一次spark任务提交参数的优化
起因
新接触一个spark集群,明明集群资源(core,内存)还有剩余,但是提交的任务却申请不到资源。
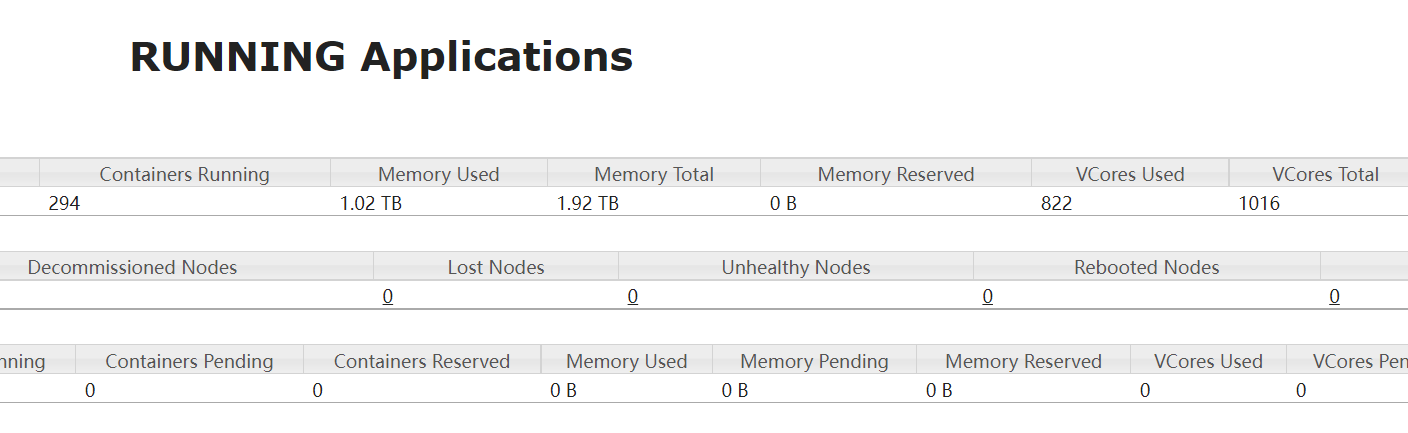
分析
环境
spark 2.2.0
基于yarn集群
参数
spark任务提交参数中最重要的几个:
spark-submit --master yarn --driver-cores 1 --driver-memory 5G --executor-cores 2 --num-executors 16 --executor-memory 4G
driver-cores driver端核数
driver-memory driver端内存大小
executor-cores 每个执行器的核数
num-executors 此任务申请的执行器总数
executor-memory 每个执行器的内存大小
那么,该任务将申请多少资源呢?
申请的执行器总内存数大小=num-executor * (executor-memory +spark.yarn.executor.memoryOverhead) = 16 * (4 + 2) = 96
申请的总内存=执行器总内存+dirver端内存=101
申请的总核数=num-executor*executor-core + yarn.AM(默认为1)=33
运行的总容器(contanier) = num-executor + yarn.AM(默认为1) = 17
所以这里还有一个关键的参数 spark.yarn.executor.memoryOverhead
这个参数是什么意思呢?
堆外内存,每个executor归spark 计算的内存为executor-memory,每个executor是一个单独的JVM,这个JAVA虚拟机本向在的内存大小即为spark.yarn.executor.memoryOverhead,不归spark本身管理。在spark集群中配置。也可在代码中指定
spark.set("spark.yarn.executor.memoryOverhead", 1)
这部份实际上是存放spark代码本身的究竟,在executor-memory内存不足的时候也能应应急顶上。
问题所在
假设一个节点16G的内存,每个executor-memory=4,理想情况下4x4=16,那么该节点可以分配出4个节点供spark任务计算所用。
1.但应考虑到spark.yarn.executor.memoryOverhead.
如果spark.yarn.executor.memoryOverhead=2,那么每个executor所需申请的资源为4+2=6G,那么该节点只能分配2个节点,剩余16-6x2=4G的内存,无法使用。
如果一个集群共100个节点,用户将在yarn集群主界面看到,集群内存剩余400G,但一直无法申请到资源。
2.core也是一样的道理。
很多同学容易忽略spark.yarn.executor.memoryOverhead此参数,然后陷入怀疑,怎么申请的资源对不上,也容易陷入优化的误区。
优化结果
最终优化结果,将spark.yarn.executor.memoryOverhead调小,并根据node节点资源合理优化executor-memory,executor-core大小,将之前经常1.6T的内存占比,降到1.1左右。并能较快申请到资源。
一次spark任务提交参数的优化的更多相关文章
- spark作业提交参数设置(转)
来源:https://www.cnblogs.com/arachis/p/spark_parameters.html 摘要 1.num-executors 2.executor-memory 3.ex ...
- Spark on Yarn:任务提交参数配置
当在YARN上运行Spark作业,每个Spark executor作为一个YARN容器运行.Spark可以使得多个Tasks在同一个容器里面运行. 以下参数配置为例子: spark-submit -- ...
- Spark性能调优篇一之任务提交参数调整
问题一:有哪些资源可以分配给spark作业使用? 答案:executor个数,cpu per exector(每个executor可使用的CPU个数),memory per exector(每个exe ...
- spark源码分析以及优化
第一章.spark源码分析之RDD四种依赖关系 一.RDD四种依赖关系 RDD四种依赖关系,分别是 ShuffleDependency.PrunDependency.RangeDependency和O ...
- Spark 3.x Spark Core详解 & 性能优化
Spark Core 1. 概述 Spark 是一种基于内存的快速.通用.可扩展的大数据分析计算引擎 1.1 Hadoop vs Spark 上面流程对应Hadoop的处理流程,下面对应着Spark的 ...
- Spark学习(四) -- Spark作业提交
标签(空格分隔): Spark 作业提交 先回顾一下WordCount的过程: sc.textFile("README.rd").flatMap(line => line.s ...
- Spark集群模式&Spark程序提交
Spark集群模式&Spark程序提交 1. 集群管理器 Spark当前支持三种集群管理方式 Standalone-Spark自带的一种集群管理方式,易于构建集群. Apache Mesos- ...
- 【Spark-core学习之四】 Spark任务提交
环境 虚拟机:VMware 10 Linux版本:CentOS-6.5-x86_64 客户端:Xshell4 FTP:Xftp4 jdk1.8 scala-2.10.4(依赖jdk1.8) spark ...
- spark任务提交到yarn上命令总结
spark任务提交到yarn上命令总结 1. 使用spark-submit提交任务 集群模式执行 SparkPi 任务,指定资源使用,指定eventLog目录 spark-submit --class ...
- Spark开发常用参数
Driver spark.driver.cores driver端分配的核数,默认为1,thriftserver是启动thriftserver服务的机器,资源充足的话可以尽量给多. spark.dri ...
随机推荐
- noi 1.1 5 输出保留12位小数的浮点数
描述 读入一个双精度浮点数,保留12位小数,输出这个浮点数. 输入 只有一行,一个双精度浮点数. 输出 也只有一行,保留12位小数的浮点数. 样例输入 3.1415926535798932 样例输出 ...
- Centos使用nohup实现后台运行程序
nohup和&的区别& : 指在后台运行 nohup : 不挂断的运行,注意并没有后台运行的功能,,就是指,用nohup运行命令可以使命令永久的执行下去,和用户终端没有关系,例如我们断 ...
- 20200926--图像旋转(奥赛一本通P96 9 多维数组)
输入一个n行m列的黑白图像,将它顺时针旋转90度后输出. 输入:第1行包含两个整数n和m(1<=n<=100,1<=m<=100),表示图像包含像素点的行数和列数. 接下来n行 ...
- pyechart画图(1)安装和基本操作
安装 pip install pyecharts==0.1.9.4 https://blog.csdn.net/weixin_43735353/article/details/89328048 Lin ...
- Python中使用pyyaml对yaml文件进行读写删操作
安装库 pip install pyyaml 读取yaml/yam格式的文件 def get_yaml(filepath) -> list: """ :param ...
- software engineering homework 1
1. 回顾你过去将近3年的学习经历 当初你报考的时候,是真正喜欢计算机这个专业吗? 你现在后悔选择了这个专业吗? 你认为你现在最喜欢的领域是什么(可以是计算机的也可以是其它领域)? 答:一开始感觉编程 ...
- 枚举类list序列化与反序列化
//序列化 public class AuthTypeEnumListJsonSerializer extends JsonSerializer<List> { @Override pub ...
- java接口自动化需要的技术
1.testNG需要了解的知识 ITestContext这个类可以直接在方法参数里使用,主要作用是可以通过它的context.getSuite()直接获取suite的相关信息.还可以通过它的 cont ...
- 2003031126-石升福-python数据分析第四周作业-第二次作业
项目 matplotlib 博客名称 2003031126-石升福-Python数据分析第四周作业 班级链接 20级数据班 作业链接 第二次作业 要求 每道题要有题目,代码(使用插入代码,不会插入代码 ...
- springmvc接口访问流程排查
首先找到webapp下面的web.xml文件: 检查前端控制器: 并注意contextConfigLocation配置的springmvc的配置文件路径: 接着找到springmvc配置文件路径,如果 ...