MySQL进阶实战5,为什么查询速度会慢
一、先了解一下MySQL查询的执行过程
MySQL在查询时,它是由很多子任务组成的,每个子任务都会消耗一定的时间,如果要想优化查询,实际上要优化其子任务,可以消除一些子任务、减少子任务的执行次数、让子任务执行的更快。
MySQL查询的执行过程:从客户端到服务器、然后在服务器进行解析、生成执行计划、执行、返回结果给客户端。
执行是最重要的阶段,包括调用存储引擎检索数据、调用后的数据处理、排序、分组等;
查询需要在不同的地方花费时间,包括网络、CPU计算、生成统计信息、生成执行计划、锁等待等,尤其是向底层存储引擎检索数据的调用操作,这些调用需要在内存操作、CPU操作和内存不足时导致的IO操作上花费时间。根据存储引擎不同,可能还会产生大量的上下文切换以及系统调用。
不必要的额外操作、不必要的重复操作、某些操作执行的太慢都是查询慢的原因,优化查询的目的就是减少和消除这些操作所花费的时间。
二、是否查询了不需要的数据
有些查询会查询很多不需要的数据,查询之后,程序中并未使用,这样不但会给MySQL服务器带来额外的负担,还会增加网络开销,也会消耗应用服务器的CPU和内存资源,简而言之,吃多少拿多少。
千万不要有“把数据都查出来,用Java代码过滤”的想法。
禁止使用select * 进行查询。
三、衡量查询开销的几个重要指标
1、响应时间
响应时间可以分为服务时间和排序时间。
- 服务时间指数据库处理这个查询真正花费的时间;
- 排队时间指服务器因为等待某些资源而没有真正执行查询的时间,比如等待IO操作、等待行锁。
2、扫描的行数和返回的行数
较短的行的访问速度更快,内存中的行比磁盘中的行的访问速度要快得多。
理想情况下扫描的行数和返回的行数是相同的。但这种情况并不多见,比如关联查询的时候,服务器必须扫描更多的行才能得到结果,因此,越多的表关联,性能越低。
3、扫描的行数和访问类型
MySQL可以通过多种方式查询并返回结果集,速度从慢到快,扫描的行数由多到少,依次为全表扫描、索引扫描、范围扫描、唯一索引扫描、常数引用。
最常用的优化方式是为查询增加一个合适的索引,索引可以让MySQL以最高效、扫描行数最少的方式找到需要的记录。
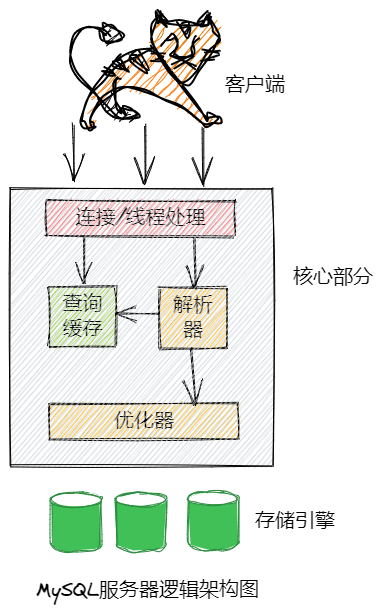
4、一般可以通过explain的Extra列查看查询的优劣
一般MySQL能够使用以下三种方式应用where条件,从好到坏依次为:
- 在索引中使用where条件过滤不匹配的记录,这是在存储引擎层完成的;
- 使用索引覆盖扫描,也就是Extra中出现
Using index,直接从索引中过滤不需要的记录并返回命中的结果,这是在MySQL服务器层完成的,无须再回表查询记录; - Extra中出现
Using where,这是在MySQL服务器层完成的,MySQL需要先从数据表读取记录,然后过滤。
Extra中出现Using where时,可以通过如下方式优化:
- 使用索引覆盖扫描,把所有需要的列都放到索引中,这样就不用回表查询了;
- 改变表结构,比如使用汇总表;
- 重写sql,让MySQL优化器能够以更优化的方式执行这个sql;
MySQL进阶实战5,为什么查询速度会慢的更多相关文章
- 提高MYSQL百万条数据的查询速度
提高MYSQL百万条数据的查询速度 1.对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引. 2.应尽量避免在 where 子句中对字段进行 nul ...
- mysql进阶(九)多表查询
MySQL多表查询 一 使用SELECT子句进行多表查询 SELECT 字段名 FROM 表1,表2 - WHERE 表1.字段 = 表2.字段 AND 其它查询条件 SELECT a.id,a.na ...
- 小白也能看懂的mySQL进阶【单表查询】
目录 1.查询基础 SELECT语句基础 列的查询 为列设定别名 常数的查询 过滤表中重复数据 根据WHERE语句来选择记录 注释的书写方法 算术运算符和比较运算符 算术运算符 需要注意NULL 比较 ...
- MySQL进阶篇(03):合理的使用索引结构和查询
本文源码:GitHub·点这里 || GitEE·点这里 一.高性能索引 1.查询性能问题 在MySQL使用的过程中,所谓的性能问题,在大部分的场景下都是指查询的性能,导致查询缓慢的根本原因是数据量的 ...
- mysql处理海量数据时的一些优化查询速度方法
最近一段时间由于工作需要,开始关注针对Mysql数据库的select查询语句的相关优化方法. 由于在参与的实际项目中发现当mysql表的数据量达到百万级时,普通SQL查询效率呈直线下降,而且如果w ...
- mysql处理大数据量的查询速度究竟有多快和能优化到什么程度
mysql处理大数据量的查询速度究竟有多快和能优化到什么程度 深圳-ftx(1433725026) 18:10:49 mysql有没有排名函数啊 横瓜(601069289) 18:13:06 无 ...
- 相似度到大数据查找之Mysql 文章匹配的一些思路与提高查询速度
文章相关度匹配的一些思路---"压缩"预料库,即提取用特征词或词频,量化后以“列向量”形式保存到数据库:按前N组词拼为向量组供查询使用,即组合为1到N字的组合,量化后以“行向量”形 ...
- (已实现)相似度到大数据查找之Mysql 文章匹配的一些思路与提高查询速度
需求,最近实现了文章的原创度检测功能,处理思路一是分词之后做搜索引擎匹配飘红,另一方面是量化词组,按文章.段落.句子做数据库查询,功能基本满足实际需求. 接下来,还需要在海量大数据中快速的查找到与一句 ...
- 提高MySQL查询速度
参考百度知道 关于mysql处理百万级以上的数据时如何提高其查询速度的方法 最近一段时间由于工作需要,开始关注针对Mysql数据库的select查询语句的相关优化方法. 由于在参与的实际项目中发现当m ...
- 使用Apache Spark 对 mysql 调优 查询速度提升10倍以上
在这篇文章中我们将讨论如何利用 Apache Spark 来提升 MySQL 的查询性能. 介绍 在我的前一篇文章Apache Spark with MySQL 中介绍了如何利用 Apache Spa ...
随机推荐
- 1 Java内存区域管理
目录 1 关于自动内存管理 2 运行时数据区域 2.1 程序计数器 2.2 虚拟机栈 2.2.1 局部变量表 2.2.2 操作数栈 2.3 本地方法栈 2.4 堆 2.5 方法区 2.5.1 运行时常 ...
- [Golang] GO 语言工作环境的基本概念
1. GOPATH 和 GOROOT(环境变量) 1. GOROOT go 编译器.标准库等安装的地方,所有我们写的代码其实都是文本文件而已,需要编译器等工具将其加工成可执行文件或者库文件才能使用,每 ...
- Kubernetes 监控--PromQL
Prometheus 通过指标名称(metrics name)以及对应的一组标签(label)唯一定义一条时间序列.指标名称反映了监控样本的基本标识,而 label 则在这个基本特征上为采集到的数据提 ...
- Elasticsearch:Cluster备份 Snapshot及Restore API
Elasticsearch提供了replica解决方案,它可以帮我们解决了如果有一个或多个node失败了,那么我们的数据还是可以保证完整的情况,并且搜索还可以继续进行.但是,有一种情况是我们的所有的n ...
- 知识广度 vs 知识深度
- 第六章:Django 综合篇 - 5:自定义django-admin命令
我们可以通过manage.py编写和注册自定义的命令. 自定义的管理命令对于独立脚本非常有用,特别是那些使用Linux的crontab服务,或者Windows的调度任务执行的脚本.比如,你有个需求,需 ...
- 9.使用nexus3配置Python私有仓库
搭建Python私服,我们依旧使用nexus3. 与其他私服一样的,Python私服同样有三种类型: hosted : 本地存储,便于开发者将个人的一些包上传到私服中 proxy : 提供代理其他仓库 ...
- Keepalived + Nginx 实现高可用 Web 负载均衡
一.Keepalived 简要介绍 Keepalived 是一种高性能的服务器高可用或热备解决方案, Keepalived 可以用来防止服务器单点故障的发生,通过配合 Nginx 可以实现 web 前 ...
- 自定义映射resultMap
resultMap处理字段和属性的映射关系 如果字段名与实体类中的属性名不一致,该如何处理映射关系? 第一种方法:为查询的字段设置别名,和属性名保持一致 下面是实体类中的属性名: private In ...
- css3_媒介查询
!!!做媒介查询页面大小时,一定要加: <meta name="viewport" content="width=device-width, initial-sca ...