大数据管理系统架构Hadoop
Hadoop 起源于Google Lab开发的Google File System (GFS)存储系统和MapReduce数据处理框架。2008年,Hadoop成了Apache上的顶级项目,发展到今天,Hadoop已经成了主流的大数据处理平台,与Spark、HBase、Hive、Zookeeper等项目一同构成了大数据分析和处理的生态系统。Hadoop是一个由超过60个子系统构成的系统集合。实际使用的时候,企业通过定制Hadoop生态系统(即选择相应的子系统)完成其实际大数据管理需求。Hadoop生态系统由两大核心子系统构成∶HDFS分布式文件系统和MapReduce数据处理系统。
HDFS分布式文件系统
HDFS是一个可扩展的分布式文件系统,它为海量的数据提供可靠的存储。HDFS的架构是构建在一组特定的节点上,其中包括一个NameNode 节点和数个DataNode 节点。NameNode 主要负责管理文件系统名称空间和控制外部客户机的访问,它对整个分布式文件系统进行总控制,记录数据分布存储的状态信息。DataNode则使用本地文件系统来实现HDFS的读写操作。每个DataNode都保存整个系统数据中的一小部分,通过心跳协议定期向NameNode报告该节点存储的数据块的状况。为了保证系统的可靠性,在DataNode发生宕机时不致文件丢失,HDFS会为文件创建复制块, 用户可以指定复制块的数目, 默认情况下, 每个数据块拥有额外两个复制块, 其中一个存储在与该数据块同一机架的不同节点上, 而另一复制块存储在不同机架的某个节点上。
所有对HDFS文件系统的访问都需要先与NameNode通信来获取文件分布的状态信息,再与相应的DataNode节点通信来进行文件的读写。由于NameNode处于整个集群的中心地位,当NameNode节点发生故障时整个HDFS 集群都会崩溃,因此HDFS中还包含了一个Secondary NameNode,它与NameNode之间保持周期通信,定期保存NameNode上元数据的快照,当NameNode发生故障而变得不可用时,Secondary NameNode 可以作为备用节点顶替NameNode,使集群快速恢复正常工作状态。
NameNode的单点特性制约了HDFS的扩展性,当文件系统中保存的文件过多时NameNode会成为整个集群的性能瓶颈。因此在Hadoop 2.0 中,HDFS Federation被提出,它使用多个NameNode分管不同的目录,使得HDFS具有横向扩展的能力。
MapReduce 数据处理系统
MapReduce是位于HDFS文件系统上一层的计算引擎,它由JobTracker 和 TaskTracker 组成。JobTracker是运行在 Hadoop 集群主节点上的重要进程,负责MapReduce的整体任务调度。同NameNode 一样,JobTracker在集群中也具有唯一性。TaskTracker进程则运行在集群中的每个子节点上,负责管理各自节点上的任务分配。
当外部客户机向MapReduce引擎提交计算作业时,JobTracker将作业切分成一个个小的子任务,并根据就近原则,把每个子任务分配到保存了相应数据的子节点上,并由子节点上的TaskTracker负责各自子任务的执行,并定期向JobTracker发送心跳来汇报任务执行状态。
Hadoop 2.0对MapReduce的架构加以改造,对JobTracker所负担的任务分配和资源管理两大职责进行分离,在原本的底层HDFS文件系统和MapReduce计算框架之间加入了新一代架构设计——YARN。
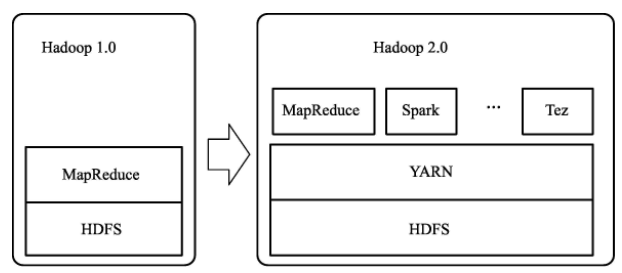
YARN 是一个通用的资源管理系统,为上层的计算框架提供统一的资源管理和调度。 NodeManager 运行于每个子节点上, 对不同的节点进行自管理,任务分配的职责也从原本的JobTracker中独立出来,由ApplicationMaster来负责,并在NodeManager控制的资源容器中运行。应用程序负责向资源管理器索要适当的资源容器, 运行任务以及跟踪应用程序执行状态。
YARN 新架构采用的责任下放思路使得 Hadoop 2.0拥有更高的扩展性,资源的动态分配也极大提升了集群资源利用率。不仅如此,ApplicationMaster的加入使得用户可以将自己的编程模型运行于Hadoop 集群上,加强了系统的兼容性和可用性,HDFS和MapReduce是Hadoop生态系统中的核心组件,提供基本的大数据存储和处理能力,以上述两个核心组件为基础,Hadoop 社区陆续开发出一系列子系统完成其他大数据管理需求,这些子系统和HDFS、MapReduce一起共同构成了Hadoop生态系统。下图显示了HortonWorks公司发布的Hadoop生态系统的系统架构。
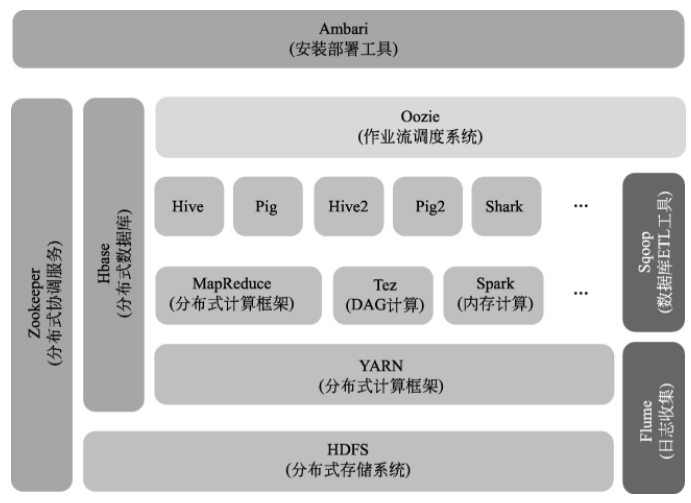
综上概括,Hadoop生态系统为用户提供的是一套可以用来组装自己的个性化数据管理系统的工具,用户根据自己的数据特征和应用需求,对一系列的部件进行有机地组装和部署,就能得到一个完整可用的管理平台。传统数据库软件采用的理念在大数据时代已经不再适用,大数据处理对系统架构的灵活性、数据处理伸缩性、数据处理效率提出了更高的要求。Hadoop 生态系统是开源社区对大数据挑战的解决方案,为大数据管理系统的后续发展奠定了良好的基础。
大数据管理系统架构Hadoop的更多相关文章
- hadoop大数据技术架构详解
大数据的时代已经来了,信息的爆炸式增长使得越来越多的行业面临这大量数据需要存储和分析的挑战.Hadoop作为一个开源的分布式并行处理平台,以其高拓展.高效率.高可靠等优点越来越受到欢迎.这同时也带动了 ...
- 量化派基于Hadoop、Spark、Storm的大数据风控架构--转
原文地址:http://www.csdn.net/article/2015-10-06/2825849 量化派是一家金融大数据公司,为金融机构提供数据服务和技术支持,也通过旗下产品“信用钱包”帮助个人 ...
- Laxcus大数据管理系统单机集群版
Laxcus大数据管理系统是我们Laxcus大数据实验室历时5年,全体系全功能设计研发的大数据产品,目前的最新版本是2.1版本.从三年前的1.0版本开始,Laxcus大数据系统投入到多个大数据和云计算 ...
- Laxcus大数据管理系统2.0(5)- 第二章 数据组织
第二章 数据组织 在数据的组织结构设计上,Laxcus严格遵循数据和数据描述分离的原则,这个理念与关系数据库完全一致.在此基础上,为了保证大规模数据存取和计算的需要,我们设计了大量新的数据处理技术.同 ...
- Laxcus大数据管理系统2.0(9)- 第七章 分布任务组件
第七章 分布任务组件 Laxcus 2.0版本的分布任务组件,是在1.x版本的基础上,重新整合中间件和分布计算技术,按照新增加的功能,设计的一套新的.分布状态下运行的数据计算组件和数据构建组件,以及依 ...
- Laxcus大数据管理系统2.0(10)- 第八章 安全
第八章 安全 由于安全问题对大数据系统乃至当前社会的重要性,我们在Laxcus 2.0版本实现了全体系的安全管理策略.同时我们也考虑到系统的不同环节对安全管理的需求是不一样的,所以有选择地做了不同的安 ...
- Laxcus大数据管理系统2.0(3)- 第一章 基础概述 1.2 产品特点
1.2 产品特点 Laxcus大数据管理系统运行在计算机集群上,特别强调软件对分布资源可随机增减的适应性.这种运行过程中数据动态波动和需要瞬时感知的特点,完全不同与传统的集中处理模式.这个特性衍生出一 ...
- Laxcus大数据管理系统2.0 (1) - 摘要和目录
Laxcus大数据管理系统 (version 2.0) Laxcus大数据实验室 摘要 Laxcus是Laxcus大数据实验室全体系全功能设计研发的多用户多集群大数据管理系统,支持一到百万台级节点,提 ...
- 知名大厂如何搭建大数据平台&架构
今天我们来看一下淘宝.美团和滴滴的大数据平台,一方面进一步学习大厂大数据平台的架构,另一方面也学习大厂的工程师如何画架构图.通过大厂的这些架构图,你就会发现,不但这些知名大厂的大数据平台设计方案大同小 ...
随机推荐
- 定制ASP.NET 6.0的应用配置
大家好,我是张飞洪,感谢您的阅读,我会不定期和你分享学习心得,希望我的文章能成为你成长路上的垫脚石,让我们一起精进. 本文的主题是应用程序配置.要介绍的是如何使用配置.如何自定义配置,以采用不同的方式 ...
- prop传值
将FooterMusic.vue中的play方法转到MusicDetail.vue中 用" :"v-bind 指令可以用于响应式地更新 HTML 特性:,在此进行动态赋值(play ...
- 使用docker搭建jupyter notebook / jupyterlab
说明 由于官方镜像实在是不怎么好用,所以我自己做了一个优化过的jupyter notebook的镜像 notebook_hub,使用我这个镜像搭建容器非常简单,下面就基于这个notebook_hub来 ...
- STC8H开发(十): SPI驱动Nokia5110 LCD(PCD8544)
目录 STC8H开发(一): 在Keil5中配置和使用FwLib_STC8封装库(图文详解) STC8H开发(二): 在Linux VSCode中配置和使用FwLib_STC8封装库(图文详解) ST ...
- 【二分图】匈牙利 & KM
[二分图]匈牙利 & KM 二分图 概念: 一个图 \(G=(V,E)\) 是无向图,如果顶点 \(V\) 可以分成两个互不相交地子集 \(X,Y\) 且任意一条边的两个顶点一个在 \(X\) ...
- JS:this关键字1
this 代表了当前的对象,哪个对象调用了this所在的函数,this就代表了哪个对象: 例1: function fn(){ var a = 1; console.log(this) } fn() ...
- 送分题,ArrayList 的扩容机制了解吗?
1. ArrayList 了解过吗?它是啥?有啥用? 众所周知,Java 集合框架拥有两大接口 Collection 和 Map,其中,Collection 麾下三生子 List.Set 和 Queu ...
- Phantomjs实用代码段(持续更新中……)
一.下载 下载链接二.解压安装包 直接解压即可三.配置环境变量 找到高级系统设置,打开它,出现以下图.点击环境变量. 分别点击编辑按钮 分别新建添加当初的解压路径,到bin文件夹.点击确定. 这样,环 ...
- 好用到爆!GitHub 星标 32.5k+的命令行软件管理神器,功能真心强大!
前言(废话) 本来打算在公司偷偷摸摸给星球的用户写一篇编程喵整合 MongoDB 的文章,结果在通过 brew 安装 MongoDB 的时候竟然报错了.原因很简单,公司这台 Mac 上的 homebr ...
- 一文看完vue3的变化之处
在通读了vue的官网文档后,我记录下了如下这些相对于2.x的变化之处. 1.创建应用实例的变化 之前一般是这样: let app = new Vue({ // ...一些选项 template: '' ...