第三篇:爬虫框架 - Scrapy
前言
Python提供了一个比较实用的爬虫框架 - Scrapy。在这个框架下只要定制好指定的几个模块,就能实现一个爬虫。
本文将讲解Scrapy框架的基本体系结构,以及使用这个框架定制爬虫的具体步骤。
Scrapy体系结构
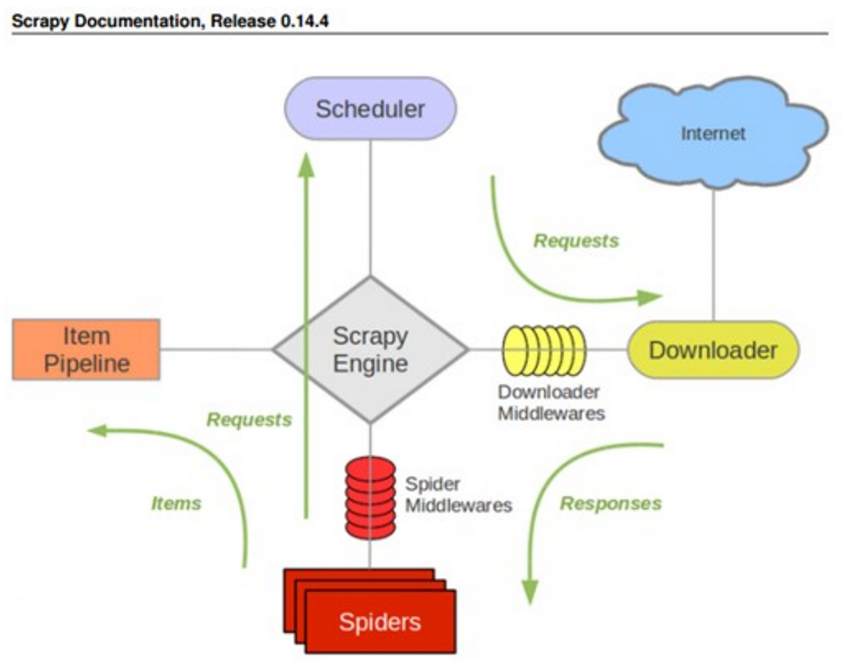
其具体执行流程如下:
1. 任务管理器Scheduler将初始下载任务递交给下载器Downloader;
2. 下载器Downloader将下载好了的页面传递给爬取分析器Spiders进行分析。
爬取分析器分析的结果分为两种:
a) 本次爬取所得数据 -> 它将传递给任务管理器Scheduler;
b) 需要进行下一级爬取的URL地址 -> 它将传递给数据管道进行相关的保存工作。
基于Scrapy框架的豆瓣网电影信息爬取器
1. 执行以下命令创建一个新的工程:
scrapy startproject doubanMovieSpider
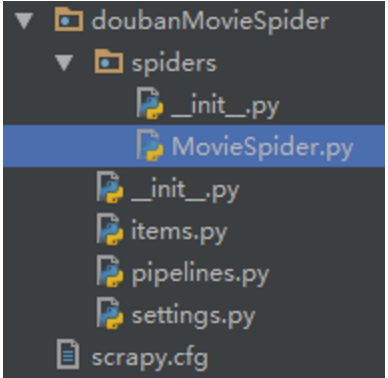
doubanMovieSpider是工程名,工程包里将会有如下这些文件:
1) scrapy.cfg: 项目配置文件
2) items.py: 需要提取的数据结构定义文件
3) pipelines.py:管道定义,用来对items里面提取的数据做进一步处理,如保存等
4) settings.py: 爬虫配置文件
5) spiders: 放置spider的目录
该工程用于从豆瓣网爬取电影信息(如电影名,评分等等)。
2. 定义爬取结果数据结构Item --- 在items.py中编写如下代码:
# -*- coding: utf-8 -*-
# ================================================
# 作者: 方萌
# 创建时间: 20**/**/**
# 版本号: 1.0
# 联系方式: 1505033833@qq.com
# ================================================
# scrapy框架模块
import scrapy
class DoubanmoviespiderItem(scrapy.Item):
# 主题
title = scrapy.Field()
# 评分
rate = scrapy.Field()
# ID
id = scrapy.Field()
Item其实从本质来说,就是Scrapy框架自己实现的字典,需要继承scrapy.Item类。上述代码定义的字典表示要爬取的电影信息有:电影主题,电影评分,以及电影ID。
3. 实现爬取分析器Spider --- 在spiders目录下增加一个python文件MovieSpider.py:
在这个文件中自定义一个爬取分析器,该分析器为一个继承自scrapy.spider.BaseSpider(或者Scrapy框架下其他抽象爬取器)的类,它起码要实现以下几个字段:
1) name:spider的标识
2) start_urls:起始爬取URL
3) parse():爬取对象解析函数
实现代码如下:
# -*- coding: utf-8 -*-
# ================================================
# 作者: 方萌
# 创建时间: 20**/**/**
# 版本号: 1.0
# 联系方式: 1505033833@qq.com
# ================================================
# scrapy框架模块
import scrapy
# json解析模块
import json
# 系统模块
import sys
# items模块
import doubanMovieSpider.items
# 爬虫类
class MovieSpider(scrapy.spider.BaseSpider):
# 爬虫名
name = "douban"
# 域名限定
allowed_domains = ["www.douban.com"]
# 爬取URL队列
start_urls = [
"http://movie.douban.com/j/serch_subjects?type=movie&tag=%E7%83%AD%E9%97%A8&sort=recommend&page_limit=200&page_start=0"
]
def parse(self, response):
"""
函数功能:
解析爬取到的数据
输入:
response -> 爬取返回数据对象
输出:
空
"""
# 将爬取到的电影信息存入json容器
json_container = json.loads(response.body)
# 构建items。该模块具体含义请查询相关文档。
items = []
for movie_elem in json_container['subjects']:
item = doubanMovieSpider.items.DoubanmoviespiderItem()
for key in movie_elem:
if key == 'title':
item['title'] = movie_elem[key]
print movie_elem[key]
if key == 'rate':
item['rate'] = movie_elem[key]
if key == 'id':
item['id'] = movie_elem[key]
items.append(item)
# 返回items
return items
4. 实现PipeLine --- 修改items.py文件:
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html
class DoubanmoviespiderPipeline(object):
def __init__(self):
pass
def process_item(self, item, spider):
pass
PipeLine用来对Spider返回的Item列表进行保存操作,可以写入到文件、或者数据库等。
我们可以在其中的__init__方法内编写打开文件部分代码,在process_item方法内编写具体的写入函数(可直接将数据写入进远程数据库);也可以不实现这个模块,scrapy会有其默认的写入机制(本系统采用默认写入机制)
5. 在项目当前目录下执行如下命令即可启动此爬虫系统:
scrapy crawl douban -o items.json -t json
该命令表示启动爬取分析器“douban”,并将爬取到的items以json格式保存到items.json文件中。“douban” 即是在爬取分析器中由name域指定的。
下图为爬取到的结果:
小结
本文仅仅给出Scrapy框架的基本使用。如果要实现生产级别的项目,还需对该框架内的一些具体设置,各种抽象爬取分析器进行深入研究。
第三篇:爬虫框架 - Scrapy的更多相关文章
- 洗礼灵魂,修炼python(72)--爬虫篇—爬虫框架:Scrapy
题外话: 前面学了那么多,相信你已经对python很了解了,对爬虫也很有见解了,然后本来的计划是这样的:(请忽略编号和日期,这个是不定数,我在更博会随时改的) 上面截图的是我的草稿 然后当我开始写博文 ...
- Python爬虫框架Scrapy实例(三)数据存储到MongoDB
Python爬虫框架Scrapy实例(三)数据存储到MongoDB任务目标:爬取豆瓣电影top250,将数据存储到MongoDB中. items.py文件复制代码# -*- coding: utf-8 ...
- 小白学 Python 爬虫(35):爬虫框架 Scrapy 入门基础(三) Selector 选择器
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- Python爬虫框架Scrapy教程(1)—入门
最近实验室的项目中有一个需求是这样的,需要爬取若干个(数目不小)网站发布的文章元数据(标题.时间.正文等).问题是这些网站都很老旧和小众,当然也不可能遵守 Microdata 这类标准.这时候所有网页 ...
- 小白学 Python 爬虫(34):爬虫框架 Scrapy 入门基础(二)
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(36):爬虫框架 Scrapy 入门基础(四) Downloader Middleware
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(40):爬虫框架 Scrapy 入门基础(七)对接 Selenium 实战
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(41):爬虫框架 Scrapy 入门基础(八)对接 Splash 实战
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 爬虫框架Scrapy
前面十章爬虫笔记陆陆续续记录了一些简单的Python爬虫知识, 用来解决简单的贴吧下载,绩点运算自然不在话下. 不过要想批量下载大量的内容,比如知乎的所有的问答,那便显得游刃不有余了点. 于是乎,爬虫 ...
随机推荐
- VS2012以后版本MFC程序发布记录,支持XP
##概述 自从VS2012之后,增加了新的VC运行时库,而一般用户机器上不一定有对应的版本的运行时库,所以微软官方给出的方案是需要用户安装对应版本的VisualC++Redistributable P ...
- JavaScript正则表达式函数总结
/* 测试环境:Chrome 63.0.3239.132 */ JS中正则对象修饰符可选值为:"i" "g" "m",即忽略大小写 进行全局 ...
- R语言-主成分分析
1.PCA 使用场景:主成分分析是一种数据降维,可以将大量的相关变量转换成一组很少的不相关的变量,这些无关变量称为主成分 步骤: 数据预处理(保证数据中没有缺失值) 选择因子模型(判断是PCA还是EF ...
- wangeditor Demo
<html> <head> <!--在这里字符集的设定很重要,如果设定不当将会出现乱码--> <meta charset="UTF-8"& ...
- linux下双网卡的绑定
如果服务器上有两快网卡就可以把它绑定为一块虚拟的网卡,如果一块网卡坏了另一块还可以继续工作,增加了冗余度和负载,具体做法如下: 新建一个虚拟的网卡,命令如下: iv /etc/sysconfig/ne ...
- MyEclipse出现红色感叹号解决办法
今天在做数据库连接练习的时候自己创建的工程突然出现了一个红色的感叹号,然后运行自己写的代码的时候出现找不到主类的错误!!! 我还以为是自己不小心写错了,然后让编译器自动生成代码也出现了一样的问题... ...
- 工作笔记--自动切换host的python code
修改host代码: #coding:utf-8import os,timepwd = os.path.dirname(__file__) #获取当前文件夹的绝对路径pull_host_cmd = 'a ...
- Mysql内置的profiling性能分析工具
要想优化一条 Query,我们就需要清楚的知道这条 Query 的性能瓶颈到底在哪里,是消耗的 CPU计算太多,还是需要的的 IO 操作太多?要想能够清楚的了解这些信息,在 MySQL 5.0 和 M ...
- poj 3278 简单BFS
题意:给定农夫和奶牛的初始位置,农夫可以当前位置+1.-1.*2三种移动方式,问最少需要多少分钟抓住奶牛 AC代码: #include<cstdio> #include<cstrin ...
- 编写React组件的最佳实践
此文翻译自这里. 当我刚开始写React的时候,我看过很多写组件的方法.一百篇教程就有一百种写法.虽然React本身已经成熟了,但是如何使用它似乎还没有一个"正确"的方法.所以我( ...