[Mysql]——通过例子理解事务的4种隔离级别(转)
SQL标准定义了4种隔离级别,包括了一些具体规则,用来限定事务内外的哪些改变是可见的,哪些是不可见的。
低级别的隔离级一般支持更高的并发处理,并拥有更低的系统开销。
一、事务隔离级别分类
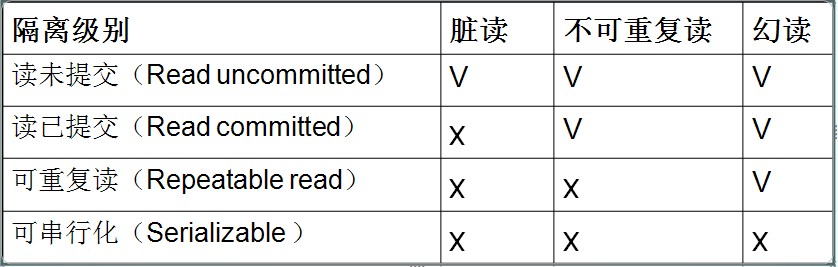
- 第1级别:Read Uncommitted(读取未提交内容)
- 第2级别:Read Committed(读取提交内容)
- 第3级别:Repeatable Read(可重读)
- 第4级别:Serializable(可串行化)
二、测试
首先,我们使用 test 数据库,新建 tx 表,并且如图所示打开两个窗口来操作同一个数据库:

第1级别:Read Uncommitted(读取未提交内容)
(1)所有事务都可以看到其他未提交事务的执行结果
(2)本隔离级别很少用于实际应用,因为它的性能也不比其他级别好多少
(3)该级别引发的问题是——脏读(Dirty Read):读取到了未提交的数据
#首先,修改隔离级别
set tx_isolation='READ-UNCOMMITTED';
select @@tx_isolation;
+------------------+
| @@tx_isolation |
+------------------+
| READ-UNCOMMITTED |
+------------------+ #事务A:启动一个事务
start transaction;
select * from tx;
+------+------+
| id | num |
+------+------+
| 1 | 1 |
| 2 | 2 |
| 3 | 3 |
+------+------+ #事务B:也启动一个事务(那么两个事务交叉了)
在事务B中执行更新语句,且不提交
start transaction;
update tx set num=10 where id=1;
select * from tx;
+------+------+
| id | num |
+------+------+
| 1 | 10 |
| 2 | 2 |
| 3 | 3 |
+------+------+ #事务A:那么这时候事务A能看到这个更新了的数据吗?
select * from tx;
+------+------+
| id | num |
+------+------+
| 1 | 10 | --->可以看到!说明我们读到了事务B还没有提交的数据
| 2 | 2 |
| 3 | 3 |
+------+------+ #事务B:事务B回滚,仍然未提交
rollback;
select * from tx;
+------+------+
| id | num |
+------+------+
| 1 | 1 |
| 2 | 2 |
| 3 | 3 |
+------+------+ #事务A:在事务A里面看到的也是B没有提交的数据
select * from tx;
+------+------+
| id | num |
+------+------+
| 1 | 1 | --->脏读意味着我在这个事务中(A中),事务B虽然没有提交,但它任何一条数据变化,我都可以看到!
| 2 | 2 |
| 3 | 3 |
+------+------+
第2级别:Read Committed(读取提交内容)
(1)这是大多数数据库系统的默认隔离级别(但不是MySQL默认的)
(2)它满足了隔离的简单定义:一个事务只能看见已经提交事务所做的改变
(3)这种隔离级别出现的问题是——不可重复读(Nonrepeatable Read):不可重复读意味着我们在同一个事务中执行完全相同的select语句时可能看到不一样的结果。
|——>导致这种情况的原因可能有:
(a)有一个交叉的事务有新的commit,导致了数据的改变;
(b)一个数据库被多个实例操作时,同一事务的其他实例在该实例处理其间可能会有新的commit
#首先修改隔离级别
set tx_isolation='read-committed';
select @@tx_isolation;
+----------------+
| @@tx_isolation |
+----------------+
| READ-COMMITTED |
+----------------+ #事务A:启动一个事务
start transaction;
select * from tx;
+------+------+
| id | num |
+------+------+
| 1 | 1 |
| 2 | 2 |
| 3 | 3 |
+------+------+ #事务B:也启动一个事务(那么两个事务交叉了)
在这事务中更新数据,且未提交
start transaction;
update tx set num=10 where id=1;
select * from tx;
+------+------+
| id | num |
+------+------+
| 1 | 10 |
| 2 | 2 |
| 3 | 3 |
+------+------+ #事务A:这个时候我们在事务A中能看到数据的变化吗?
select * from tx; --------------->
+------+------+ |
| id | num | |
+------+------+ |
| 1 | 1 |--->并不能看到! |
| 2 | 2 | |
| 3 | 3 | |
+------+------+ |——>相同的select语句,结果却不一样
|
#事务B:如果提交了事务B呢? |
commit; |
|
#事务A: |
select * from tx; --------------->
+------+------+
| id | num |
+------+------+
| 1 | 10 |--->因为事务B已经提交了,所以在A中我们看到了数据变化
| 2 | 2 |
| 3 | 3 |
+------+------+
第3级别:Repeatable Read(可重读)
(1)这是MySQL的默认事务隔离级别
(2)它确保同一事务的多个实例在并发读取数据时,会看到同样的数据行
(3)此级别可能出现的问题——幻读(Phantom Read):当用户读取某一范围的数据行时,另一个事务又在该范围内插入了新行,当用户再读取该范围的数据行时,会发现有新的“幻影” 行
(4)InnoDB和Falcon存储引擎通过多版本并发控制(MVCC,Multiversion Concurrency Control)机制解决了该问题
#首先,更改隔离级别
set tx_isolation='repeatable-read';
select @@tx_isolation;
+-----------------+
| @@tx_isolation |
+-----------------+
| REPEATABLE-READ |
+-----------------+ #事务A:启动一个事务
start transaction;
select * from tx;
+------+------+
| id | num |
+------+------+
| 1 | 1 |
| 2 | 2 |
| 3 | 3 |
+------+------+ #事务B:开启一个新事务(那么这两个事务交叉了)
在事务B中更新数据,并提交
start transaction;
update tx set num=10 where id=1;
select * from tx;
+------+------+
| id | num |
+------+------+
| 1 | 10 |
| 2 | 2 |
| 3 | 3 |
+------+------+
commit; #事务A:这时候即使事务B已经提交了,但A能不能看到数据变化?
select * from tx;
+------+------+
| id | num |
+------+------+
| 1 | 1 | --->还是看不到的!(这个级别2不一样,也说明级别3解决了不可重复读问题)
| 2 | 2 |
| 3 | 3 |
+------+------+ #事务A:只有当事务A也提交了,它才能够看到数据变化
commit;
select * from tx;
+------+------+
| id | num |
+------+------+
| 1 | 10 |
| 2 | 2 |
| 3 | 3 |
+------+------+
第4级别:Serializable(可串行化)
(1)这是最高的隔离级别
(2)它通过强制事务排序,使之不可能相互冲突,从而解决幻读问题。简言之,它是在每个读的数据行上加上共享锁。
(3)在这个级别,可能导致大量的超时现象和锁竞争
#首先修改隔离界别
set tx_isolation='serializable';
select @@tx_isolation;
+----------------+
| @@tx_isolation |
+----------------+
| SERIALIZABLE |
+----------------+ #事务A:开启一个新事务
start transaction; #事务B:在A没有commit之前,这个交叉事务是不能更改数据的
start transaction;
insert tx values('','');
ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction
update tx set num=10 where id=1;
ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction
原文地址:https://www.cnblogs.com/snsdzjlz320/p/5761387.html#_label04
[Mysql]——通过例子理解事务的4种隔离级别(转)的更多相关文章
- [Mysql]——通过例子理解事务的4种隔离级别
SQL标准定义了4种隔离级别,包括了一些具体规则,用来限定事务内外的哪些改变是可见的,哪些是不可见的. 低级别的隔离级一般支持更高的并发处理,并拥有更低的系统开销. 首先,我们使用 test 数据库, ...
- [Mysql]——通过例子理解事务的4种隔离级别(转)
第1级别:Read Uncommitted(读取未提交内容) 第2级别:Read Committed(读取提交内容) 第3级别:Repeatable Read(可重读) 第4级别:Serializab ...
- Mysql加锁过程详解(6)-数据库隔离级别(2)-通过例子理解事务的4种隔离级别
Mysql加锁过程详解(1)-基本知识 Mysql加锁过程详解(2)-关于mysql 幻读理解 Mysql加锁过程详解(3)-关于mysql 幻读理解 Mysql加锁过程详解(4)-select fo ...
- SQL事务的四种隔离级别和MySQL多版本并发控制
SQL标准定义了4类隔离级别,包括了一些具体规则,用来限定事务内外的那些改变时可见的,那些是不可见的.低级别的隔离级一般支持更高的并发处理,并拥有更低的系统开销. ReadUncommitted( ...
- sql 事务的四种隔离级别
在 SQL 标准中定义了四种隔离级别,每一种级别都规定了一个事务中所做的修改,哪些在事务内和事务间是可见的,哪些是不可见的.较低级别的隔离通常可以执行更高的并发,系统的开销也更低. read unco ...
- SQL Server事务的四种隔离级别
在SQL标准中定义了四种隔离级别,每一种级别都规定了一个事务中所做的修改,哪些是在事务内和事务间可见的,哪些是不可见的.较低级别的隔离通常可以执行更高的并发,系统的开销也更低. 1.未提交读(Read ...
- MySQL事务的四种隔离级别
事务的基本要素: 原子性(atomicity):事务开始后的全部操作, 要么全部执行成功,如果中间出现错误,事务回滚到事务开始前的状态. 一致性(Consistency):事务开始后,数据库的完整性约 ...
- Spring事务的5种隔离级别和7种传播性
隔离级别 isolation,5 种: ISOLATION_DEFAULT,ISOLATION_READ_UNCOMMITTED,ISOLATION_READ_COMMITTED,ISOLATION_ ...
- Spring事务的5种隔离级别
概述:isolation设定事务的隔离级别,事务管理器根据它来控制另外一个事务可以看到本事务内的哪些数据. 定义的5个不同的事务隔离级别: DEFAULT:默认的隔离级别,使用数据库默认的事务隔离级别 ...
随机推荐
- /dev/null 2>&1的意思(可以直接参考shell重定向那篇,/dev/null是空设备)
路还长 别太狂 以后指不定谁辉煌 2>&1 和 &> 的解释 Linux的IO输入输出有三类 Standard Input 代码 0 Standard Output 代码 ...
- 用shell脚本挂载linux主机拷贝相应文件copy.sh
#!/bin/sh # $1 MOUNTDIR $2 TARGETDIR $3 ERRORLOG #参数检查 if test $# -ne 3 then echo "argument che ...
- Docker学习笔记【四】Docker 仓库
访问仓库,仓库是集中从存放镜像的地方.类似Maven. Docker Hub 目前由Docker官方维护的一个公共仓库,其中包括15000的镜像. 注册 在 https://hub.docker.co ...
- ssh三大框架集成后,jsp中采用forword标签提交时会报错的解决方案
最近这两天心烦,所以没事就做做三大框架,对于今天遇到了一个烦心的事!或许有很多开发人员对于web.xml拦截器的认识不清,出现了这样的情况 <filter> <filter-name ...
- MySQL Join 的实现原理
在寻找Join 语句的优化思路之前,我们首先要理解在MySQL 中是如何来实现Join 的,只要理解了实现原理之后,优化就比较简单了.下面我们先分析一下MySQL 中Join 的实现原理.在MySQL ...
- nslookup查询结果详解
nslookup可以指定查询的类型,可以查到DNS记录的生存时间还可以指定使用那个DNS服务器进行解释.在已安装TCP/IP协议的电脑上面均可以使用这个命令.主要用来诊断域名系统 (DNS) 基础结构 ...
- parted分区详解 查看UUID两种方式 blkid 和 ls -l /dev/disk/by-uuid
通常我们用的比较多的一般都是fdisk工具来进行分区,但是现在由于磁盘越来越廉价,而且磁盘空间越来越大:而fdisk工具他对分区是有大小限制的,它只能划分小于2T的磁盘.但是现在的磁盘空间很多都已经是 ...
- PyCharm中HTML页面CSS class名称自动完成功能失效的问题
如果这个HTML页面带有style元素的CSS定义,那class name自动完成功能就失效了 Pycharm Version:5.03
- AQS分析(AbstractQueuedSynchronizer)(三)
1.AQS是什么 AQS同步器是Java并发编程的基础,从资源共享的角度分成独占和共享两种模式,像ReentrantLock.ThreadPoolExecutor.CountDownLatch等都是基 ...
- 服务器禁止ping
禁止ping后,不让别人通过域名ping到你的ip, 如果禁用后,你在ping自己的域名会给你返回服务商的IP并提示超时, 这样你就可以减少IP暴露,增加一点安全. 禁止方法: 编辑 /etc/sys ...