JSTree下的模糊查询算法——树结构数据层次遍历和递归分治地深入应用
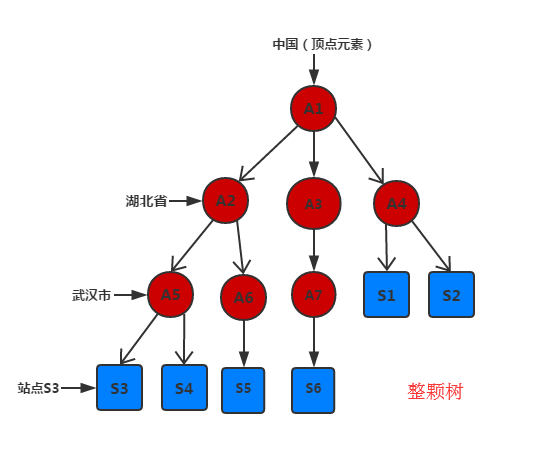
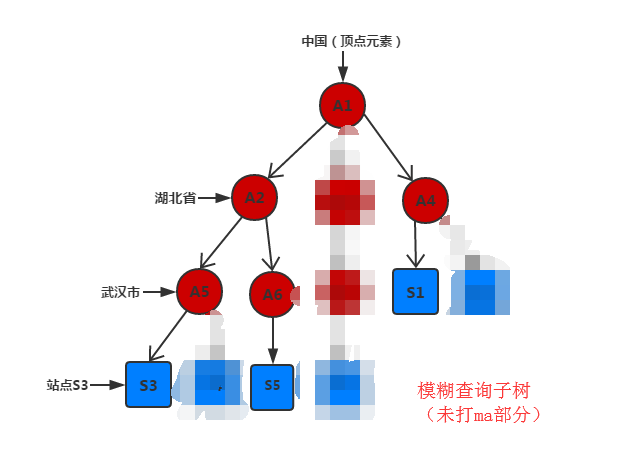
A表示区域节点,S表示站点结点
问题描述:现有jstree包含左图中的所有结点信息(包含区域结点和站点结点),需要做到输入站点名称模糊查询,显示查询子树结果如右图
解决策略:
1、先模糊查询所得站点所在区域结点A5,A6,A4,根据这些从下往上搜索所有子树的区域结点(主义表述,是区域结点),存至set集合(避免重复放入)
2、找出set集合中的最高点A1(最高点的父节点为空),查询结点信息放入jsonobject,从上往下搜索子树中A1所有孩子结点(A2,A4),递归遍历A2,A4的孩子结点,存至孩子结点数组,
遇到区域结点没有孩子结点则表示其到了最底层区域结点(A5,A6,A4),将其对应区域结点信息存至其孩子结点数组
3、两步递归操作,设值注入最高点结点信息,最终得到包含整棵子树的所有结点信息。返回给页面
if (name != null && !"".equals(name)) {
name = new String(name.getBytes("iso-8859-1"),"utf-8"); //字符串转码
StringBuffer searchValue = new StringBuffer();
searchValue.append("%").append(name).append("%"); //模糊查询格式化
List<StationBase> stationBaseList = stationBaseService.findStationBaseByName(searchValue.toString()); //根据站点名称模糊查找站点集合
List<String> stationCodes = new ArrayList<>(); //装填上面模糊查询中所负责的站点code,
List<Integer> areaIds_bottom = new ArrayList<>(); //存放上面站点所在区域id,即最底层的区域结点id
Set<Integer> areaIdSet = new HashSet<Integer>(); //存放子树中所有区域结点的id,避免重复用set集合
for (StationBase stationBase:stationBaseList) {
if(areaIds.contains(stationBase.getArea().getId())){ //areaIds表示用户所负责的所有区域站点的id,即整颗树区域节点id
stationCodes.add(stationBase.getStationCode());
areaIds_bottom.add(stationBase.getArea().getId());
areaIdSet.add(stationBase.getArea().getId());
}
}
areaIdSet = getAllAreaIdBySearch(areaIdSet,areaIds_bottom); //设值注入获取子树中所有区域结点的id
//找出最高点,装入集合
JSONObject jo_top = new JSONObject(); //最高点结点
for(Integer area_Id : areaIdSet){
if(area_Id!=null){
List<Integer> area_Ids = new ArrayList<>(); //为了符合传入的是List集合
area_Ids.add(area_Id);
if(stationBaseService.findParentIdsByAreaIds(area_Ids).get(0)==null) { //找出最高点,并装填信息
Area area = areaService.findAllArea(area_Id).get(0);
JSONObject state = new JSONObject();
jo_top.put("id", areaPrefix + area.getId());
jo_top.put("text", area.getArea());
jo_top.put("type", "areatype");
state.put("opened", true);
jo_top.put("state", state);
jo_top = findChainArea(jo_top, areaIdSet, areaPrefix, stationCodes); //设值注入获取包含根结点的子树
break;
}
}
}
jsonArray.add(jo_top); //存入json数组
return jsonArray;
}
/**
* 递归查找包括最底层areaIdSet一直往上的所有areaId,避免重复用Set集合
* @param areaIdSet 最底层到最高层所有层的areaId集合
* @param areaId_row 根据用户输入站点名所查的最底层areaId集合
* @return
*/
protected Set<Integer> getAllAreaIdBySearch(Set<Integer> areaIdSet,List<Integer> areaId_row){
if(areaId_row!=null && areaId_row.size()>0 && areaId_row.get(0)!=null){ //areaId_row写在与前面,避免为空先做判断,直到查到ParentId为空结束递归
List<Integer> areaParentIdList = stationBaseService.findParentIdsByAreaIds(areaId_row); //获取当前areaId_row所有的parentId
for (Integer areaId:areaParentIdList){
areaIdSet.add(areaId); //使用set集合对所搜集areaId进行去重
}
return getAllAreaIdBySearch(areaIdSet,areaParentIdList); //递归访问上一层区域结点
}
return areaIdSet;
} /**
* 递归查找从最高点jo往下一层层遍历,将遍历结点存至孩子结点数组中
* @param jo 最高点
* @param areaIdSet 整颗树区域id
* @param areaPrefix 区域id前缀
* @param stationCodes 子树所有站点code
* @return
*/
protected JSONObject findChainArea(JSONObject jo,Set<Integer> areaIdSet,String areaPrefix,List<String> stationCodes){
List<Integer> childIds = stationBaseService.findIdsByParent(Integer.parseInt(jo.get("id").toString().split("_")[1]));
if(childIds!=null && childIds.size()>0 && childIds.get(0)!=null){ //有子区域节点,非叶节点
//查询子区域节点信息,添加到jo中,areaIdSet中对应的id
JSONArray areaChildArray = new JSONArray(); //存放该结点在对应子树中的孩子结点数组
for (Integer childId:childIds) {
if(areaIdSet.contains(childId)){ //属于子树中结点便添加到孩子结点数组中
Area area = areaService.findAllArea(childId).get(0);
JSONObject jo_child = new JSONObject();
JSONObject state = new JSONObject();
jo_child.put("id",areaPrefix+area.getId());
jo_child.put("text",area.getArea());
jo_child.put("type","areatype");
state.put("opened", true);
jo_child.put("state",state);
jo_child = findChainArea(jo_child,areaIdSet,areaPrefix,stationCodes);
areaChildArray.add(jo_child);
}
}
jo.put("children",areaChildArray);
}else{ //无子区域,叶节点,添加站点信息
List<StationBase> stationBaseList = stationBaseService.findByAreaId(Integer.parseInt(jo.get("id").toString().split("_")[1]));
JSONArray stationArray = new JSONArray(); //该站点下的所有站点
for (StationBase stationBase : stationBaseList){
if(stationCodes.contains(stationBase.getStationCode())){
JSONObject stationObj = new JSONObject();
stationObj.put("id", "s_" + stationBase.getStationCode());
stationObj.put("text", stationBase.getStationName());
stationObj.put("type", "stationInfo");
stationObj.put("children", false);
stationArray.add(stationObj);
}
}
jo.put("children",stationArray);
}
return jo;
}
JSTree下的模糊查询算法——树结构数据层次遍历和递归分治地深入应用的更多相关文章
- 算法:二叉树的层次遍历(递归实现+非递归实现,lua)
二叉树知识参考:深入学习二叉树(一) 二叉树基础 递归实现层次遍历算法参考:[面经]用递归方法对二叉树进行层次遍历 && 二叉树深度 上面第一篇基础写得不错,不了解二叉树的值得一看. ...
- select 下拉模糊查询
http://ivaynberg.github.io/select2/ https://github.com/ https://github.com/ivaynberg.github.io/selec ...
- JavaScript根据Json数据来做的模糊查询功能
类似于百度搜索框的模糊查找功能 需要有有已知数据,实现搜索框输入字符,然后Js进行匹配,然后可以通过鼠标点击显示的内容,把内容显示在搜索框中 当然了,正则只是很简单的字符匹配,不具备多么复杂的判断 & ...
- ElementUI Tree控件在懒加载模式下的重新加载和模糊查询
之所以使用懒加载是为了提高性能,而且只有在懒加载模式下默认会给所有显示节点设置展开按钮.leaf也可以做到,但是要操作数据比较麻烦. 要实现懒加载模式下的模糊查询以及重新加载必须要使用data与laz ...
- Mysql模糊查询like效率,以及更高效的写法
在使用msyql进行模糊查询的时候,很自然的会用到like语句,通常情况下,在数据量小的时候,不容易看出查询的效率,但在数据量达到百万级,千万级的时候,查询的效率就很容易显现出来.这个时候查询的效率就 ...
- django ORM 增删改查 模糊查询 字段类型 及参数等
ORM 相关 #sql中的表 #创建表: CREATE TABLE employee( id INT PRIMARY KEY auto_increment , name VARCHAR (), gen ...
- 【转】【MySQL】Mysql模糊查询like提速优化
在使用msyql进行模糊查询的时候,很自然的会用到like语句,通常情况下,在数据量小的时候,不容易看出查询的效率,但在数据量达到百万级,千万级的时候,查询的效率就很容易显现出来.这个时候查询的效率就 ...
- oracle 语句之对数据库的表名就行模糊查询,对查询结果进行遍历,依次获取每个表名结果中的每个字段(存储过程)
语句的执行环境是plsql的sql窗口, 语句的目的是从整个数据库中的所有表判断 不等于某个字段的记录数 . 代码如下: declare s_sql clob:=''; -- 声明一个变量,该变量用于 ...
- 前端js模糊搜索(模糊查询)
1.html结构: <label for="searchShop" class="clear pos-a" style="top:17px;&q ...
随机推荐
- mysql事务锁表
-- 查看被锁住的SELECT * FROM INFORMATION_SCHEMA.INNODB_LOCKS; -- 等待锁定SELECT * FROM INFORMATION_SCHEMA.INNO ...
- springBoot集成web service
转载大神: https://blog.csdn.net/u011410529/article/details/68063541?winzoom=1 https://blog.csdn.net/nr00 ...
- mybatis批量处理sql
转载大神 https://www.cnblogs.com/xujingyang/p/8301130.html
- 物理机和虚拟机互相可以ping通,还是无法连接
关闭防火墙服务 CentOS # systemctl stop firewalld.service Debian # iptables -F Ubuntu # ufw disable 安装SSH服务 ...
- 安全性测试入门 (五):Insecure CAPTCHA 验证码绕过
本篇继续对于安全性测试话题,结合DVWA进行研习. Insecure Captcha不安全验证码 1. 验证码到底是怎么一回事 这个Captcha狭义而言就是谷歌提供的一种用户验证服务,全称为:Com ...
- android 开发-(Contextual Menu)上下文菜单的实现
在android3.0以后,安卓设备不在提供物理的菜单按键,同时,android应用提供了另外的菜单实现机制,来替代之前的菜单创建方式.安卓设备中,平常可以使用长按住某个内容弹出菜单选项.这就是我们需 ...
- SpringBoot | 第十六章:web应用开发
前言 前面讲了这么多直接,都没有涉及到前端web和后端交互的部分.因为作者所在公司是采用前后端分离方式进行web项目开发了.所以都是后端提供api接口,前端根据api文档或者服务自行调用的.后台也有读 ...
- P1681 最大正方形 Iand II
题目描述 在一个n*m的只包含0和1的矩阵里找出一个不包含0的最大正方形,输出边长. 输入输出格式 输入格式: 输入文件第一行为两个整数n,m(1<=n,m<=100),接下来n行,每行m ...
- 几百道常见Java初中级面试题
注: 有的面试题是我面试的时候遇到的,有的是偶然看见的,还有的是朋友提供的, 稍作整理,以供参考.大部分的应该都是这些了,包含了基础,以及相对深入一点点的东西. JAVA面试题集 基础知识: ...
- 【踩坑】vue 无法让后台保存 session
今天在调试 iblog 客户端时,发现登录后进行增加.删除.更新操作时都提示还没有登录. 此问题曾经在用 ajax 调试时出现过,解决办法是,在请求时带上 creditials: true ,即让发出 ...