linux下安装Elasticsearch(单机版和集群版)
一、linux下安装Elasticsearch(单机)
1、软件下载
下载地址:https://www.elastic.co/cn/downloads/past-releases/elasticsearch-7-8-0

2、软件安装
将下载的软件上传到linux中并解压
# 解压到指定文件夹
tar -zxvf elasticsearch-7.8.0-linux-x86_64.tar.gz -C /opt/module/
修改解压后的文件名
mv elasticsearch-7.8.0 es
创建新用户
由于安全问题,Elasticsearch 不允许 root 用户直接运行,所以要创建新用户,在 root 用
户中创建新用户
#新增 es 用户
useradd es
#为 es 用户设置密码
passwd es
#如果错了,可以删除再加
userdel -r es
#修改文件夹所有者
chown -R es:es /opt/module/es

修改配置文件
修改/opt/module/es/config/elasticsearch.yml 文件
# 加入如下配置
cluster.name: elasticsearch
node.name: node-1
network.host: 0.0.0.0
http.port: 9200
cluster.initial_master_nodes: ["node-1"]

修改/etc/security/limits.conf
# 在文件末尾中增加下面内容
# 每个进程可以打开的文件数的限制
es soft nofile 65536
es hard nofile 65536

修改/etc/security/limits.d/20-nproc.conf
# 在文件末尾中增加下面内容
# 每个进程可以打开的文件数的限制
es soft nofile 65536
es hard nofile 65536
# 操作系统级别对每个用户创建的进程数的限制
* hard nproc 4096
# 注:* 带表 Linux 所有用户名称

修改/etc/sysctl.conf
# 在文件中增加下面内容
# 一个进程可以拥有的 VMA(虚拟内存区域)的数量,默认值为 65536
vm.max_map_count=655360

重新加载
sysctl -p
启动Elasticsearch
使用es用户启动
# 切换到es目录
cd /opt/module/es/
#启动
bin/elasticsearch
#后台启动
bin/elasticsearch -d
注:启动时,会动态生成文件,如果文件所属用户不匹配,会发生错误。
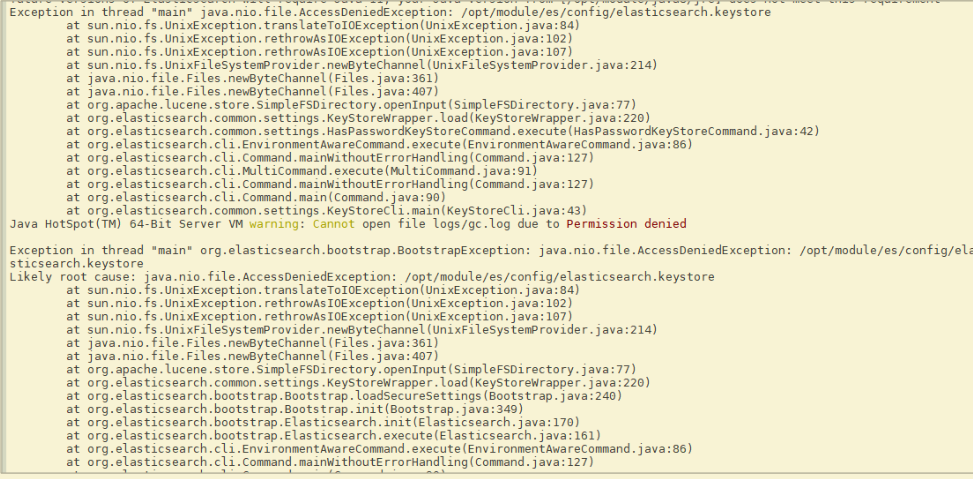
解决办法:切换到root用户下,重新进行修改用户和用户组
su - root
#修改文件夹所有者
chown -R es:es /opt/module/es
在浏览器中访问
浏览器中输入地址:http://192.168.88.120:9200/

注:ip地址要换成你主机的ip地址哦!
至此在linux下搭建单机版的Elasticsearch完成!
二、Linux下安装Elasticsearch(集群)
1、Elasticsearch安装
- 准备好三台机器,分别在三台机器上按照单机版安装过程安装Elasctisearch
2、集群配置
分别修改三台机器中 /opt/module/es/config/elasticsearch.yml 文件
linux1:
# 加入如下配置
#集群名称
cluster.name: cluster-es
#节点名称,每个节点的名称不能重复
node.name: node-1
#ip 地址,每个节点的地址不能重复、换成自己本机的IP地址 或者配置ip地址和主机名之间的映射
network.host: linux1
#是不是有资格主节点
node.master: true
node.data: true
http.port: 9200
# head 插件需要这打开这两个配置
http.cors.allow-origin: "*"
http.cors.enabled: true
http.max_content_length: 200mb
#es7.x 之后新增的配置,初始化一个新的集群时需要此配置来选举 master
cluster.initial_master_nodes: ["node-1"]
#es7.x 之后新增的配置,节点发现
discovery.seed_hosts: ["linux1:9300","linux2:9300","linux3:9300"]
gateway.recover_after_nodes: 2
network.tcp.keep_alive: true
network.tcp.no_delay: true
transport.tcp.compress: true
#集群内同时启动的数据任务个数,默认是 2 个
cluster.routing.allocation.cluster_concurrent_rebalance: 16
#添加或删除节点及负载均衡时并发恢复的线程个数,默认 4 个
cluster.routing.allocation.node_concurrent_recoveries: 16
#初始化数据恢复时,并发恢复线程的个数,默认 4 个
cluster.routing.allocation.node_initial_primaries_recoveries: 16
linux2:
# 加入如下配置
#集群名称
cluster.name: cluster-es
#节点名称,每个节点的名称不能重复
node.name: node-2
#ip 地址,每个节点的地址不能重复、换成自己本机的IP地址 或者配置ip地址和主机名之间的映射
network.host: linux2
#是不是有资格主节点
node.master: true
node.data: true
http.port: 9200
# head 插件需要这打开这两个配置
http.cors.allow-origin: "*"
http.cors.enabled: true
http.max_content_length: 200mb
#es7.x 之后新增的配置,初始化一个新的集群时需要此配置来选举 master
cluster.initial_master_nodes: ["node-1"]
#es7.x 之后新增的配置,节点发现
discovery.seed_hosts: ["linux1:9300","linux2:9300","linux3:9300"]
gateway.recover_after_nodes: 2
network.tcp.keep_alive: true
network.tcp.no_delay: true
transport.tcp.compress: true
#集群内同时启动的数据任务个数,默认是 2 个
cluster.routing.allocation.cluster_concurrent_rebalance: 16
#添加或删除节点及负载均衡时并发恢复的线程个数,默认 4 个
cluster.routing.allocation.node_concurrent_recoveries: 16
#初始化数据恢复时,并发恢复线程的个数,默认 4 个
cluster.routing.allocation.node_initial_primaries_recoveries: 16
linux3:
# 加入如下配置
#集群名称
cluster.name: cluster-es
#节点名称,每个节点的名称不能重复
node.name: node-3
#ip 地址,每个节点的地址不能重复、换成自己本机的IP地址 或者配置ip地址和主机名之间的映射
network.host: linux3
#是不是有资格主节点
node.master: true
node.data: true
http.port: 9200
# head 插件需要这打开这两个配置
http.cors.allow-origin: "*"
http.cors.enabled: true
http.max_content_length: 200mb
#es7.x 之后新增的配置,初始化一个新的集群时需要此配置来选举 master
cluster.initial_master_nodes: ["node-1"]
#es7.x 之后新增的配置,节点发现
discovery.seed_hosts: ["linux1:9300","linux2:9300","linux3:9300"]
gateway.recover_after_nodes: 2
network.tcp.keep_alive: true
network.tcp.no_delay: true
transport.tcp.compress: true
#集群内同时启动的数据任务个数,默认是 2 个
cluster.routing.allocation.cluster_concurrent_rebalance: 16
#添加或删除节点及负载均衡时并发恢复的线程个数,默认 4 个
cluster.routing.allocation.node_concurrent_recoveries: 16
#初始化数据恢复时,并发恢复线程的个数,默认 4 个
cluster.routing.allocation.node_initial_primaries_recoveries: 16
- 集群启动
分别在三台机器上启动Elasticsearch
linux下安装Elasticsearch(单机版和集群版)的更多相关文章
- Linux系统下安装Redis和Redis集群配置
Linux系统下安装Redis和Redis集群配置 一. 下载.安装.配置环境: 1.1.>官网下载地址: https://redis.io/download (本人下载的是3.2.8版本:re ...
- 记录Linux下安装elasticSearch时遇到的一些错误
记录Linux下安装elasticSearch时遇到的一些错误 http://blog.sina.com.cn/s/blog_c90ce4e001032f7w.html (2016-11-02 22: ...
- (转)淘淘商城系列——使用Spring来管理Redis单机版和集群版
http://blog.csdn.net/yerenyuan_pku/article/details/72863323 我们知道Jedis在处理Redis的单机版和集群版时是完全不同的,有可能在开发的 ...
- Redis单机版以及集群版的安装搭建以及使用
1,redis单机版 1.1 安装redis n 版本说明 本教程使用redis3.0版本.3.0版本主要增加了redis集群功能. 安装的前提条件: 需要安装gcc:yum install g ...
- Redis单机版和集群版的安装和部署
1.单机版的安装 本次使用redis3.0版本.3.0版本主要增加了redis集群功能. 安装的前提条件: 需要安装gcc:yum install gcc-c++ 1.1 安装redis 1.下载re ...
- redis单机版和集群版搭建笔记-简略版
搭建单机版: 解压 tar -zxf redis-3.0.0.tar.gz 编译 cd redis-3.0.0 安装 make install prefix=/usr/local/redis-inst ...
- shiro的单机版 和 集群版
在我们的开发当中 我们一般权限都是个 比较繁琐 但又必不可少的 一部分 [不管我们的 数据库设计 还是我们采用何种技术 我们的权限库表 大多都是大同小异 业务逻辑也是如此] 在我们不使用任何框架 ...
- 使用jedis客户端连接redis,单机版和集群版
单机版 1.入门实例 @Test public void testJedis(){ //创建一个jedis对象,需要指定服务的ip和端口号 Jedis jedis=new Jedis("19 ...
- redis在项目中的使用(单机版、集群版)
1.下载jar包:jedis-2.6.2.jar 2.代码: JedisDao.java: package com.test.www.dao; public interface JedisDao { ...
随机推荐
- windows下docker部署报错
报错信息:Error response from daemon: Ports are not available: exposing port TCP 0.0.0.0:8848 -> 0.0.0 ...
- NC20276 [SCOI2010]传送带
NC20276 [SCOI2010]传送带 题目 题目描述 在一个2维平面上有两条传送带,每一条传送带可以看成是一条线段.两条传送带分别为线段AB和线段CD.lxhgww在AB上的移动速度为P,在CD ...
- HashSet 添加/遍历元素源码分析
HashSet 类图 HashSet 简单说明 HashSet 实现了 Set 接口 HashSet 底层实际上是由 HashMap 实现的 public HashSet() { map = new ...
- Ubuntu安装python各版本
编译安装的话,之前遇到过很多小问题,感觉还是通过添加这个ppa方式装的比较稳,缺点是可能安装的比较慢,可配合proxychain4 sudo apt install software-properti ...
- 【Unity基础知识】认识常用的生命周期函数(Awake、Start、Update...)
一.了解帧的概念 游戏的本质就是一个死循环 每一次循环都会处理游戏逻辑 并 更新一次游戏画面 之所以能看到画面在动 是因为 切换画面速度达到一定速度时 人眼就会认为画面是动态且流畅的 一帧就是执行了一 ...
- Menci的序列
题目大意 一个长度为n的字符串s,只包含+和×. 选出一个子序列,然后你有一个ret,初始为0,按顺序扫你选出的这个子序列. 如果碰到的是+,ret+1,否则ret*2. 最大化ret%2^k. 首先 ...
- 体验Lambda的更优写法和Lambda标准格式
体验Lambda的更优写法 借助Java8的全新语法,上述Runnable接口的匿名内部类写法可以通过更简单的Lambda表达式达到等效: public class Lambda02 { public ...
- ubu18时间设置
ubu18 日期设置 1.date date 命令修改系统时间,重启失效,需要写入硬件Bios #查看日期 date #修改日期 date -s "2022-01-14 09:32:00&q ...
- 使用Hexo建立一个轻量、简易、高逼格的博客
原文转载自「刘悦的技术博客」https://v3u.cn/a_id_93 在之前的一篇文章中,介绍了如何使用Hugo在三分钟之内建立一个简单的个人博客系统,它是基于go lang的,其实,市面上还有一 ...
- MES对接Simba实现展讯平台 IMEI 写号与耦合测试
文章开始之前,必须对Simba工具点一个大大的赞,Simba为了适应市面上不同厂家开发的 MES 系统,特地开发了统一的接口,各个 MES 厂家只需要按照接口规范去做开发,然后将中间件加载到 Simb ...