了解ASCII、gb系列、Unicode、UTF-8的区别
转自:http://www.douban.com/note/334994123/?type=rec
● 为什么有这么多编码?
● UTF-8和GB2312有什么区别?
● 我们在国内做网站是用UTF-8编码格式还是GB2312编码格式好?
1. ASCII码
美国:八个二进制位就可以组合出256种状态,这被称为一个字节(byte)。ASCII码一共规定了128个字符的编码,这128个符号(包括32个不能打印出来的控制符号),只占用了一个字节的后面7位,最前面的1位统一规定为0。
2.非ASCII码
(1)其他非英语国家,各自为政,将剩下的128个未占用状态填充上自己的语言。这也仅可添加128种,对于高达10万的汉字来讲肯定是不够的。
(2)GB2312。于是GB2312就出来了,GB2312 是对 ASCII 的中文扩展, 规定:一个小于127的字符的意义与原来相同,但两个大于127的字符连在一起时,就表示一个汉字,前面的一个字节(他称之为高字节)从0xA1用到0xF7,后面一个字节(低字节)从0xA1到0xFE,这样我们就可以组合出大约7000多个简体汉字了。
(3)GBK。但是这对于汉字来讲还是不够,于是干脆不再要求低字节一定是127号之后的内码,只要第一个字节是大于127就固定表示这是一个汉字的开始,不管后面跟的是不是扩展字符集里的内容。结果扩展之后的编码方案被称为 GBK 标准,GBK 包括了 GB2312 的所有内容,同时又增加了近20000个新的汉字(包括繁体字)和符号。
(4)GB18030。对于GBK再扩展,加入几千个新的少数民族的字。
基于(2)(3)(4),于是教科书上就出现了 1个字节==8个二进制位,1个英文字母==1个字符==1个字节,1个汉字==2个字节。。。好吧,已经忘记了课本上在这些定义之前是否加了在GB2312下之类的前提。
3.UNICODE编码
每个国家都搞出像天朝这样一套自己的编码标准,于是ISO(国际标谁化组织)重新搞了一套标准--UNICODE, 在UNICODE中,一个汉字算两个英文字符的时代已经快过去了。
UNICODE的UCS-2编码方式是定长双字节编码,包括英文字母在内。UCS-2只能表示65535个字符,IOS预备了UCS-4方案,四个字节来表示一个字符,可以组合出21亿个不同的字符出来(最高位有其他用途)。英文字母只用一个字节表示就够了,但是其他更大的符号可能需要3个字节或者4个字节,甚至更多。如果Unicode统一规定,每个符号用三个或四个字节表示,那么每个英文字母前都必然有二到三个字节是0,这对于存储来说是极大的浪费。
需要注意的是,Unicode只是一个符号集,它只规定了符号的二进制代码,却没有规定这个二进制代码应该如何存储。于是出现了多种存储方式,也就是说有许多种不同的二进制格式,可以用来表示unicode。unicode在很长一段时间内无法推广,直到互联网的出现。
4.UTF-8
UTF-8是Unicode的实现方式之一,传输、存储,其他还有UTF-16(字符用两个字节或四个字节表示),UTF-32(字符用四个字节表示)。
UTF-8最大的一个特点,就是它是一种变长的编码方式。它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度。1个字节==8个二进制位==2^8==256。
UTF-8的编码规则很简单,只有二条:
(1)对于单字节的符号,字节的第一位设为0,后面7位为这个符号的unicode码。因此对于英语字母,UTF-8编码和ASCII码是相同的。
(2)对于n字节的符号(n>1),第一个字节的前n位都设为1,第n+1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的unicode码。
下表总结了编码规则,字母x表示可用编码的位。
Unicode符号范围 | UTF-8编码方式
(十六进制) | (二进制)
--------------------+---------------------------------------------
0000 0000-0000 007F | 0xxxxxxx
0000 0080-0000 07FF | 110xxxxx 10xxxxxx
0000 0800-0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx
0001 0000-0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
跟据上表,解读UTF-8编码非常简单。如果一个字节的第一位是0,则这个字节单独就是一个字符;如果第一位是1,则连续有多少个1,就表示当前字符占用多少个字节。 另外,当一个字符需要两个以上字节表示时,比如用“中”的unicode编码是D6 D0,那么具体存储(传输)的时候是D0在前还是D6在前都是可以的,因此就产生了Little endian和Big endian。Little endian就是D0 D6的存储,Big endian就是D6 D0的方式。 总之,你可以这么认为,unicode就好比Java中的接口,它只规定一些规则内容方法,UTF-8是具体的实现,考虑了很多实际的东西。
例如"汉"字的Unicode编码是6C49。6C49在0800-FFFF之间,
所以要用3字节模板:1110xxxx 10xxxxxx 10xxxxxx。
将6C49写成二进制是:0110 1100 0100 1001,
将这个比特流按三字节模板的分段方法分为0110 110001 001001,
依次代替模板中的x,得到:1110-0110 10-110001 10-001001,
即E6 B1 89,这就是其UTF8的编码。
计算机系统通用的字符编码工作方式:
在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或者需要传输的时候,就转换为UTF-8编码。
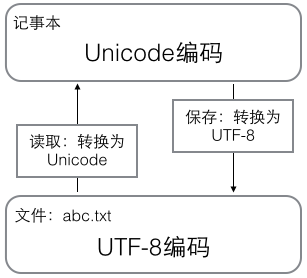
用记事本编辑的时候,从文件读取的UTF-8字符被转换为Unicode字符到内存里,编辑完成后,保存的时候再把Unicode转换为UTF-8保存到文件:
浏览网页的时候,服务器会把动态生成的Unicode内容转换为UTF-8再传输到浏览器:
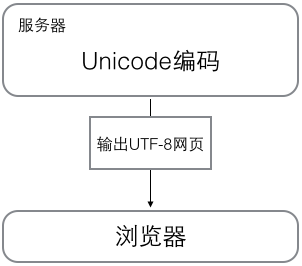
所以很多网页的源码上会有类似<meta charset="UTF-8" />的信息,表示该网页正是用的UTF-8编码。
5.当一个软件打开一个文本时,它要做的第一件事是决定这个文本究竟是使用哪种字符集的哪种编码保存的。最标准的途径是检测文本最开头的几个字节,开头字节 Charset/encoding,如下表:
EF BB BF UTF-8
FE FF UTF-16/UCS-2, little endian
FF FE UTF-16/UCS-2, big endian
FF FE 00 00 UTF-32/UCS-4, little endian.
00 00 FE FF UTF-32/UCS-4, big-endian.
big endian和little endian是CPU处理多字节数的不同方式。
例如“汉”字的Unicode编码是6C49。那么写到文件里时,
究竟是将6C写在前面,还是将49写在前面?
如果将6C写在前面,就是big endian。
还是将49写在前面,就是little endian。
从ASCII、GB2312、GBK到GB18030,这些编码方法是向下兼容的,
即同一个字符在这些方案中总是有相同的编码,后面的标准支持更多的字符。
6.为什么国内几个网站用GB2312反而更多些呢。
(1) 国内这些网站本身历史也比较长,开始使用的就是 GB2312编码,现在改成 UTF-8(以前的网页)转换的难度和风险太大。
(2)UTF-8编码的文件比GB2312更占空间一些,虽然目前的硬件环境下可以忽略,但是这些门户网站为了减少服务器负载基本上所有的页面都生成了静态页,UTF-8保存起来文件会比较大,对于门户级别的网站每天生成的文件量还是非常巨大,带来的存储成本相应提高。
(3)由于UTF-8的编码比GB2312解码的网络传输数据量要大,对于门户级别的网站来说。这个无形之间就要增大带宽,用GB2312对网络流量无疑是最好的优化。
所以在新做站的情况下,建议还是选择UTF-8比较好。因为没有上面那些原因,兼容为上策。早期的优化是万恶之源。
字符'0'和'\0',及整数0的区别
有区别, 字符0的ASCII码实际上是48,C语言中字符0 只占一个字节(Byte),也就是内存中存放的是 01001000 (其中每一个0或1表示一个bit位)
而整数0, 它在内存中的表示全是0,C语言中一个整数的占4个字节,整数0在内存中的表示为: 00000000 00000000 00000000 00000000 . 如下:
char c = '0'; //字符0
int a = 0; //整数0
printf("%c, %d\n", c, a); //0,0
printf("%d\n", c); //48 用整数形式答应字符,实际是打印c在内存中的值。
printf("%d\n", (c+a)); //48
printf("%c\n", (char)(c+a)); //0
输出的结果:
0,0 从上面你就能看出字符0和整数0的区别了。
ASCII码对照表可见如下链接:
http://www.asciima.com/
了解ASCII、gb系列、Unicode、UTF-8的区别的更多相关文章
- 关于几种编码详解(Unicode,UTF-8,GB系列)
最近学Python,老是被编码的问题搞得晕乎乎的,晚上看了好多篇博客,整理出来一个比较清晰的关于几种编码以及字符集的思路. 主要参考:http://blog.sina.com.cn/s/blog_6d ...
- 字符集、字符编码、国际化、本地化简要总结(UNICODE/UTF/ASCII/GB2312/GBK/GB18030)
PS:要转载请注明出处,本人版权所有. PS: 这个只是基于<我自己>的理解, 如果和你的原则及想法相冲突,请谅解,勿喷. 环境说明 普通的linux 和 普通的windows. ...
- 第48篇 字符编码探密--ASCII,UTF8,GBK,Unicode
原文地址:http://blog.laofu.online/2017/08/22/encode-string/ ASCII 的由来 在计算机的“原始社会”,有人想把日常的使用的语言使用计算机来表示, ...
- 初学者对ASCII编码、Unicode编码、UTF-8编码的理解
最早的计算机在设计时采用8个比特(bit)作为一个字节(byte),所以,一个字节能表示的最大的整数就是 255(二进制 11111111=十进制 255),如果要表示更大的整数,就必须用更多的字节. ...
- ASCII码、Unicode码 转中文
ASCII码.Unicode码 转中文 在最近工作中遇到了一些汉字编码转换的处理,可以通过正则表达式及转换字符来实现转成中文 Unicode转换示例 通常为10位编码, 通过digit参数传入 pri ...
- Unicode(UTF&UCS)深度历险
Unicode(UTF&UCS)深度历险 计算机网络诞生后,大家慢慢地发现一个问题:一个字节放不下一个字符了!因为需要交流,本地化的文字需要能够被支持. 最初的字符集使用7bit来存储字符,因 ...
- ASCII字符集。扩展ASCII字符集。Unicode字符集分别支持多少个字符?
ASCII字符集.扩展ASCII字符集.Unicode字符集分别支持多少个字符? 256个字符和 65536个字符
- ASCII码与unicode字符集
问题1:为什么需要字符ASCII码.unicode码等等???它们到底有什么作用? 首先要明白一个事实:在计算机中只能用一系列存储着的0和1,当我们把一个字符存放在计算机时,我们是如何表示常用的字符呢 ...
- ASCII编码和Unicode编码的区别
链接: 计算机只能处理数字,如果要处理文本,就必须先把文本转换为数字才能处理.Unicode把所有语言都统一到一套编码里,这样就不会再有乱码问题了.Unicode标准也在不断发展,但最常用的是用两个字 ...
- SQL Server 中怎么查看一个字母的ascii编码或者Unicode编码(转载)
在sql中怎么查看一个字符的ascii编码或Unicode编码: SELECT ASCII('a') AS [AsciiNum]--字符获取ASCII码 SELECT UNICODE(N'a') AS ...
随机推荐
- cookieUtil
public class CookieUtil { /** * 设置cookie * @param name cookie名字 * @param value cookie值 * @param maxA ...
- 阿里云API网关(7)开发指南-API参考
网关指南: https://help.aliyun.com/document_detail/29487.html?spm=5176.doc48835.6.550.23Oqbl 网关控制台: https ...
- C++中explicit关键字
explicit: 防止隐式转换使用. 隐式转换:不同类型的变量可以互相转换,如将一个整形数值赋值给一个类,ClassXX lei = 4: C++中, 一个参数的构造函数(或者除了第一个参数外其余 ...
- 通过wget工具下载指定文件中的URLs对应的资源并保存到指定的本地目录中去并进行文件完整性与可靠性校验
创建URLs文件在终端输入cd target_directory回车,便把当前文件夹切换到了目标文件夹target_directory,此后创建的文件都会丢它里面在终端输入cat > URLs回 ...
- Maven的作用是什么
现在我们开发的项目基本上都是maven项目,maven项目也是一个项目,类似于javaProject,javaWebProject,就是多了些功能. 那就说说究竟多了什么功能呢. 1 . 帮你下载ja ...
- python/ORM操作详解
一.python/ORM操作详解 ===================增==================== models.UserInfo.objects.create(title='alex ...
- MyBatis(二):Select语句传递参数的集中方案
从别人说的方案中看出,传递参数方案还挺多,不如自己整理下,以便以后使用过程中有个笔记回忆录. 1.传递一个参数的用法: 配置文件 <select id="getById" r ...
- Entry的验证
Entry组件是支持验证输入的合法性的, 比如要求输入数字,你输入了字母就是非法. 实现该功能,需要通过设置validate,validatecommand,invalidcommand选项. 1.首 ...
- X5 Blink下文字自动变大
在X5 Blink中,页面排版时会主动对字体进行放大,会检测页面中的主字体,当某一块的字体在我们的判定规则中,认为字体的字号较小,并且是页面中的主要字体,就会采用主动放大的操作.这显然不是我们想要的. ...
- [LeetCode] Is Graph Bipartite? 是二分图么?
Given an undirected graph, return true if and only if it is bipartite. Recall that a graph is bipart ...