的最长时间,当超过这个值,就删除该文件)
- TotalSizeLimitedDiscCache(设定缓存bitmap的最大值,当超过这个值,删除最先加入到硬盘的文件)
- UnlimitedDiscCache(这个缓存类没有任何的限制)
在UIL中有着比较完整的存储策略,根据预先指定的空间大小,使用频率(生命周期),文件个数的约束条件,都有着对应的实现策略。最基础的接口DiscCacheAware和抽象类BaseDiscCache
UnlimitedDiscCache解析
UnlimitedDiscCache实现disk cache接口,是ImageLoaderConfiguration中默认的磁盘缓存处理。用它的时候,磁盘缓存的大小是不受限的。
接下来我们来看看实现UnlimitedDiscCache的源代码,通过源代码我们发现他其实就是继承了BaseDiscCache,这个类内部没有实现自己独特的方法,也没有重写什么,那么我们就直接看BaseDiscCache这个类。在分析这个类之前,我们先想想自己实现一个磁盘缓存需要做多少麻烦的事情:
1、图片的命名会不会重。你没有办法知道用户下载的图片原始的文件名是怎么样的,因此很可能因为文件重名将有用的图片给覆盖掉了。
2、当应用卡顿或网络延迟的时候,同一张图片反复被下载。
3、处理图片写入磁盘可能遇到的延迟和同步问题。
BaseDiscCache构造函数
首先,我们看一下BaseDiscCache的构造函数:
cacheDir:文件缓存目录
reserveCacheDir:备用的文件缓存目录,可以为null。它只有当cacheDir不能用的时候才有用。
fileNameGenerator:文件名生成器。为缓存的文件生成文件名。
public BaseDiscCache(File cacheDir, File reserveCacheDir, FileNameGenerator fileNameGenerator) {
if (cacheDir == null) {
throw new IllegalArgumentException("cacheDir" + ERROR_ARG_NULL);
}
if (fileNameGenerator == null) {
throw new IllegalArgumentException("fileNameGenerator" + ERROR_ARG_NULL);
}
this.cacheDir = cacheDir;
this.reserveCacheDir = reserveCacheDir;
this.fileNameGenerator = fileNameGenerator;
}
我们可以看到一个fileNameGenerator,接下来我们来了解UIL具体是怎么生成不重复的文件名的。UIL中有3种文件命名策略,这里我们只对默认的文件名策略进行分析。默认的文件命名策略在DefaultConfigurationFactory.createFileNameGenerator()。它是一个HashCodeFileNameGenerator。真的是你意想不到的简单,就是运用String.hashCode()进行文件名的生成。
public class HashCodeFileNameGenerator implements FileNameGenerator {
@Override
public String generate(String imageUri) {
return String.valueOf(imageUri.hashCode());
}
}
BaseDiscCache.save()
分析完了命名策略,再看一下BaseDiscCache.save(...)方法。注意到第2行有一个getFile()函数,它主要用于生成一个指向缓存目录中的文件,在这个函数里面调用了刚刚介绍过的fileNameGenerator来生成文件名。注意第3行的tmpFile,它是用来写入bitmap的临时文件(见第8行),然后就把这个文件给删除了。大家可能会困惑,为什么在save()函数里面没有判断要写入的bitmap文件是否存在的判断,我们不由得要看看UIL中是否有对它进行判断。还记得我们在《从代码分析Android-Universal-Image-Loader的图片加载、显示流程》介绍的,UIL加载图片的一般流程是先判断内存中是否有对应的Bitmap,再判断磁盘(disk)中是否有,如果没有就从网络中加载。最后根据原先在UIL中的配置判断是否需要缓存Bitmap到内存或磁盘中。也就是说,当需要调用BaseDiscCache.save(...)之前,其实已经判断过这个文件不在磁盘中。
public boolean save(String imageUri, InputStream imageStream, IoUtils.CopyListener listener) throws IOException {
File imageFile = getFile(imageUri);
File tmpFile = new File(imageFile.getAbsolutePath() + TEMP_IMAGE_POSTFIX);
boolean loaded = false;
try {
OutputStream os = new BufferedOutputStream(new FileOutputStream(tmpFile), bufferSize);
try {
loaded = IoUtils.copyStream(imageStream, os, listener, bufferSize);
} finally {
IoUtils.closeSilently(os);
}
} finally {
IoUtils.closeSilently(imageStream);
if (loaded && !tmpFile.renameTo(imageFile)) {
loaded = false;
}
if (!loaded) {
tmpFile.delete();
}
}
return loaded;
}
BaseDiscCache.get()
BaseDiscCache.get()方法内部调用了BaseDiscCache.getFile(...)方法,让我们来分析一下这个在之前碰过的函数。 第2行就是利用fileNameGenerator生成一个唯一的文件名。第3~8行是指定缓存目录,这时候你就可以清楚地看到cacheDir和reserveCacheDir之间的关系了,当cacheDir不可用的时候,就是用reserveCachedir作为缓存目录了。
最后返回一个指向文件的对象,但是要注意当File类型的对象指向的文件不存在时,file会为null,而不是报错。
protected File getFile(String imageUri) {
String fileName = fileNameGenerator.generate(imageUri);
File dir = cacheDir;
if (!cacheDir.exists() && !cacheDir.mkdirs()) {
if (reserveCacheDir != null && (reserveCacheDir.exists() || reserveCacheDir.mkdirs())) {
dir = reserveCacheDir;
}
}
return new File(dir, fileName);
}
总结
现在,我们已经分析了UIL的缓存机制。其实从UIL的缓存机制的实现并不是很复杂,虽然有各种缓存机制,但是简单地说:内存缓存其实就是利用Map接口的对象在内存中进行缓存,可能有不同的存储机制。磁盘缓存其实就是将文件写入磁盘。
分析Android-Universal-Image-Loader的缓存处理机制的更多相关文章
- android universal image loader 缓冲原理详解
1. 功能介绍 1.1 Android Universal Image Loader Android Universal Image Loader 是一个强大的.可高度定制的图片缓存,本文简称为UIL ...
- Android Universal Image Loader java.io.FileNotFoundException: http:/xxx/lxx/xxxx.jpg
前段时间在使用ImageLoader异步加载服务端返回的图片时总是出现 java.io.FileNotFoundException: http://xxxx/l046/10046137034b1c0d ...
- Android中Universal Image Loader开源框架的简单使用
UIL (Universal Image Loader)aims to provide a powerful, flexible and highly customizable instrument ...
- 【Android应用开发】 Universal Image Loader ( 使用简介 | 示例代码解析 )
作者 : 韩曙亮 转载请注明出处 : http://blog.csdn.net/shulianghan/article/details/50824912 相关地址介绍 : -- Universal I ...
- 开源项目Universal Image Loader for Android 说明文档 (1) 简介
When developing applications for Android, one often facesthe problem of displaying some graphical ...
- 开源项目Universal Image Loader for Android 说明文档 (1) 简单介绍
When developing applications for Android, one often facesthe problem of displaying some graphical ...
- 从源代码分析Android-Universal-Image-Loader的缓存处理机制
讲到缓存,平时流水线上的码农一定觉得这是一个高大上的东西.看过网上各种讲缓存原理的文章,总感觉那些文章讲的就是玩具,能用吗?这次我将带你一起看过UIL这个国内外大牛都追捧的图片缓存类库的缓存处理机制. ...
- universal image loader在listview/gridview中滚动时重复加载图片的问题及解决方法
在listview/gridview中使用UIL来display每个item的图片,当图片数量较多需要滑动滚动时会出现卡顿,而且加载过的图片再次上翻后依然会重复加载(显示设置好的加载中图片) 最近在使 ...
- universal image loader自己使用的一些感受
1.全局入口的Application定义初始化: ImageLoaderConfiguration configuration = new ImageLoaderConfiguration.Build ...
随机推荐
- Docker入门之常用命令
写在前面 细数当前最流行的技术莫过于容器化和人工智能了,而容器化技术能有今天的热度,Docker可谓功不可没. 让我们一起来回顾一下Docker 是什么? 是一种虚拟化技术 能够将应用程序自动部署到容 ...
- 【Thinkphp 5】auth权限设置以及实现
1.将auth类下载好 放置目录: extend\auth\auth.php 2.将类中的SQL语句执行,可以在数据库中创建3张表 auth_group(用户组表) auth_ru ...
- VUE 框架
一.什么是vue 它是一个构建用户界面的JAVASCRITPO框架 二.怎么使用VUE (1).引入vue.js 如:<script src='vue.js'>&l ...
- Docker+Jenkins持续集成环境(5): android构建与apk发布
项目组除了常规的java项目,还有不少android项目,如何使用jenkins来实现自动构建呢?本文会介绍安卓项目通过jenkins构建的方法,并设计开发一个类似蒲公英的app托管平台. andro ...
- easyUI前后台分页代码实现
一.后台分页 (1)客户端代码: var dg = $('#table'); var opts = dg.datagrid('options'); var pager = dg.datagrid('g ...
- cookie和session的那些事
对于经常网购的朋友来说,经常会遇到一种情况: 打开淘宝或京东商城的首页,输入个人账号和密码进行登陆,然后进行购物,支付等操作都不需要用户再次输入用户名和密码 但是如果用户换一个浏览器或者等几个小时后再 ...
- mysql插入数据时检查是否某字段已存在
SELECT\n" + " '',\n" + " '{0}',\n" + " '{1}',\n" + " '{2}'\n ...
- 安装pcntl以实现php多进程
pcntl 扩展包一般就在php源码的ext目录下. cd ./ext/pcntl /opt/server/php5/bin/phpize ./configure \ --with-php-confi ...
- manacher 模板
求最长回文子序列的 O(n)做法 讲解 #include <iostream> #include <cstdio> #include <algorithm> #in ...
- H5弹性盒布局的使用(父容器属性)
为父容器添加display:flex/inline-flex 父容器可以使用的属性有: 1.flex-direction:决定主轴的方向 有四个属性值: row(默认值):主轴为水平方向,起点在左端. ...