ansj人名识别
1、前言
1.1、asian_name_freq.data
1.2、person.dic
1.3、何时触发人名识别
public void setlocFreq(int[][] ints) {
for (int i = 0; i < ints.length; i++) {
if (ints[i][0] > 0) {
flag = true;
break ;
}
}
locFreq = ints;
}
2、具体实现
2.1识别出可能的人名
Result terms = ToAnalysis.parse("罗毅虎和曹罗伟是高中同学");
System.out.println("分词结果:" + terms);
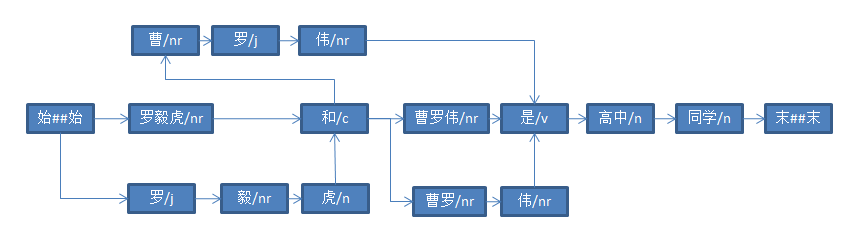
2.2、计算人名概率的一些理论基础
要想判断“曹罗伟”和“曹罗”哪个在此处更适合做人名,当然要计算二者存在的概率。
在谈到ansj的计算方法之前,我们先共同学习一下基于角色标注的中国人名自动识别研究这篇论文。(强烈建议读了这篇论文再往下看)
该论文将人名识别问题转化为了,对人名构成角色进行标注的问题。(详见论文的2.1、2.2)
我们要求解最终标注结果$T^{\#}=arg_{T}\,max\,P(T|W)$
论文中并不是直接求解$P(T|W)$,而是通过Bayes公式间接求解:
$P(T|W) = P(T)P(W|T)/P(W)$
没有直接求解,无非就是因为$P(T|W)$直接求解比较困难,或者根本无法直接求解。
我们先来看$P(t_{i}|w_{i})$是指:Token序列中的$w_{i}$,角色是$t_{i}$的概率。例如,对于人名识别前的Token序列:
$P(t_{i}|w_{i})$可以是指,“曹”这个$w_{i}$,角色是“三字姓名姓氏”的概率。
在大规模语料库训练的前提下,我们可以得到:
$P(t_{i}|w_{i})\approx C(t_{i},w_{i})/C(w_{i})$
其中,$C(t_{i},w_{i})$指角色$t_{i}$中出现$w_{i}$的次数,$C(w_{i})$是$w_{i}$出现的次数。
(1)、$C(w_{i})$是从大规模预料中统计出来,并保存在core词库中的,对该核心词库的整理,与人名识别无关,例如:
值得一提的是,$P(w_{i}|t_{i})$和$P(w_{i-1}|t_{i-1})$之间是相互独立的事件。
论文中提到,$P(W)$是一个常数。这确实是一个常数。并且,我们已经在现有核心词库(core.dic)的基础上,算得了这个数值。这正是上一节所讨论的内容。
2.3、计算人名概率
allFreq += Math.log(term.termNatures().allFreq + 1);
allFreq += -Math.log((freq));
但问题是,$C(w_{i})$ 和$C(t_{i},w_{i})$的统计来自不同的语料,所以这里的算法是没有理论依据的。
2.4、构造最短路径
计算完概率后,就可以使用Viterbi算法来求解最短路径,这与上一节类似。
以“陈颖超生前很和蔼”为例,将会得到以下结果:
2.5、人名消歧
2.6、用户自定义字典识别
// 用户自定义词典的识别
userDefineRecognition(graph, forests);
ansj人名识别的更多相关文章
- Hanlp实战HMM-Viterbi角色标注中国人名识别
这几天写完了人名识别模块,与分词放到一起形成了两层隐马模型.虽然在算法或模型上没有什么新意,但是胜在训练语料比较新,对质量把关比较严,实测效果很满意.比如这句真实的新闻“签约仪式前,秦光荣.李纪恒.仇 ...
- HanLP中人名识别分析
HanLP中人名识别分析 在看源码之前,先看几遍论文<基于角色标注的中国人名自动识别研究> 关于命名识别的一些问题,可参考下列一些issue: 名字识别的问题 #387 机构名识别错误 关 ...
- HanLP中人名识别分析详解
HanLP中人名识别分析详解 在看源码之前,先看几遍论文<基于角色标注的中国人名自动识别研究> 关于命名识别的一些问题,可参考下列一些issue: l ·名字识别的问题 #387 l ·机 ...
- HanLP中的人名识别分析详解
在看源码之前,先看几遍论文<基于角色标注的中国人名自动识别研究> 关于命名识别的一些问题,可参考下列一些issue: u u名字识别的问题 #387 u u机构名识别错误 u u关于层叠H ...
- ICTCLAS中的HMM人名识别
http://www.hankcs.com/nlp/segment/ictclas-the-hmm-name-recognition.html 本文主要从代码的角度分析标注过程中的细节,理论谁都能说, ...
- 【文智背后的奥秘】系列篇——基于CRF的人名识别
版权声明:本文由文智原创文章,转载请注明出处: 文章原文链接:https://www.qcloud.com/community/article/133 来源:腾云阁 https://www.qclou ...
- 基于分布式的短文本命题实体识别之----人名识别(python实现)
目前对中文分词精度影响最大的主要是两方面:未登录词的识别和歧义切分. 据统计:未登录词中中文姓人名在文本中一般只占2%左右,但这其中高达50%以上的人名会产生切分错误.在所有的分词错误中,与人名有关的 ...
- hanlp自然语言处理包的人名识别代码解析
HanLP发射矩阵词典nr.txt中收录单字姓氏393个.袁义达在<中国的三大姓氏是如何统计出来的>文献中指出:当代中国100个常见姓氏中,集中了全国人口的87%,根据这一数据我们只保留n ...
- HanLP-基于HMM-Viterbi的人名识别原理介绍
Hanlp自然语言处理包中的基于HMM-Viterbi处理人名识别的内容大概在年初的有分享过这类的文章,时间稍微久了一点,有点忘记了.看了 baiziyu 分享的这篇比我之前分享的要简单明了的多.下面 ...
随机推荐
- 如何解决Asp.Net中不能上传压缩文件的问题
在使用Asp.Net自带的服务器端控件Fileupload上传文件时,可能会出现不能上传压缩文件的问题,此时可以通过下面的方法解决: 在<system.web>中添加: <httpR ...
- saiku应用的调试
ubuntu下解压saiku包后使用: 运行.sh命令(.bat是windows命令).运行时注意权限.可以先chmod a+x *.sh 提示,catali?.sh出错. 这是tomcat的一个文件 ...
- 销售订单-修改量-高级定价关联sql
修改量消耗明细 --修改量消耗明细 SELECT t.name, t.comments, t.version_no, cux_rebate_pub.get_hou_name(p_organizatio ...
- LeetCode之“字符串”:最短回文子串
题目链接 题目要求: Given a string S, you are allowed to convert it to a palindrome by adding characters in f ...
- Oracle EBS 预警系统管理(可用于配置工作流发审批邮件)
本章主要讲述配置和设置Oracle EBS预警系统管理, 它比较方便和及时发用户或系统对数据库操作情况.下面讲一操作步聚: 1.预警系统管理-->系统-->选项 名称"Unix ...
- Java中的ReentrantLock和synchronized两种锁机制的对比
原文:http://www.ibm.com/developerworks/cn/java/j-jtp10264/index.html 多线程和并发性并不是什么新内容,但是 Java 语言设计中的创新之 ...
- C# Word转为多种格式文件(Word转XPS/SVG/EMF/EPUB/TIFF)
一款有着强大的文档转换功能的工具,无论何时何地都会是现代办公环境极为需要的.在本篇文章中,将继续介绍关于Word文档的转换功能(Word转XPS/SVG/EMF/EPUB/TIFF)希望方法中的代码能 ...
- Oracle常用数据库对象(片段)
1:用户和权限 1.1 用户的创建 a)语法--- create user 用户名 identified by 密码: b)创建用户abcd,并设定密码为abcd;---注意:操作数据库对象是 ...
- ES6中Promise详解
Promise,简单说就是一个容器,里面保存着某个未来才会结束的事件(通常是一个异步操作)的结果.从语法上说,Promise 是一个对象,从它可以获取异步操作的消息. Promise 提供统一的 AP ...
- Idea(一) 安装与破解
现在idea横行的时代,没用过idea都不好意思了,于是乎,我也下载感受下. 下载安装包和破解地址: 链接: https://pan.baidu.com/s/16OeiDw942JaPXKtc9Oz1 ...