搞懂MySQL InnoDB B+树索引
一.InnoDB索引
InnoDB支持以下几种索引:
- B+树索引
- 全文索引
- 哈希索引
本文将着重介绍B+树索引。其他两个全文索引和哈希索引只是做简单介绍一笔带过。
哈希索引是自适应的,也就是说这个不能人为干预在一张表生成哈希索引,InnoDB会根据这张表的使用情况来自动生成。
全文索引是将存在数据库的整本书的任意内容信息查找出来的技术,InnoDB从1.2.x版本支持。每张表只能有一个全文检索的索引。
B+树索引是传统意义上的索引,B+树索引并不能根据键值找到具体的行数据,B+树索引只能找到行数据锁在的页,然后通过把页读到内存,再在内存中查找到行数据。B+树索引也是最常用的最为频繁使用的索引。
二.什么是B+树
概念
B+树是一种平衡查找树,其实先想想看为什么要用平衡查找树,不用二叉树?普通的二叉树可能因为插入的数据最后变成一个很长的链表,怎么能提高搜索的速度呢?你可以想想,为什么HashMap和ConcurrentHashMap在JDK8的时候,当链表大于8的时候把链表转成红黑树(红黑树也是平衡查找树)。技术思维是想通的,那么答案无非是加快速度,性能咯。
一个B+树有以下特征:
- 有n个子树的中间节点包含n个元素,每个元素不保存数据,只用来索引,所有数据都保存在叶子节点。
- 所有叶子节点包含元素的信息以及指向记录的指针,且叶子节点按关键字自小到大顺序链接。
- 所有的中间节点元素都同时存在于子节点,在子节点元素中是最大(或最小)元素。
那么我们先来看一个B+树的图
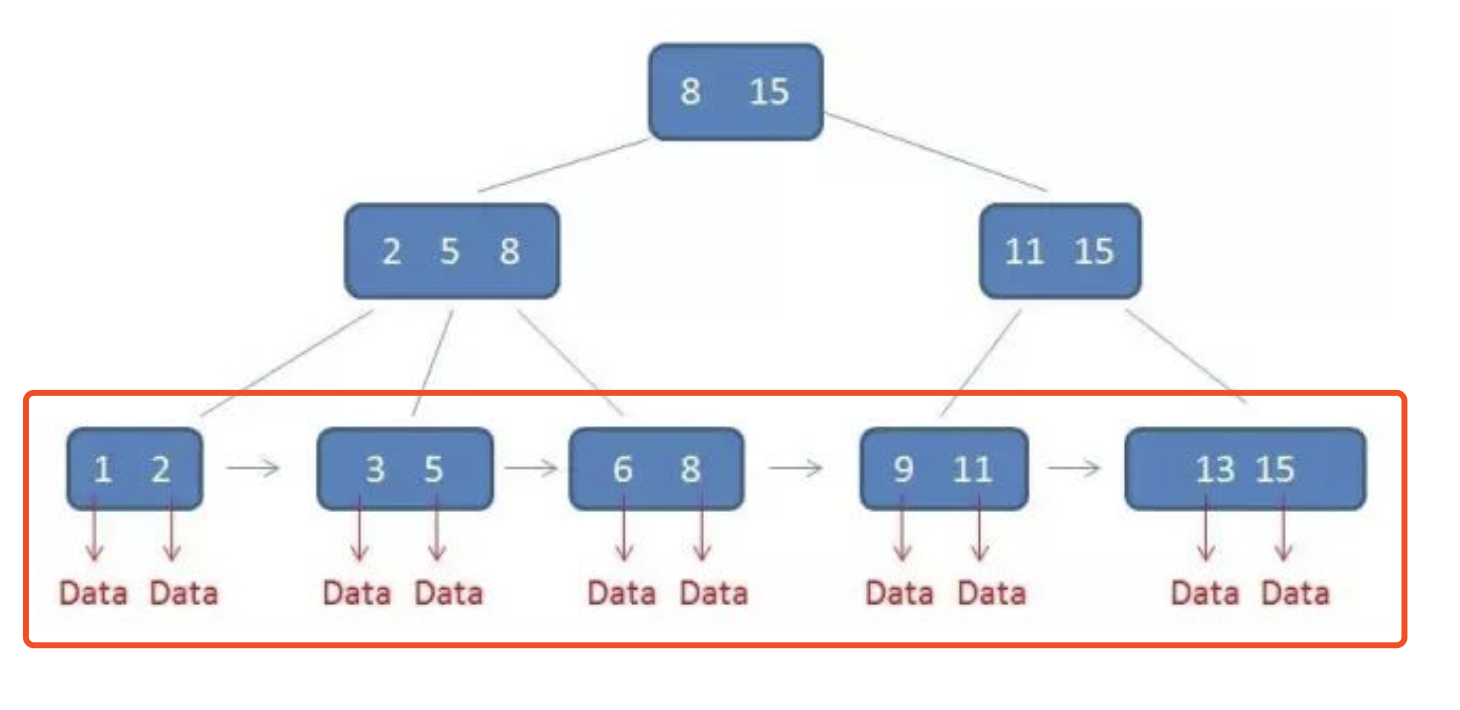
所有的数据都在叶子节点,且每一个叶子节点都带有指向下一个节点的指针,形成了一个有序的链表。为什么要有序呢?其实是为了范围查询。比如说select * from Table where id > 1 and id < 100; 当找到1后,只需顺着节点和指针顺序遍历就可以一次性访问到所有数据节点,极大提到了区间查询效率。是不是范围查询的话hash就搞不定这个事情了?以下为B+树的优势:
- 单一节点存储更多元素,减少IO
- 所有查询都要找到叶子节点,查询稳定
- 所有叶子节点形成有序链表,方便范围查询
一般性情况,数据库的B+树的高度一般在2~4层,这就是说找到某一键值的行记录最多需要2到4次逻辑IO,相当于0.02到0.04s。
三.聚集索引和辅助索引
聚集索引
聚集索引是按表的主键构造的B+树,叶子节点存放的为整张表的行记录数据,每张表只能有一个聚集索引。优化器更倾向采用聚集索引。因为直接就能获取行数据。
请选择自增id来做主键,不要非空UK列。避免大量分页碎片。下面来看一个聚集索引的图:
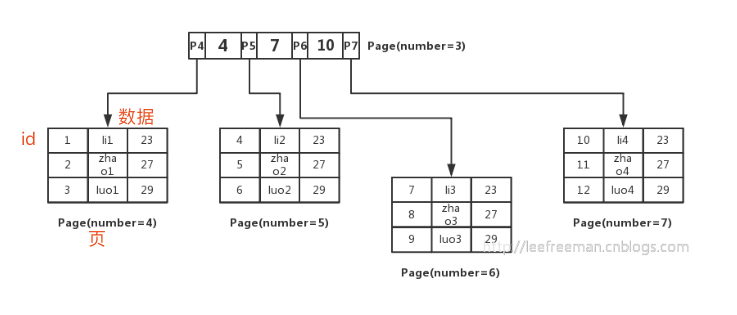
那么很简单了,每个叶子节点,都存有完整的行记录。对于主键的查找速度那是相当的快,美滋滋。
辅助索引
辅助索引也叫非聚集索引,叶子节点除了键值以外还包含了一个bookmark,用来告诉InnoDB在哪里可以找到对应的行数据,InnoDB的辅助索引的bookmark就是相对应行数据的聚集索引键。也就是先获取指向主键索引的主键,然后通过主键索引来找到一个完整的行。如果辅助索引的树和聚集索引的树的高度都是3,如果不是走主键索引走辅助索引的话,那么需要6次逻辑IO访问得到最终的数据页。辅助索引和聚集索引的概念关系图如下:
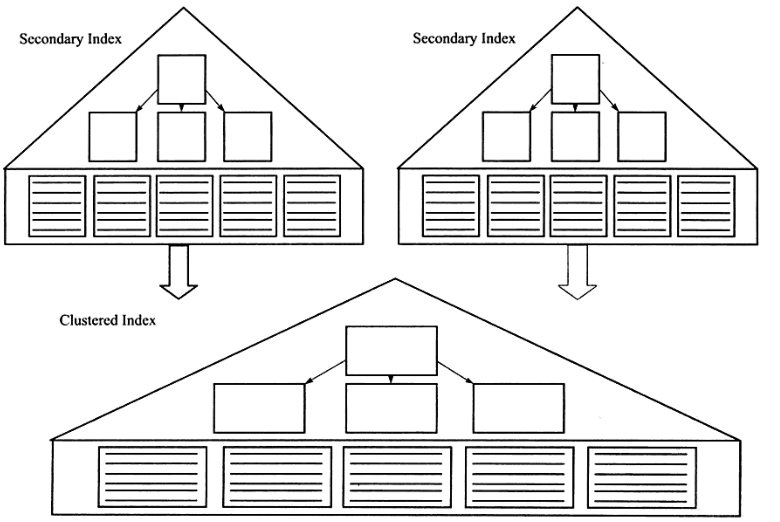
四.索引实战
设计索引
设计索引的时候,无论是组合索引还是普通索引等。一般经验是,选择经常被用来过滤记录的字段,高选择性,高区分性。别把性别字段设计索引,性别属于低选择性的。你可以选择名字嘛,你好我大名叫苗嘉杏:)
知道加索引快,但是也别乱加索引,插入以及更新索引的操作InnoDB都会维护B+树的,多加很多索引只会导致效率降低!
不要用重复的索引,比如有个联合索引是a,b,你又整个a列的普通索引。那不是搞事么?
不要在索引上用函数和like
一颗聚集索引B+树可以放多少行数据?
这里我们先假设B+树高为2,即存在一个根节点和若干个叶子节点,那么这棵B+树的存放总记录数为:根节点指针数*单个叶子节点记录行数。假设一行记录的数据大小为1k,那么单个叶子节点(页)中的记录数=16K/1K=16。
那么现在我们需要计算出非叶子节点能存放多少指针,我们假设主键ID为bigint类型,长度为8字节,而指针大小在InnoDB源码中设置为6字节,这样一共14字节,我们一个页中能存放多少这样的单元,其实就代表有多少指针,即16kb/14b=1170。那么可以算出一棵高度为2的B+树,大概能存放1170*16=18720条这样的数据记录。
根据同样的原理我们可以算出一个高度为3的B+树大概可以存放:1170*1170*16=21902400行数据。所以在InnoDB中B+树高度一般为1-3层,它就能满足千万级的数据存储。在查找数据时一次页的查找代表一次IO,所以通过主键索引查询通常只需要1-3次逻辑IO操作即可查找到数据。
Cardinality值
如何判断一个索引建立的是否好呢?可以用show index from指令查看Cardinality值,这个值是一个预估值,而不是一个准确值。每次对Cardinality值的统计都是随机取8个叶子节点得到的。
对于innodb来说,达到以下2点就会重新计算cardinality
- 如果表中1/16的数据发生变化
- 如果stat_modified_counter>200 000 0000
实际应用中,(Cardinality/行数)应该尽量接近1。如果非常小则要考虑是否需要此索引。实战一下,比如有一张表,我们来show index一下
mysql> show index from Order;
+---------+------------+------------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment |
+---------+------------+------------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| Order | 0 | PRIMARY | 1 | id | A | 99552 | NULL | NULL | | BTREE | | |
| Order | 1 | IDX_orderId | 1 | orderId | A | 96697 | NULL | NULL | | BTREE | | |
| Order | 1 | IDX_productId | 1 | productId | A | 52 | NULL | NULL | | BTREE | | |
+---------+------------+------------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
3 rows in set (0.00 sec)
那么可以看到IDX_productId这个索引的Cardinality比较低。
需要强制刷新Cardinality值的话可以用:
analyze local table xxx;
参考:
MySQL5.1参考手册 - http://dev.mysql.com/doc/refman/5.1/zh/index.html
《MySQL技术内幕》
《小灰漫画》
https://www.cnblogs.com/leefreeman/p/8315844.html
http://blog.codinglabs.org/articles/theory-of-mysql-index.html
搞懂MySQL InnoDB B+树索引的更多相关文章
- 搞懂MySQL(各种)索引类型及其区别
索引的概念介绍: 1.聚集索引 聚集索引:指索引项的排序方式和表中数据记录排序方式一致的索引 也就是说聚集索引的顺序就是数据的物理存储顺序.它会根据聚集索引键的顺序来存储表中的数据,即对表的数据按索 ...
- 搞懂MySQL InnoDB事务ACID实现原理
前言 说到数据库事务,想到的就是要么都做修改,要么都不做.或者是ACID的概念.其实事务的本质就是锁和并发和重做日志的结合体.那么,这一篇主要讲一下InnoDB中的事务到底是如何实现ACID的. 原子 ...
- 一文快速搞懂MySQL InnoDB事务ACID实现原理(转)
这一篇主要讲一下 InnoDB 中的事务到底是如何实现 ACID 的: 原子性(atomicity) 一致性(consistency) 隔离性(isolation) 持久性(durability) 隔 ...
- MySQL的B+树索引和hash索引的区别
简述一下索引: 索引是数据库表中一列或多列的值进行排序的一种数据结构:索引分为聚集索引和非聚集索引,聚集索引查询类似书的目录,快速定位查找的数据,非聚集索引查询一般需要再次回表查询一次,如果不使用索引 ...
- SQL优化 MySQL版 - B树索引详讲
SQL优化 MySQL版 - -B树索引详讲 作者:Stanley 罗昊 [转载请注明出处和署名,谢谢!] 为什么要进行SQL优化呢?很显然,当我们去写sql语句时: 1会发现性能低 2.执行时间太 ...
- MySQL InnoDB表和索引之聚簇索引与第二索引
MySQL InnoDB表和索引之聚簇索引与第二索引 By:授客QQ:1033553122 每个InnoDB表都有一个称之为聚簇索引(clustered index)的特殊索引,存储记录行数据.通常, ...
- 彻底搞懂MySQL为什么要使用B+树索引
目录 MySQL的存储结构 表存储结构 B+树索引结构 B+树页节点结构 为什么要用B+树索引 二叉树 多叉树 B树 B+树 搞懂这个问题之前,我们首先来看一下,MySQL表的存储结构 MySQL的存 ...
- 一本彻底搞懂MySQL索引优化EXPLAIN百科全书
1.MySQL逻辑架构 日常在CURD的过程中,都避免不了跟数据库打交道,大多数业务都离不开数据库表的设计和SQL的编写,那如何让你编写的SQL语句性能更优呢? 先来整体看下MySQL逻辑架构图: M ...
- 一文搞懂mysql索引底层逻辑,干货满满!
一.什么是索引 在mysql中,索引是一种特殊的数据库结构,由数据表中的一列或多列组合而成,可以用来快速查询数据表中有某一特定值的记录.通过索引,查询数据时不用读完记录的所有信息,而只是查询索引列即可 ...
随机推荐
- 手游热更新方案--Unity3D下的CsToLua技术
WeTest 导读 CsToLua工具将客户端 C#源码自动转换为Lua,实现热更新,本文以麻将项目为例介绍客户端技术细节. 麻将项目架构 其中ChinaMahjong-CSLua为C#工程,实现麻将 ...
- js获取数组中最大值和最小值
var max = Math.max.apply(null, 数组); 获取最大值 var min = Math.min.apply(null, 数组);获取最小值 一句话获取数组中最大的数,最小数
- MySQL安装及环境搭建
一.Windows 上安装 MySQL Windows 上安装 MySQL 相对简单,最新版本下载地址: 官网:https://dev.mysql.com/downloads/mysql/ 下载步骤: ...
- 处女作《Web全栈开发进阶之路》出版了!
书中源码下载地址:https://github.com/qinggee/WebAdvanced 01. 当初决定写博客的原因非常的纯洁:只要每个月写上 4 篇以上博客,月底的绩效奖金就多 500 块. ...
- vs中开发web站点使IIS Express支持局域网连接
vs中开发web站点使IIS Express支持局域网连接 在开发webapi的时候,客户端设备都会使用局域网的地址访问webapi,有时候需要调试api.这个时候就需要使用一些技巧了,这里我记录了我 ...
- C# Memory Cache 踩坑记录
背景 前些天公司服务器数据库访问量偏高,运维人员收到告警推送,安排我团队小伙伴排查原因. 我们发现原来系统定期会跑一个回归测试,该测运行的任务较多,每处理一条任务都会到数据库中取相关数据,高速地回归测 ...
- 利用Asp.Net Core的MiddleWare思想处理复杂业务流程
最近利用Asp.Net Core 的MiddleWare思想对公司的古老代码进行重构,在这里把我的设计思路分享出来,希望对大家处理复杂的流程业务能有所帮助. 背景 一个流程初始化接口,接口中根据传入的 ...
- 论文学习-深度学习目标检测2014至201901综述-Deep Learning for Generic Object Detection A Survey
目录 写在前面 目标检测任务与挑战 目标检测方法汇总 基础子问题 基于DCNN的特征表示 主干网络(network backbone) Methods For Improving Object Rep ...
- SQL Server内幕之数据页
数据页是包含已添加到数据库表中的用户数据的结构. 如前所述, 数据页有三种, 每个都以不同的格式存储数据. SQL server 有行内数据页.行溢出数据页和 LOB 数据页. 与 SQL serve ...
- C# 23种设计模式
目录 0).简单工厂模式 1).工厂方法模式 2).抽象工厂模式 3).单例模式 4).构建者模式 5).原型模式 6).适配器模式 7).修饰者模式 8).代理模式 9).外观模式 10).桥接模式 ...