KMP 算法实现
# coding=utf-8
def get_next_list(findding_str): # O(m)
# 求一个字符串序列每个位置的最长相等前、后缀
j = 0 # 最长相等前缀的末位
next = [0] # next 数组用于保存字符串每个位置的最长相等前、后缀的长度值
# i 是最长相等后缀的末位
for i in range(1, len(findding_str)):
while j > 0 and findding_str[i] != findding_str[j]:
# 如果当前 前缀末位(j)字符与当前i位置的字符不相等时,j回退 PS:j的值也表示findding_str[:i+1]最长相等前、后缀的长度值
j = next[j-1]
if findding_str[i] == findding_str[j]:
j += 1
next.append(j)
return next
def KMP(findding_str, next, parent_str): # O(n)
ind = 0
for i in range(len(parent_str)):
while parent_str[i] != findding_str[ind]:
if ind == 0:
break
# parent_str[i] != findding_str[ind] 且 ind != 0 时,从findding_str[ind] 左侧的字符串的最大相等前缀处开始比较
ind = next[ind-1]
if parent_str[i] == findding_str[ind]:
ind += 1
if ind == len(findding_str):
print(i, ind, parent_str[i - ind + 1: i+1])
ind = 0
# break
if __name__ == '__main__':
parent_str = 'aabafgggahaabaafaabaahatjhrtjabaafaabaahaabaafaabaahaabaaf'
findding_str = 'aabaaf'
KMP(findding_str, get_next_list(findding_str), parent_str)
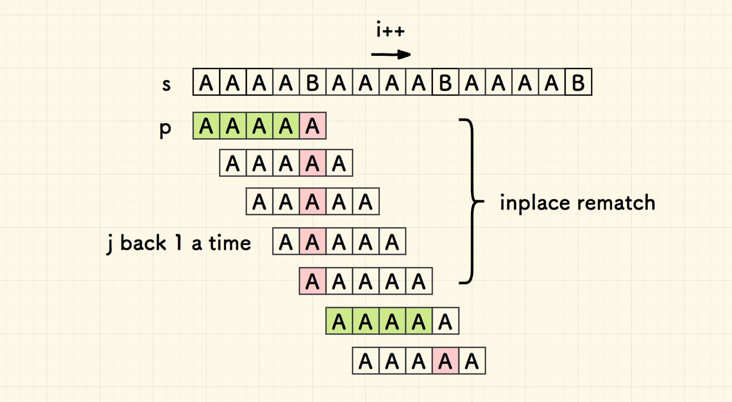
当在 j 处失配时,j -> next[j] 是说回溯到位置 next[j]
注意,next[j] 的位置的含义是什么?是对齐了已经匹配好的串的位置。
下图中,红色的方格是失配处。一旦失配,j 发生回溯跳转,
因为新位置左边的串已经是匹配好的(这正是 next 数组的含义,前后公共缀的长度),所以无需回溯到头。

按上面的图,数一数,绿色的是匹配上的字符,红色的是失配的地方,横向 n 个,
纵向 m 个,总共 m + n 次比对。
每次失配,子串回溯,对齐已匹配串,在失配处原地再匹配一次主串对应字符
所以,kmp 的比对次数是 (n + 失配次数)
KMP 算法的最差情况的一个案例,n/m 个失配点位,每个点位重新匹配 m-1 次,此时总共比对 n+(m-1)*(n/m) 次,接近 2n 次。
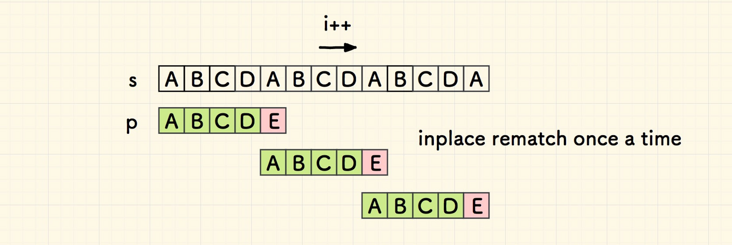
如果不考虑搜索到的情况,最好情况如下,总共比对 n+1*(n/m) 次,如果 m 很小,也接近 2n 次,如果 m 比较大,就接近 n 次。
算上预处理阶段O(m),KMP 在最好、最坏的情况下的时间复杂度都是 O(m+n)
参考链接:https://segmentfault.com/q/1010000014560162
KMP 算法实现的更多相关文章
- 简单有效的kmp算法
以前看过kmp算法,当时接触后总感觉好深奥啊,抱着数据结构的数啃了一中午,最终才大致看懂,后来提起kmp也只剩下“奥,它是做模式匹配的”这点干货.最近有空,翻出来算法导论看看,原来就是这么简单(先不说 ...
- KMP算法
KMP算法是字符串模式匹配当中最经典的算法,原来大二学数据结构的有讲,但是当时只是记住了原理,但不知道代码实现,今天终于是完成了KMP的代码实现.原理KMP的原理其实很简单,给定一个字符串和一个模式串 ...
- 萌新笔记——用KMP算法与Trie字典树实现屏蔽敏感词(UTF-8编码)
前几天写好了字典,又刚好重温了KMP算法,恰逢遇到朋友吐槽最近被和谐的词越来越多了,于是突发奇想,想要自己实现一下敏感词屏蔽. 基本敏感词的屏蔽说起来很简单,只要把字符串中的敏感词替换成"* ...
- KMP算法实现
链接:http://blog.csdn.net/joylnwang/article/details/6778316 KMP算法是一种很经典的字符串匹配算法,链接中的讲解已经是很明确得了,自己按照其讲解 ...
- 数据结构与算法JavaScript (五) 串(经典KMP算法)
KMP算法和BM算法 KMP是前缀匹配和BM后缀匹配的经典算法,看得出来前缀匹配和后缀匹配的区别就仅仅在于比较的顺序不同 前缀匹配是指:模式串和母串的比较从左到右,模式串的移动也是从 左到右 后缀匹配 ...
- 扩展KMP算法
一 问题定义 给定母串S和子串T,定义n为母串S的长度,m为子串T的长度,suffix[i]为第i个字符开始的母串S的后缀子串,extend[i]为suffix[i]与字串T的最长公共前缀长度.求出所 ...
- 字符串模式匹配之KMP算法图解与 next 数组原理和实现方案
之前说到,朴素的匹配,每趟比较,都要回溯主串的指针,费事.则 KMP 就是对朴素匹配的一种改进.正好复习一下. KMP 算法其改进思想在于: 每当一趟匹配过程中出现字符比较不相等时,不需要回溯主串的 ...
- 算法:KMP算法
算法:KMP排序 算法分析 KMP算法是一种快速的模式匹配算法.KMP是三位大师:D.E.Knuth.J.H.Morris和V.R.Pratt同时发现的,所以取首字母组成KMP. 少部分图片来自孤~影 ...
- BF算法与KMP算法
BF(Brute Force)算法是普通的模式匹配算法,BF算法的思想就是将目标串S的第一个字符与模式串T的第一个字符进行匹配,若相等,则继续比较S的第二个字符和 T的第二个字符:若不相等,则比较S的 ...
- KMP算法-next函数求解
KMP函数求解:一种改进的字符串匹配算法,由D.E.Knuth,J.H.Morris和V.R.Pratt同时发现,因此人们称它为KMP算法.KMP算法的关键是利用匹配失败后的信息,尽量减少模式串与主串 ...
随机推荐
- ArcGIS工具 - 统计要素数量
查询和统计是GIS中的重要功能之一.在ArcGIS中可以按属性信息.按空间位置关系进行查询和统计.今天为源GIS给大家分享使用ArcPy编程实现批量统计地理数据库要素类记录数量. 软件应用 统计单个图 ...
- 深入Typescript--03-Typescript中的类(努力加餐饭)
Typescript中的类 一.TS中定义类 class Pointer{ x!:number; // 实例上的属性必须先声明 y!:number; constructor(x:number,y?:n ...
- vue构建打包兼容操作(vue代码规范建议)-转载Vuejs项目不改动一行代码同时支持用Rollup,vue-cli,parcel构建的一些建议
- 创建进程的多种方式、多进程实现TCP并发等知识点
创建进程的多种方式.多进程实现TCP并发等知识点 一.同步与异步 1.提交完成任务之后原地等待任务的返回结果,期间不做任何事 2.提交完任务之后不愿原地等待任务的返回结果,直接去做其他事情,有结果自动 ...
- Boost线程处理机制
采自文章:https://www.cnblogs.com/renyuan/p/6613638.html 大多数共享数据的线程均采用 boost::mutex mtx; boost::condition ...
- 记一次使用gdb诊断gc问题全过程
原创:扣钉日记(微信公众号ID:codelogs),欢迎分享,转载请保留出处. 简介 上次解决了GC长耗时问题后,系统果然平稳了许多,这是之前的文章<GC耗时高,原因竟是服务流量小?> 然 ...
- 大佬们的博客 && 友链
博客 1.https://wiki.kimleo.net/ 查组合子查到的,活化石级别 2.https://tech.meituan.com/ 美团博客,查函数式查到的,我还看过一篇讲aop的非常经典 ...
- 基于Apache Hudi 构建Serverless实时分析平台
NerdWallet 的使命是为生活中的所有财务决策提供清晰的信息. 这涵盖了一系列不同的主题:从选择合适的信用卡到管理您的支出,到找到最好的个人贷款,再到为您的抵押贷款再融资. 因此,NerdWal ...
- MQ 消息队列 比较
为什么需要消息队列 削峰 业务系统在超高并发场景中,由于后端服务来不及同步处理过多.过快的请求,可能导致请求堵塞,严重时可能由于高负荷拖垮Web服务器. 为了能支持最高峰流量,我们通常采取短平快的方式 ...
- Cesium Ellipsoid(十四)
由方程(x/A)^2+(y/b)^2+(z/c)^2=1在笛卡尔坐标系中定义的二次曲面.Cesium主要用来表示行星体的形状.通常使用提供的常量之一,而不是直接构造此对象. 不用new,直接就可以使用 ...