机器学习--最邻近规则分类KNN算法
理论学习:

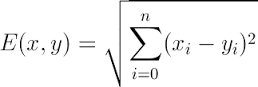
from sklearn import neighbors
from sklearn import datasets knn = neighbors.KNeighborsClassifier() iris = datasets.load_iris() print(iris) knn.fit(iris.data, iris.target) # 建模,两个参数:二维的特征值矩阵、一维的每一个实例所对应的对象 predictedLabel = knn.predict([[0.1, 0.2, 0.3, 0.4]]) print(predictedLabel)
2、不调用任何库来实现knn算法,其中使用到的数据集是sklearn自带的iris数据集
# 不调用任何库来实现knn算法 import csv
import random
import math
import operator # 将数据集装载到Python里面
# filename:数据集存放的文件
# split:以此参数为界限将数据集分为trainingSet训练集和testSet测试集
def loadDataset(filename, split, trainingSet=[], testSet=[]):
with open(filename, 'r') as csvfile: # 打开文件
lines = csv.reader(csvfile) # 读取文件的所有行
dataset = list(lines) # 文件内容转换成list结构 # 将数据集分为两部分
for x in range(len(dataset) - 1):
for y in range(4):
dataset[x][y] = float(dataset[x][y])
# 随机数小于split放入训练集,大于就放入测试集
if random.random() < split:
trainingSet.append(dataset[x])
else:
testSet.append(dataset[x]) # 计算两个实例之间的欧式距离
# instance1、instance2是两个实例
# length是实例的维数
def euclideanDistance(instance1, instance2, length):
distance = 0 # 设置初始值为0 # 计算所有维度的差的平方和
for x in range(length):
distance += pow((instance1[x] - instance2[x]), 2)
return math.sqrt(distance) # 测试集中的一个实例到训练集的距离最近的k个实例
# trainingSet:训练集
# testInstance:测试集实例
# k:距离最近的个数
def getNeighbors(trainingSet, testInstance, k):
distances = []
length = len(testInstance) - 1
for x in range(len(trainingSet)):
dist = euclideanDistance(testInstance, trainingSet[x], length)
distances.append((trainingSet[x], dist))
distances.sort(key=operator.itemgetter(1))
neighbors = []
for x in range(k):
neighbors.append(distances[x][0])
return neighbors def getResponse(neighbors):
"""
得到
:param neighbors:附近的实例
:return:得票最多的类别情况 """
classVotes = {}
for x in range(len(neighbors)):
response = neighbors[x][-1]
if response in classVotes:
classVotes[response] += 1
else:
classVotes[response] = 1
sortedVotes = sorted(classVotes.items(), key=operator.itemgetter(1), reverse=True) # classVotes.iteritems()
return sortedVotes[0][0] def getAccuracy(testSet, predictions):
"""
得到预测的正确率
:param testSet:测试集
:param predictions: 预测结果
:return: 预测的正确率 """
correct = 0
for x in range(len(testSet)):
if testSet[x][-1] == predictions[x]:
correct += 1
return (correct/float(len(testSet))) * 100.0 def main():
""" :return:
"""
trainingSet = []
testSet = []
split = 0.67 # 把2/3的数据作为训练集,1/3为测试集
loadDataset(r'irisdata.txt', split, trainingSet, testSet)
print('Train set: ' + repr(len(trainingSet)))
print('Test set: ' + repr(len(testSet))) predictions = []
k = 3
for x in range(len(testSet)):
neighbors = getNeighbors(trainingSet, testSet[x], k) # 找到各个测试集实例最近的邻居
result = getResponse(neighbors)
predictions.append(result)
print('> predicted=' + repr(result) + ',actual=' + repr(testSet[x][-1]))
accuracy = getAccuracy(testSet, predictions)
print('Accuracy: ' + repr(accuracy) + '%') if __name__ == '__main__':
main()
机器学习--最邻近规则分类KNN算法的更多相关文章
- 最邻近规则分类KNN算法
例子: 求未知电影属于什么类型: 算法介绍: 步骤: 为了判断未知实例的类别,以所有已知类别的实例作为参照 选择参数K 计算未知实例与所有已知实例的距离 选择最近K个已 ...
- 机器学习算法 - 最近邻规则分类KNN
上节介绍了机器学习的决策树算法,它属于分类算法,本节我们介绍机器学习的另外一种分类算法:最近邻规则分类KNN,书名为k-近邻算法. 它的工作原理是:将预测的目标数据分别跟样本进行比较,得到一组距离的数 ...
- kNN(K-Nearest Neighbor)最邻近规则分类
KNN最邻近规则,主要应用领域是对未知事物的识别,即推断未知事物属于哪一类,推断思想是,基于欧几里得定理,推断未知事物的特征和哪一类已知事物的的特征最接近: K近期邻(k-Nearest Neighb ...
- kNN(K-Nearest Neighbor)最邻近规则分类(转)
KNN最邻近规则,主要应用领域是对未知事物的识别,即判断未知事物属于哪一类,判断思想是,基于欧几里得定理,判断未知事物的特征和哪一类已知事物的的特征最接近: K最近邻(k-Nearest Neighb ...
- 机器学习实战(笔记)------------KNN算法
1.KNN算法 KNN算法即K-临近算法,采用测量不同特征值之间的距离的方法进行分类. 以二维情况举例: 假设一条样本含有两个特征.将这两种特征进行数值化,我们就可以假设这两种特种分别 ...
- 机器学习(一)之KNN算法
knn算法原理 ①.计算机将计算所有的点和该点的距离 ②.选出最近的k个点 ③.比较在选择的几个点中那个类的个数多就将该点分到那个类中 KNN算法的特点: knn算法的优点:精度高,对异常值不敏感,无 ...
- 最邻近规则分类(K-Nearest Neighbor)KNN算法
自写代码: # Author Chenglong Qian from numpy import * #科学计算模块 import operator #运算符模块 def createDaraSet( ...
- 4.2 最邻近规则分类(K-Nearest Neighbor)KNN算法应用
1 数据集介绍: 虹膜 150个实例 萼片长度,萼片宽度,花瓣长度,花瓣宽度 (sepal length, sepal width, petal length and petal wi ...
- python实现简单分类knn算法
原理:计算当前点(无label,一般为测试集)和其他每个点(有label,一般为训练集)的距离并升序排序,选取k个最小距离的点,根据这k个点对应的类别进行投票,票数最多的类别的即为该点所对应的类别.代 ...
随机推荐
- EF事务封装
public class EFTransaction:ITransaction { DbContextTransaction originalTransaction = null; MyDbConte ...
- hadoop job -kill 与 yarn application -kii(作业卡了或作业重复提交或MapReduce任务运行到running job卡住)
问题详情 解决办法 [hadoop@master ~]$ hadoop job -kill job_1493782088693_0001 DEPRECATED: Use of this script ...
- 工作的时候用到spring返回xml view查到此文章亲测可用
spring mvc就是好,特别是rest风格的话,一个 org.springframework.web.servlet.view.ContentNegotiatingViewResolver就可以根 ...
- day35-hibernate映射 05-Hibernate的一级缓存:快照区
SessionImpl里面有很多的Java集合,很多java集合才构成了一级缓存.一级缓存里面有一个非常特殊的区域叫做快照区.SessionImpl实现了Session接口,有很多Java集合(包括M ...
- [Elasticsearch2.x] 多字段搜索 (一) - 多个及单个查询字符串 <译>
多字段搜索(Multifield Search) 本文翻译自官方指南的Multifield Search一章. 查询很少是只拥有一个match查询子句的查询.我们经常需要对一个或者多个字段使用相同或者 ...
- GitHub Blog创建以及本地管理(转)
GitHub Blog创建以及本地管理 创建 注册GitHub账户 首页点击新建仓库 New repository repository name必须为 Owner.github.io EX:我的 ...
- c类库,委托,var ,运算符 is 和 as 。
类库(Class Library) 格式 .dll 文件 类库 就是类的仓库 c#代码被编译过以后的文件,不可阅读,不可修改,只能调用. 类库是一个综合性的面向对象的可重用类型集合,这些类 ...
- Netty学习大纲
1.BIO.NIO和AIO2.Netty 的各大组件3.Netty的线程模型4.TCP 粘包/拆包的原因及解决方法5.了解哪几种序列化协议?包括使用场景和如何去选择6.Netty的零拷贝实现7.Net ...
- JQuery UI Draggable插件使用说明文档
JQuery UI Draggable插件用来使选中的元素可以通过鼠标拖动.Draggable的元素受css: ui-draggable影响, 拖动过程中的css: ui-draggable-drag ...
- java Servlet学习笔记(一)
访问机制 (https://pan.baidu.com/share/link?shareid=3055126243&uk=3355579678&fid=1073713310362078 ...