在Yarn集群上跑spark wordcount任务
- 准备的测试数据文件hello.txt
hello scala
hello world
nihao hello
i am scala
this is spark demo
gan jiu wan le
- 将文件上传到hdfs中
#创建hdfs测试目录
hdfs dfs -mkdir /user/spark/input/
#上传本地文件hello.txt到hdfs
hdfs dfs -put ./hello.txt /user/spark/input/
- 代码(改为读取hdfs上的数据,并写入hdfs)
package org.example
import org.apache.spark.{SparkConf, SparkContext}
/**
* spark-submit --master yarn --class org.example.SparkWordCountYarn /tmp/test/sparkwordcount2-1.0-SNAPSHOT.jar hdfs://hadoop1:8020/user/spark/input/hello.txt hdfs://hadoop1:8020/user/spark/output/helloOutput
*/
object SparkWordCountYarn {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
.setAppName("WordCount")
.setMaster("yarn")
val srcFile = args(0)
val outPutFile = args(1)
val sc = new SparkContext(conf)
val data = sc.textFile(srcFile)
data.flatMap(_.split(" "))
.map((_, 1))
.reduceByKey(_+_)
.saveAsTextFile(outPutFile)
}
}
- 执行提交spark人物命令
spark-submit --master yarn --class org.example.SparkWordCountYarn /tmp/test/sparkwordcount2-1.0-SNAPSHOT.jar hdfs://hadoop1:8020/user/spark/input/hello.txt hdfs://hadoop1:8020/user/spark/output/helloOutput
- 执行结果
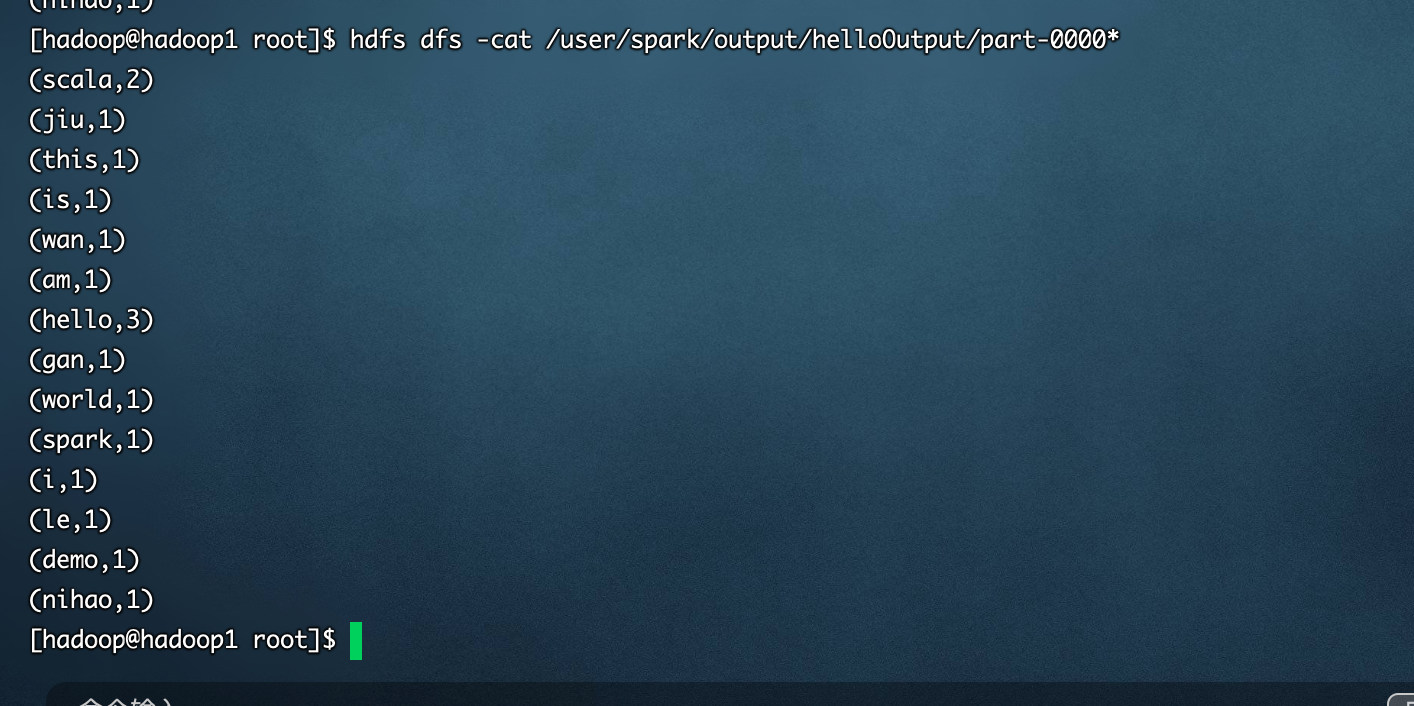
在Yarn集群上跑spark wordcount任务的更多相关文章
- Spark学习之在集群上运行Spark
一.简介 Spark 的一大好处就是可以通过增加机器数量并使用集群模式运行,来扩展程序的计算能力.好在编写用于在集群上并行执行的 Spark 应用所使用的 API 跟本地单机模式下的完全一样.也就是说 ...
- 在集群上运行Spark
Spark 可以在各种各样的集群管理器(Hadoop YARN.Apache Mesos,还有Spark 自带的独立集群管理器)上运行,所以Spark 应用既能够适应专用集群,又能用于共享的云计算环境 ...
- 有关python numpy pandas scipy 等 能在YARN集群上 运行PySpark
有关这个问题,似乎这个在某些时候,用python写好,且spark没有响应的算法支持, 能否能在YARN集群上 运行PySpark方式, 将python分析程序提交上去? Spark Applicat ...
- Spark学习之在集群上运行Spark(6)
Spark学习之在集群上运行Spark(6) 1. Spark的一个优点在于可以通过增加机器数量并使用集群模式运行,来扩展程序的计算能力. 2. Spark既能适用于专用集群,也可以适用于共享的云计算 ...
- Spark学习笔记——在集群上运行Spark
Spark运行的时候,采用的是主从结构,有一个节点负责中央协调, 调度各个分布式工作节点.这个中央协调节点被称为驱动器( Driver) 节点.与之对应的工作节点被称为执行器( executor) 节 ...
- 《Spark快速大数据分析》—— 第七章 在集群上运行Spark
- Spark程序提交到Yarn集群时所遇异常
Exception 1:当我们将任务提交给Spark Yarn集群时,大多会出现以下异常,如下: 14/08/09 11:45:32 WARN component.AbstractLifeCycle: ...
- Spark on Yarn 集群运行要点
实验版本:spark-1.6.0-bin-hadoop2.6 本次实验主要是想在已有的Hadoop集群上使用Spark,无需过多配置 1.下载&解压到一台使用spark的机器上即可 2.修改配 ...
- 在local模式下的spark程序打包到集群上运行
一.前期准备 前期的环境准备,在Linux系统下要有Hadoop系统,spark伪分布式或者分布式,具体的教程可以查阅我的这两篇博客: Hadoop2.0伪分布式平台环境搭建 Spark2.4.0伪分 ...
随机推荐
- RPA应用场景-报税机器人
场景概述 报税机器人 所涉系统名称 税务网站 人工操作(时间/次) 53分钟 所涉人工数量 60 操作频率 每月 场景流程 1.通过RPA自动将财税信息从对应系统中导出 2.RPA根据不同的税务报表规 ...
- jenkins配置自动执行sql脚本
shell脚本: bigsql="select big_version,small_version from d0mstore.db_current_version order by big ...
- ArrayList集合概述和基本使用和ArrayList集合的常用方法和遍历
什么是ArrayList类 java.util.ArrayList 是大小可变的数组的实现,存储在内的数据称为元素.此类提供一些方法来操作内部存储 的元素. ArrayList 中可不断添加元素,其大 ...
- idea java 打包的方法
方法1: 在pom.xml 里面加上maven打包的配置 <plugin> <groupId>org.springframework.cloud</groupId> ...
- RK3568开发笔记(四):在虚拟机上使用SDK编译制作uboot、kernel和buildroot镜像
前言 上一篇搭建好了ubuntu宿主机开发环境,本篇的目标系统主要是开发linux+qt,所以需要刷上billdroot+Qt创建的系统,为了更好的熟悉原理和整个开发过程,选择从零开始搭建rk35 ...
- 什么是FastAPI异步框架?(全面了解)
一:FastAPI框架 1.FastAPI是应该用于构建API的现代,快速(高性能)的 web 框架,使用Python 3.6+ 并基于标准的 Python 类型提示. 关键性: 快速: 可与Node ...
- EfficientFormer:轻量化ViT Backbone
论文:<EfficientFormer: Vision Transformers at MobileNet Speed > Vision Transformers (ViT) 在计算机视觉 ...
- 聊聊如何用 Redis 实现分布式锁?
作者:小林coding 计算机八股文网站:https://xiaolincoding.com 哈喽,我是小林. 今天跟大家聊聊两个问题: 如何用 Redis 实现分布式锁? Redis 是如何解决集群 ...
- YII容器类依赖注入
程序 = 算法 + 数据结构 数据结构 制约了 算法的===>>>>依赖注入 依赖注入也就是解数据结构和算法耦合的思想 <?php /** * Created by Ph ...
- 论文解读(GSAT)《Interpretable and Generalizable Graph Learning via Stochastic Attention Mechanism》
论文信息 论文标题:Interpretable and Generalizable Graph Learning via Stochastic Attention Mechanism论文作者:Siqi ...