KMP 算法实现
# coding=utf-8
def get_next_list(findding_str): # O(m)
# 求一个字符串序列每个位置的最长相等前、后缀
j = 0 # 最长相等前缀的末位
next = [0] # next 数组用于保存字符串每个位置的最长相等前、后缀的长度值
# i 是最长相等后缀的末位
for i in range(1, len(findding_str)):
while j > 0 and findding_str[i] != findding_str[j]:
# 如果当前 前缀末位(j)字符与当前i位置的字符不相等时,j回退 PS:j的值也表示findding_str[:i+1]最长相等前、后缀的长度值
j = next[j-1]
if findding_str[i] == findding_str[j]:
j += 1
next.append(j)
return next
def KMP(findding_str, next, parent_str): # O(n)
ind = 0
for i in range(len(parent_str)):
while parent_str[i] != findding_str[ind]:
if ind == 0:
break
# parent_str[i] != findding_str[ind] 且 ind != 0 时,从findding_str[ind] 左侧的字符串的最大相等前缀处开始比较
ind = next[ind-1]
if parent_str[i] == findding_str[ind]:
ind += 1
if ind == len(findding_str):
print(i, ind, parent_str[i - ind + 1: i+1])
ind = 0
# break
if __name__ == '__main__':
parent_str = 'aabafgggahaabaafaabaahatjhrtjabaafaabaahaabaafaabaahaabaaf'
findding_str = 'aabaaf'
KMP(findding_str, get_next_list(findding_str), parent_str)
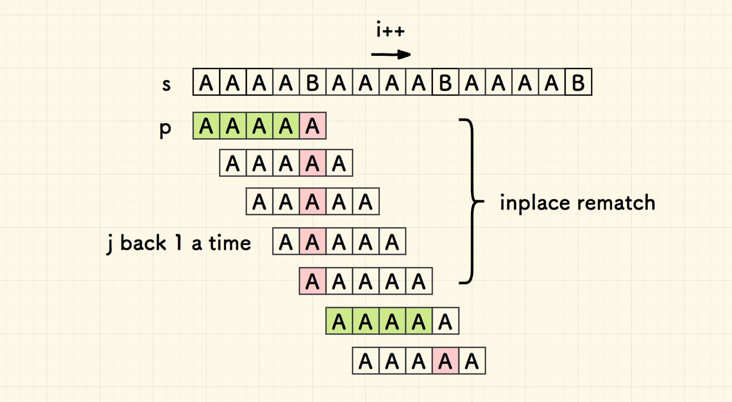
当在 j 处失配时,j -> next[j] 是说回溯到位置 next[j]
注意,next[j] 的位置的含义是什么?是对齐了已经匹配好的串的位置。
下图中,红色的方格是失配处。一旦失配,j 发生回溯跳转,
因为新位置左边的串已经是匹配好的(这正是 next 数组的含义,前后公共缀的长度),所以无需回溯到头。

按上面的图,数一数,绿色的是匹配上的字符,红色的是失配的地方,横向 n 个,
纵向 m 个,总共 m + n 次比对。
每次失配,子串回溯,对齐已匹配串,在失配处原地再匹配一次主串对应字符
所以,kmp 的比对次数是 (n + 失配次数)
KMP 算法的最差情况的一个案例,n/m 个失配点位,每个点位重新匹配 m-1 次,此时总共比对 n+(m-1)*(n/m) 次,接近 2n 次。
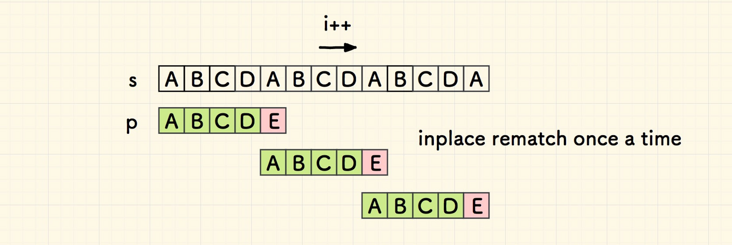
如果不考虑搜索到的情况,最好情况如下,总共比对 n+1*(n/m) 次,如果 m 很小,也接近 2n 次,如果 m 比较大,就接近 n 次。
算上预处理阶段O(m),KMP 在最好、最坏的情况下的时间复杂度都是 O(m+n)
参考链接:https://segmentfault.com/q/1010000014560162
KMP 算法实现的更多相关文章
- 简单有效的kmp算法
以前看过kmp算法,当时接触后总感觉好深奥啊,抱着数据结构的数啃了一中午,最终才大致看懂,后来提起kmp也只剩下“奥,它是做模式匹配的”这点干货.最近有空,翻出来算法导论看看,原来就是这么简单(先不说 ...
- KMP算法
KMP算法是字符串模式匹配当中最经典的算法,原来大二学数据结构的有讲,但是当时只是记住了原理,但不知道代码实现,今天终于是完成了KMP的代码实现.原理KMP的原理其实很简单,给定一个字符串和一个模式串 ...
- 萌新笔记——用KMP算法与Trie字典树实现屏蔽敏感词(UTF-8编码)
前几天写好了字典,又刚好重温了KMP算法,恰逢遇到朋友吐槽最近被和谐的词越来越多了,于是突发奇想,想要自己实现一下敏感词屏蔽. 基本敏感词的屏蔽说起来很简单,只要把字符串中的敏感词替换成"* ...
- KMP算法实现
链接:http://blog.csdn.net/joylnwang/article/details/6778316 KMP算法是一种很经典的字符串匹配算法,链接中的讲解已经是很明确得了,自己按照其讲解 ...
- 数据结构与算法JavaScript (五) 串(经典KMP算法)
KMP算法和BM算法 KMP是前缀匹配和BM后缀匹配的经典算法,看得出来前缀匹配和后缀匹配的区别就仅仅在于比较的顺序不同 前缀匹配是指:模式串和母串的比较从左到右,模式串的移动也是从 左到右 后缀匹配 ...
- 扩展KMP算法
一 问题定义 给定母串S和子串T,定义n为母串S的长度,m为子串T的长度,suffix[i]为第i个字符开始的母串S的后缀子串,extend[i]为suffix[i]与字串T的最长公共前缀长度.求出所 ...
- 字符串模式匹配之KMP算法图解与 next 数组原理和实现方案
之前说到,朴素的匹配,每趟比较,都要回溯主串的指针,费事.则 KMP 就是对朴素匹配的一种改进.正好复习一下. KMP 算法其改进思想在于: 每当一趟匹配过程中出现字符比较不相等时,不需要回溯主串的 ...
- 算法:KMP算法
算法:KMP排序 算法分析 KMP算法是一种快速的模式匹配算法.KMP是三位大师:D.E.Knuth.J.H.Morris和V.R.Pratt同时发现的,所以取首字母组成KMP. 少部分图片来自孤~影 ...
- BF算法与KMP算法
BF(Brute Force)算法是普通的模式匹配算法,BF算法的思想就是将目标串S的第一个字符与模式串T的第一个字符进行匹配,若相等,则继续比较S的第二个字符和 T的第二个字符:若不相等,则比较S的 ...
- KMP算法-next函数求解
KMP函数求解:一种改进的字符串匹配算法,由D.E.Knuth,J.H.Morris和V.R.Pratt同时发现,因此人们称它为KMP算法.KMP算法的关键是利用匹配失败后的信息,尽量减少模式串与主串 ...
随机推荐
- CVE-2007-4556 s2-001
漏洞名称 S2-001 远程代码执行 利用条件 WebWork 2.1 (with altSyntax enabled), WebWork 2.2.0 - WebWork 2.2.5, Struts ...
- 题解P3847 [TJOI2007]调整队形
简要题意 给出一个长度为 \(n\) 的序列 \(A\),你需要执行下面的操作,将这个序列变成回文序列: 在序列左右侧或中间插入一个元素,元素数值任意. 删除一个元素. 更改一个元素的值. \(1 \ ...
- 解决 requests cookies 为空的坑
转载请注明出处️ 作者:测试蔡坨坨 原文链接:caituotuo.top/5d14f0d7.html 你好,我是测试蔡坨坨. 我们在做接口自动化测试的时候,一般会通过调用登录接口来获取cookies. ...
- BC4-牛牛学说话之-浮点数
题目描述 会说整数之后,牛牛开始尝试浮点数(小数),输入一个浮点数,输出这个浮点数. 输入描述 输入一个浮点数 输出描述 输出一个浮点数,保留三位小数 示例 1 输入:1.359578 输出:1.36 ...
- 单线程架构的Redis如此之快的 4 个原因
前言 作为内存中数据存储,Redis 以其速度和性能着称,通常被用作大多数后端服务的缓存解决方案. 但是,在内部,Redis 采用单线程架构. 为什么单线程设计依然会有这么高的性能?如果利用多线程并发 ...
- Android IO 框架 Okio 的实现原理,到底哪里 OK?
本文已收录到 AndroidFamily,技术和职场问题,请关注公众号 [彭旭锐] 提问. 前言 大家好,我是小彭. 今天,我们来讨论一个 Square 开源的 I/O 框架 Okio,我们最开始接触 ...
- 如何使用 ArrayPool
如果不停的 new 数组,可能会造成 GC 的压力,因此在 aspnetcore 中推荐使用 ArrayPool 来重用数组,本文将介绍如何使用 ArrayPool. 使用 ArrayPool Arr ...
- 如何在Net6.0里配置多版本支持并支持注释说明的Swagger
一.前言 现在已经进入了微服务的开发时代了,在这个时代,如果有人问你什么是微服务,你说不知道,就有点太丢人了,别人会有异样的眼光看你,俗话说:唾液淹死人.没办法,我们只能去学习新的东西.一提到微服务, ...
- CF1250C Trip to Saint Petersburg
题目传送门 思路 线段树入门题. 不妨固定一个右端点 \(r\),把所有右端点小于 \(r\) 的区间都在 \(1\) 至此区间的左端点处 update 一个 \(p\),然后每次都给区间 \(1\) ...
- .Net NPOI 简单Demo,一看就会
#region 文件输出 public class BasicInfodsa { public string name; public string phone; } List zyData = ...