Redis --> Redis架构设计
Redis架构设计
一、前言
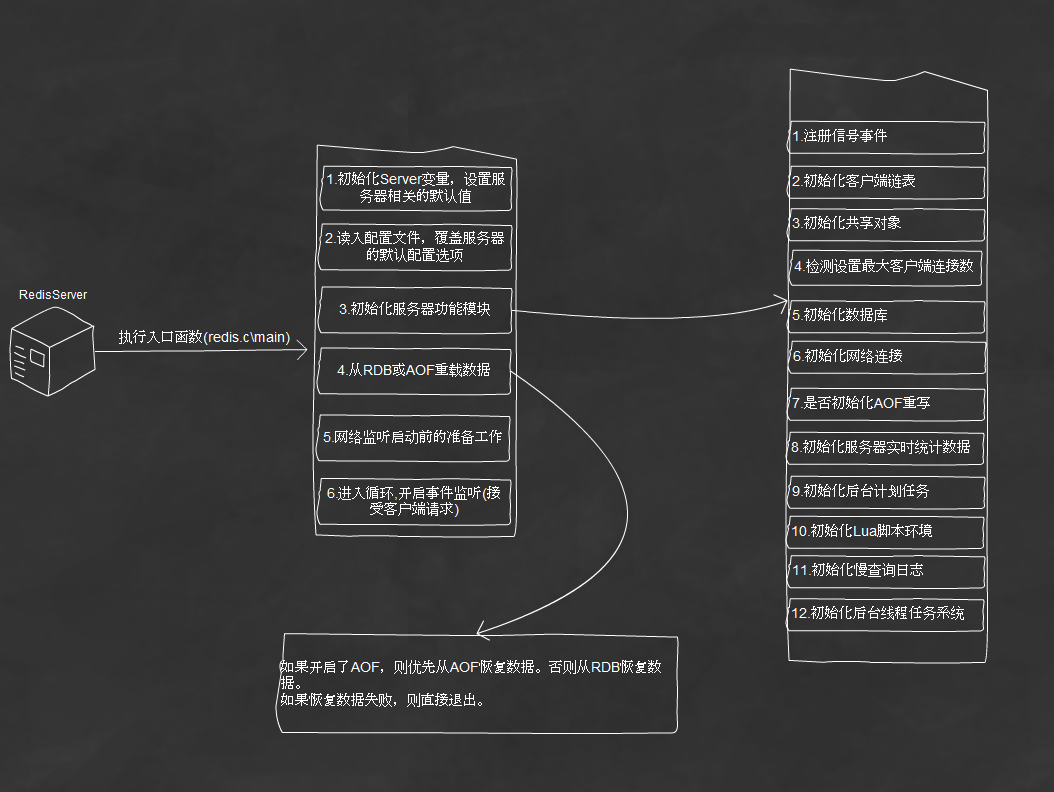
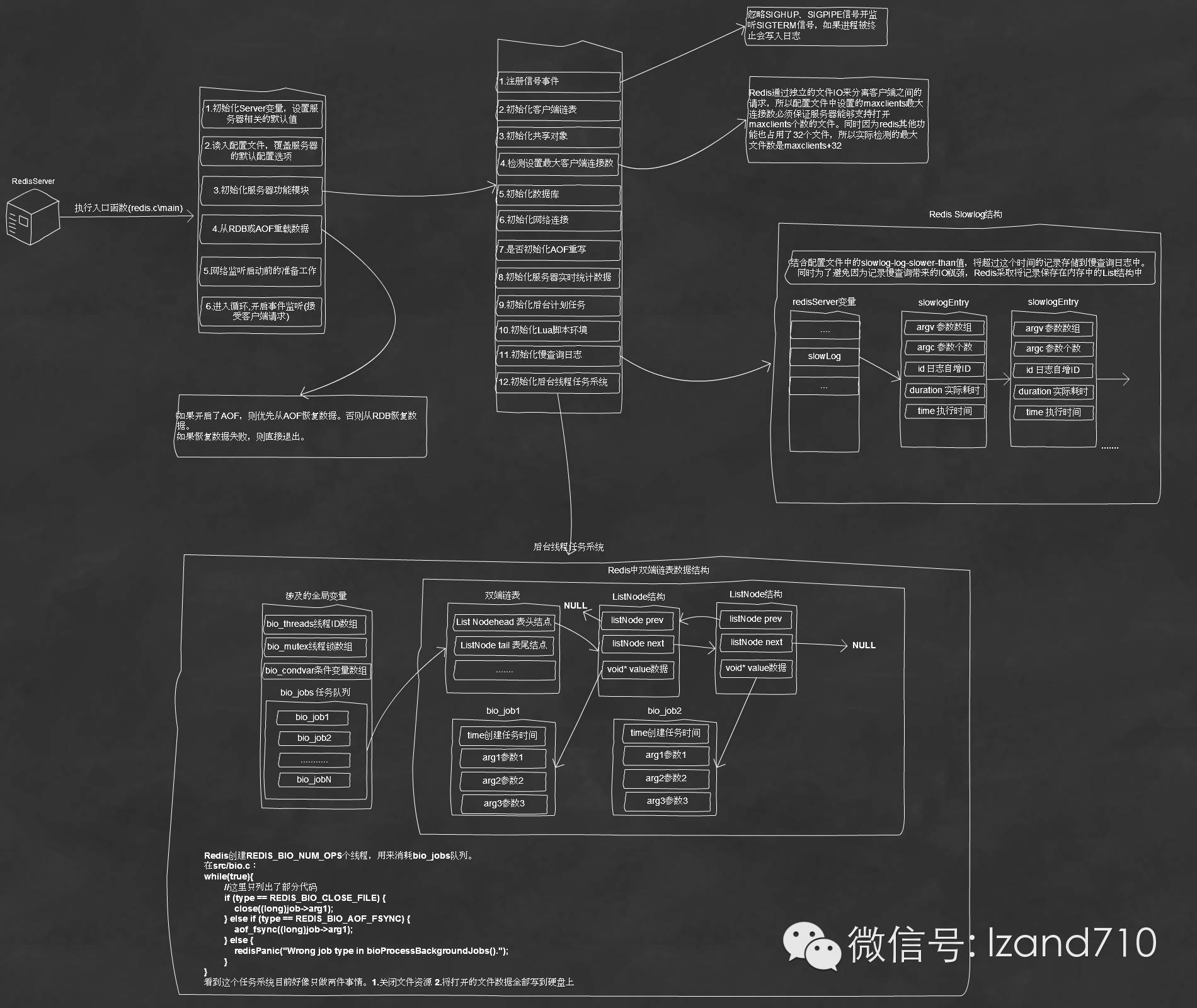
二、redis启动流程
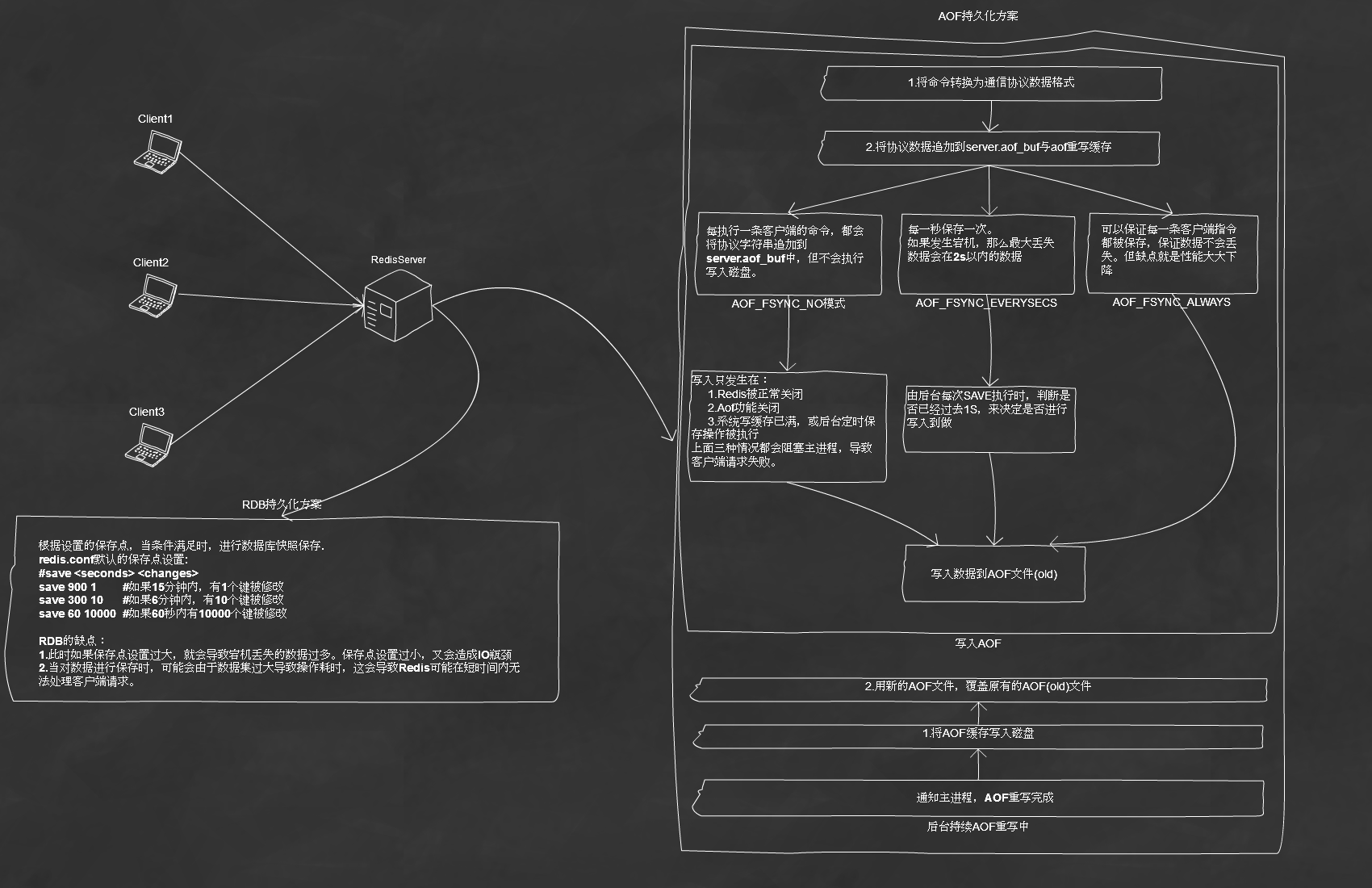
三、Redis数据持久化方案
1.RDB持久化方案
a)保存(rdbSave)
b)读取(rdbLoad)
#save <seconds> <changes>
save //如果15分钟内,有1个键被修改
save //如果6分钟内,有10个键被修改
save //如果60秒内有10000个键被修改
2.AOF持久化方案
a)保存
b)读取
LPUSH list
LPOP list
LPOP list
LPUSH list
最初保存到AOF文件的将会是四条指令。但经过AOF重写后,会变成一条指令:
LPUSH list
c)AOF重写流程
d)AOF缺点
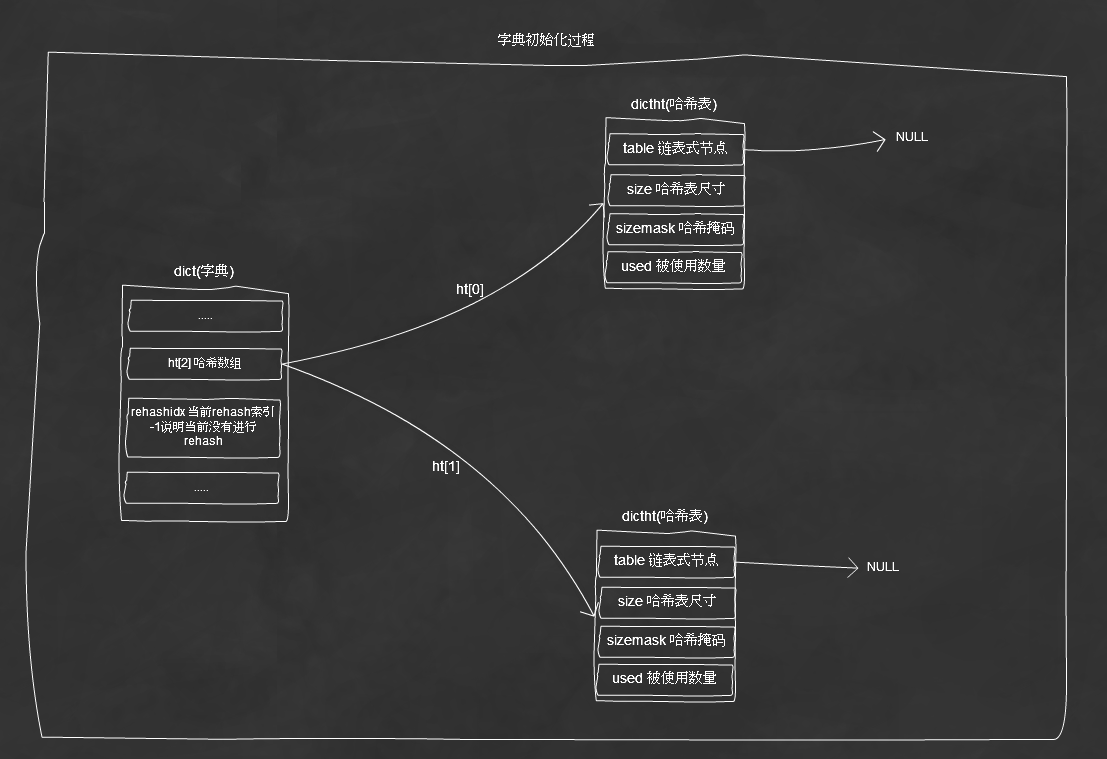
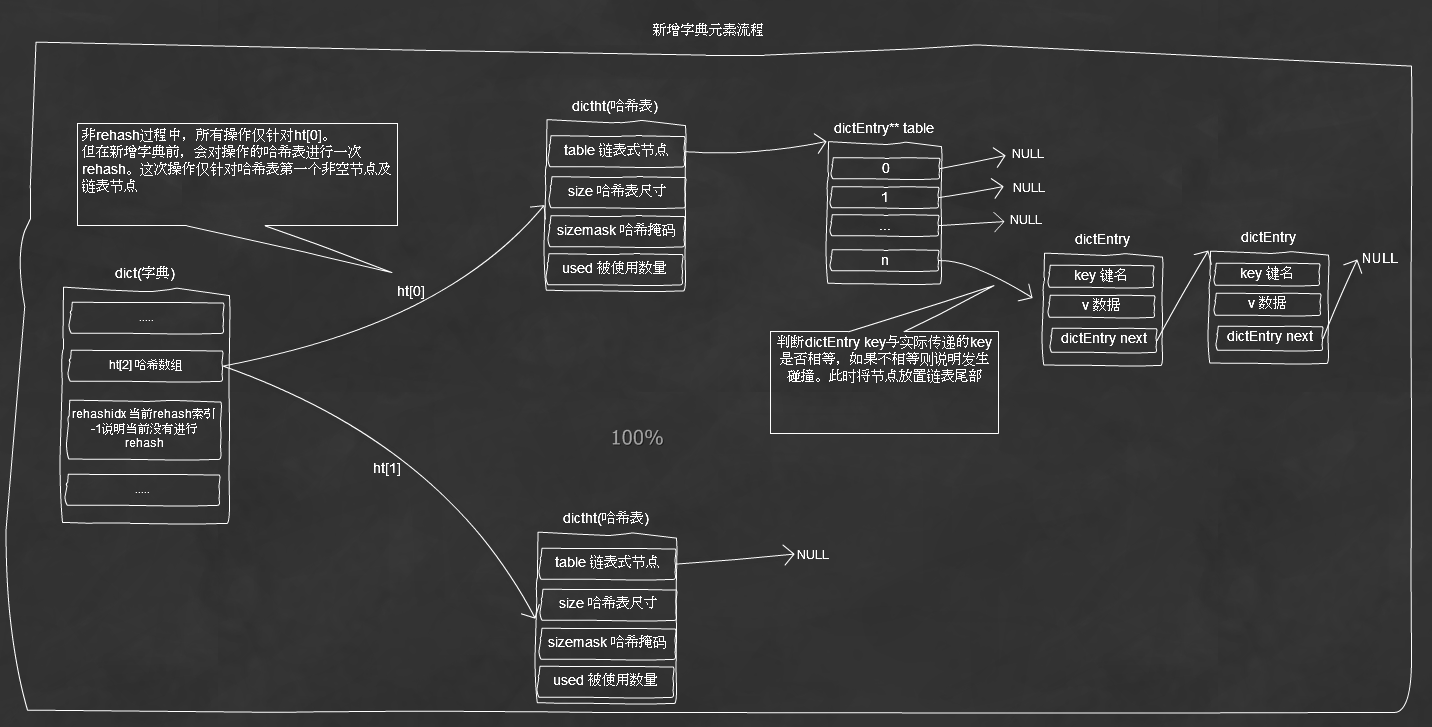
四、Redis数据库的实现
a)PHP主要应用于WEB场景,在WEB场景针对单次请求数据之间是隔离的,并且哈希的数量是有限的,那么进行一次rehash也是很快的。所以PHP内核使用阻塞形式rehash,即rehash进行中将不能对当前哈希表进行任何操作。

Redis --> Redis架构设计的更多相关文章
- Redis缓存项目应用架构设计二
一.概述 由于架构设计一里面如果多平台公用相同Key的缓存更改配置后需要多平台上传最新的缓存配置文件来更新,比较麻烦,更新了架构设计二实现了缓存配置的集中管理,不过这样有有了过于中心化的问题,后续在看 ...
- 亿级流量场景下,大型缓存架构设计实现【1】---redis篇
*****************开篇介绍**************** -------------------------------------------------------------- ...
- Redis架构设计
高可用Redis服务架构分析与搭建 各种web开发业务中最为常用的key-value数据库了 应用: 在业务中用其存储用户登陆态(Session存储),加速一些热数据的查询(相比较mysql而言,速度 ...
- 细说分布式Redis架构设计和踩过的那些坑
细说分布式Redis架构设计和踩过的那些坑_redis 分布式_ redis 分布式锁_分布式缓存redis 细说分布式Redis架构设计和踩过的那些坑
- Redis 高可用架构设计(转载)
转载自:https://mp.weixin.qq.com/s?__biz=MzA3NDcyMTQyNQ==&mid=2649263292&idx=1&sn=b170390684 ...
- Redis的高并发、持久化、高可用架构设计
就是如果你用redis缓存技术的话,肯定要考虑如何用redis来加多台机器,保证redis是高并发的,还有就是如何让Redis保证自己不是挂掉以后就直接死掉了,redis高可用 我这里会选用我之前讲解 ...
- 《【面试突击】— Redis篇》--Redis Cluster及缓存使用和架构设计的常见问题
能坚持别人不能坚持的,才能拥有别人未曾拥有的.关注编程大道公众号,让我们一同坚持心中所想,一起成长!! <[面试突击]— Redis篇>--Redis Cluster及缓存使用和架构设计的 ...
- Redis初识、设计思想与一些学习资源推荐
一.Redis简介 1.什么是Redis Redis 是一个开源的使用ANSI C 语言编写.支持网络.可基于内存亦可持久化的日志型.Key-Value 数据库,并提供多种语言的API.从2010 年 ...
- Redis Cluster架构优化
Redis Cluster架构优化 在<全面剖析Redis Cluster原理和应用>中,我们已经详细剖析了现阶段Redis Cluster的缺点: 无中心化架构 Gossip消息的开销 ...
随机推荐
- Linux 系统裁剪笔记 4 (内核配置选项及删改)
CDROM filesystem support(CONFIG_ISO9660_FS)[Y/m/n/?]有标准光驱的系统应该选Y.Minix fs support(CONFIG_MINIX_FS)[ ...
- 快速开发 HTML5 交互式地铁线路图
前言 前两天在 echarts 上寻找灵感的时候,看到了很多有关地图类似的例子,地图定位等等,但是好像就是没有地铁线路图,就自己花了一些时间捣鼓出来了这个交互式地铁线路图的 Demo,地铁线路上的点是 ...
- python version 2. required,which was not found in the registry 解决方案
不能在注册表中识别python2.7 新建一个register.py 文件 import sys from _winreg import * # tweak as necessary version ...
- idea好用插件(一)
代码规范插件 Alibaba Java Coding Guidelines 安装后 可以在文件.文件夹邮件,显示编码规约扫描,点击后显示 可以通过双击定位问题代码,对某些问题可以进行快速的修复 比如: ...
- C# Coding Conventions(译)
C# Coding Conventions C#编码规范 Naming Conventions 命名规范Layout Conventions 布局规范Commenting Conventions 注释 ...
- 多线程之倒计时器CountDownLatch和循环栅栏CyclicBarrier
1.倒计时器CountDownLatch CountDownLatch是一个多线程控制工具类.通常用来控制线程等待,它可以让一个线程一直等待知道计时结束才开始执行 构造函数: public Count ...
- 都是SCI惹的祸?
都是SCI惹的祸? 过去只知道地质学家需要跋山涉水寻找宝藏,最近同一位海外归来的学者谈起,方知少数其它领域的科研人员,也"跋山涉水",在内地研究机构寻找可以写好文章的研究成果,不管 ...
- 【BZOJ2555】SubString(后缀自动机,Link-Cut Tree)
[BZOJ2555]SubString(后缀自动机,Link-Cut Tree) 题面 BZOJ 题解 这题看起来不难 每次要求的就是\(right/endpos\)集合的大小 所以搞一个\(LCT\ ...
- 【Luogu1879】玉米田(状态压缩,动态规划)
懒得搞题目了 哦对了,这题双倍经验 题解 装压DP 利用位运算很容易解决相邻位的问题 其实我的还是太复杂了 具体的,更加好的位运算的写法可以参考YL大佬,但是我也搞不到他代码,因为他太强了. 然而他博 ...
- 【bzoj2151】种树
Time Limit: 1000ms Memory Limit: 128MB Description A城市有一个巨大的圆形广场,为了绿化环境和净化空气,市政府 ...