kafka原理简介并且与RabbitMQ的选择
kafka原理简介并且与RabbitMQ的选择
kafka原理简介,rabbitMQ介绍,大致说一下区别
Kafka是由LinkedIn开发的一个分布式的消息系统,使用Scala编写,它以可水平扩展和高吞吐率而被广泛使用。目前越来越多的开源分布式处理系统如Cloudera、Apache Storm、Spark都支持与Kafka集成。
消息的发布描述为producer,消息的订阅描述为consumer,将中间的存储阵列称作broker(代理)。kafka是linkedin用于日志处理的分布式消息队列,同时支持离线和在线日志处理。kafka对消息保存时根据Topic进行归类,发送消息者就是Producer,消息接受者就是Consumer,每个kafka实例称为broker。然后三者都通过Zookeeper进行协调。
kafka存储是基于硬盘存储的,然而却有着快速的读写效率,一个 67200rpm STAT RAID5 的阵列,线性读写速度是 300MB/sec,如果是随机读写,速度则是 50K/sec。
虽然都知道内存读取速度会明显快于硬盘读写速度,但是kafka却通过线性读写的方式实现快速地读写。
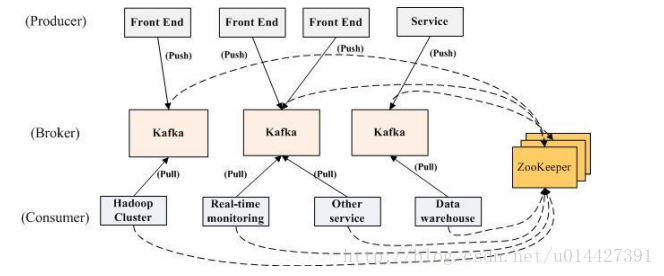
Producer
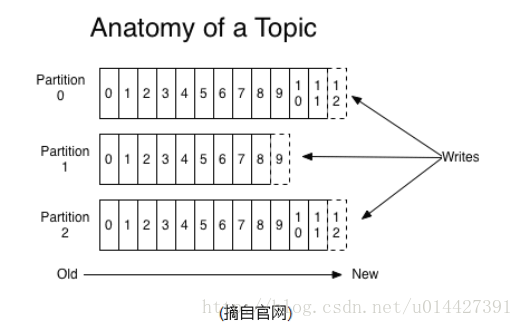
学习kafka一定要理解好Topic,每个Topic被分成多个partition(区)。每条消息在partition中的位置称为offset(偏移量),类型为long型数字。消息即使被消费了,也不会被立即删除,而是根据broker里的设置,保存一定时间后再清除,比如log文件设置存储两天,则两天后,不管消息是否被消费,都清除。
Broker
broker也即中间的存储队列。我们将消息的収布(publish)暂时称作 producer,将消息的订阅(subscribe)表述为consumer,将中间的存储阵列称作 broker(代理)。
Consumer
每个consumer属于一个consumer group。在kafka中,一个partition的消息只会被group中的一个consumer消费;可以认为一个group就是一个“订阅者”。一个Topic中的每个partition只会被一个“订阅者”中的一个consumer消费。
Zookeeper
kafka集群几乎不需要维护任何Consumer和Producer的信息。这些信息由Zookeeper保存。发送到Topic的消息,只会被订阅此Topic的每个group中的一个consumer消费。
Kafka优点
解耦
在项目启动之初来预测将来项目会碰到什么需求,是极其困难的。消息系统在处理过程中间插入了一个隐含的、基于数据的接口层,两边的处理过程都要实现这一接口。这允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束。
冗余
有些情况下,处理数据的过程会失败。除非数据被持久化,否则将造成丢失。消息队列把数据进行持久化直到它们已经被完全处理,通过这一方式规避了数据丢失风险。许多消息队列所采用的”插入-获取-删除”范式中,在把一个消息从队列中删除之前,需要你的处理系统明确的指出该消息已经被处理完毕,从而确保你的数据被安全的保存直到你使用完毕。
扩展性
因为消息队列解耦了你的处理过程,所以增大消息入队和处理的频率是很容易的,只要另外增加处理过程即可。不需要改变代码、不需要调节参数。扩展就像调大电力按钮一样简单。
灵活性 & 峰值处理能力
在访问量剧增的情况下,应用仍然需要继续发挥作用,但是这样的突发流量并不常见;如果为以能处理这类峰值访问为标准来投入资源随时待命无疑是巨大的浪费。使用消息队列能够使关键组件顶住突发的访问压力,而不会因为突发的超负荷的请求而完全崩溃。
可恢复性
系统的一部分组件失效时,不会影响到整个系统。消息队列降低了进程间的耦合度,所以即使一个处理消息的进程挂掉,加入队列中的消息仍然可以在系统恢复后被处理。
顺序保证
在大多使用场景下,数据处理的顺序都很重要。大部分消息队列本来就是排序的,并且能保证数据会按照特定的顺序来处理。Kafka保证一个Partition内的消息的有序性。
缓冲
在任何重要的系统中,都会有需要不同的处理时间的元素。例如,加载一张图片比应用过滤器花费更少的时间。消息队列通过一个缓冲层来帮助任务最高效率的执行。写入队列的处理会尽可能的快速。该缓冲有助于控制和优化数据流经过系统的速度。
异步通信
很多时候,用户不想也不需要立即处理消息。消息队列提供了异步处理机制,允许用户把一个消息放入队列,但并不立即处理它。想向队列中放入多少消息就放多少,然后在需要的时候再去处理它们。
业界对于消息的传递有多种方案和产品,本文就比较有代表性的两个MQ(rabbitMQ,kafka)进行阐述和做简单的对比,
在应用场景方面,
RabbitMQ,遵循AMQP协议,由内在高并发的erlanng语言开发,用在实时的对可靠性要求比较高的消息传递上。
kafka是Linkedin于2010年12月份开源的消息发布订阅系统,它主要用于处理活跃的流式数据,大数据量的数据处理上。
1)在架构模型方面,
RabbitMQ遵循AMQP协议,RabbitMQ的broker由Exchange,Binding,queue组成,其中exchange和binding组成了消息的路由键;客户端Producer通过连接channel和server进行通信,Consumer从queue获取消息进行消费(长连接,queue有消息会推送到consumer端,consumer循环从输入流读取数据)。rabbitMQ以broker为中心;有消息的确认机制。
kafka遵从一般的MQ结构,producer,broker,consumer,以consumer为中心,消息的消费信息保存的客户端consumer上,consumer根据消费的点,从broker上批量pull数据;无消息确认机制。
2)在吞吐量,
kafka具有高的吞吐量,内部采用消息的批量处理,zero-copy机制,数据的存储和获取是本地磁盘顺序批量操作,具有O(1)的复杂度,消息处理的效率很高。
rabbitMQ在吞吐量方面稍逊于kafka,他们的出发点不一样,rabbitMQ支持对消息的可靠的传递,支持事务,不支持批量的操作;基于存储的可靠性的要求存储可以采用内存或者硬盘。
3)在可用性方面,
rabbitMQ支持miror的queue,主queue失效,miror queue接管。
kafka的broker支持主备模式。
4)在集群负载均衡方面,
kafka采用zookeeper对集群中的broker、consumer进行管理,可以注册topic到zookeeper上;通过zookeeper的协调机制,producer保存对应topic的broker信息,可以随机或者轮询发送到broker上;并且producer可以基于语义指定分片,消息发送到broker的某分片上。
rabbitMQ的负载均衡需要单独的loadbalancer进行支持。
所以关于这两个选择,我们还是了解了这4个大致的区别。关于高吞吐,以及我们队日志的特定场景分析,任然选择了,kafka。当然设计理念不一样,rabbitMQ用于可靠的消息传递,智齿事物,不支持批量的操作,可用性差不多,只是实现不一样。在集群方面,kafka胜一筹,通过topic注册zookeeper,调用机制,实现语义指定分片,然而rabbitMQ的负载需要单独loadbalancer支持
kafka原理简介并且与RabbitMQ的选择的更多相关文章
- kafka工作原理简介
消息队列 消息队列技术是分布式应用间交换信息的一种技术.消息队列可驻留在内存或磁盘上, 队列存储消息直到它们被应用程序读走.通过消息队列,应用程序可独立地执行--它们不需要知道彼此的位置.或在继续执行 ...
- [转帖]Kafka 原理和实战
Kafka 原理和实战 https://segmentfault.com/a/1190000020120043 两个小时读完... 实在是看不完... 1.2k 次阅读 · 读完需要 101 分钟 ...
- Kafka(一)Kafka的简介与架构
一.简介 1.1 概述 Kafka是最初由Linkedin公司开发,是一个分布式.分区的.多副本的.多订阅者,基于zookeeper协调的分布式日志系统(也可以当做MQ系统),常见可以用于web/ng ...
- kafka原理和实践(一)原理:10分钟入门
系列目录 kafka原理和实践(一)原理:10分钟入门 kafka原理和实践(二)spring-kafka简单实践 kafka原理和实践(三)spring-kafka生产者源码 kafka原理和实践( ...
- kafka原理和实践(六)总结升华
系列目录 kafka原理和实践(一)原理:10分钟入门 kafka原理和实践(二)spring-kafka简单实践 kafka原理和实践(三)spring-kafka生产者源码 kafka原理和实践( ...
- kafka原理和实践(三)spring-kafka生产者源码
系列目录 kafka原理和实践(一)原理:10分钟入门 kafka原理和实践(二)spring-kafka简单实践 kafka原理和实践(三)spring-kafka生产者源码 kafka原理和实践( ...
- Nginx 负载均衡原理简介与负载均衡配置详解
Nginx负载均衡原理简介与负载均衡配置详解 by:授客 QQ:1033553122 测试环境 nginx-1.10.0 负载均衡原理 客户端向反向代理发送请求,接着反向代理根据某种负载机制 ...
- Nginx 反向代理工作原理简介与配置详解
Nginx反向代理工作原理简介与配置详解 by:授客 QQ:1033553122 测试环境 CentOS 6.5-x86_64 nginx-1.10.0 下载地址:http://nginx. ...
- Oracle Golden Gate原理简介
Oracle Golden Gate原理简介 http://www.askoracle.org/oracle/HighAvailability/20140109953.html#6545406-tsi ...
随机推荐
- JAVA中抽象类的使用
抽象类是从多个具体类中抽象出来的父类,它具有更高层次的抽象.抽象类体现的就是一种模板模式的设计,抽象父类可以只定义需要使用的某些方法,把不能实现的某些部分抽象成抽象方法,留给其子类去实现.具体来说,抽 ...
- android JNI的.so库调用
在一篇博客中看到一篇文章,感觉描述的还可以: 在前面的博客中介绍的都是使用java开发Android应用,这篇博客将介绍java通过使用jni调用c语言做开发 为了更加形象的介绍jni,先观察下面的图 ...
- gdb不知为何显示2次析构
gdb不知为何显示2次析构 (金庆的专栏 2016.11) gdb 显示2次 A::~A(): (gdb) bt #0 A::~A (this=0x602010, __in_chrg=<opti ...
- 最优秀的网络框架retrofit
由于某学员要求所以我打算写一篇 标题先记录下来 我会在一周内完成此篇文章
- 让你的代码量减少3倍!使用kotlin开发Android(二) --秘笈!扩展函数
本文承接上一篇文章:让你的代码量减少3倍!使用kotlin开发Android(一) 创建Kotlin工程 本文同步自博主的私人博客wing的地方酒馆 上一节说到,kotlin可以省去getter,se ...
- nginx+tomcat负载均衡和session复制
本文介绍下传统的tomcat负载均衡和session复制. session复制是基于JVM内存的,当然在当今的互联网大数据时代,有更好的替代方案,如将session数据保存在Redis中. 1.安装n ...
- Swift下多个Storyboard的项目结构
我是个比较喜欢用storyboard和xib的人.我个人的习惯就是,能用storyboard的一定不用代码手工撸.当然自己业余个人写的项目,基本上一个storyboard就搞定了.但涉及到多人合作下时 ...
- Spring基础配置
从毕业到现在我一直从事Android开发,但是对JavaEE一直念念不忘,毕业校招的时候,一个礼拜拿了三个offer,岗位分别是Android.JavaEE和JavaSE,后来觉得Android比较简 ...
- String、StringBuffer、StringBuilder对比
1.String 用于存放字符的数组被声明为final的,因此只能赋值一次,不可再更改.这就导致每次对String的操作都会生成新的String对象,不仅效率低下,而且大量浪费有限的内存空间. Str ...
- 子库存-OU-库存组织-关系
SELECT hou.organization_id ou_org_id, --org_id hou.name ou_name, --ou名称 ood.organization_id org_org_ ...