Pytorch数据操作
1.Pytorch中tensor的生成与访问
可以使用arange()创建一个张量:如,torch.arange(12)创建0开始的前12个整数:

除非特殊指定,否则新的张量将存放在内存中,并采用CPU计算。
可以使用reshape()来改变张量的形状:

注意,reshape()的发起者是一个张量,比如这里的x.reshape(),x是一个张量。reshape操作只改变张量的形状,
并不改变张量的大小(元素的数量)以及张量中的值。还可以用x.reshape(-1,4)或x.reshape(3,-1)实现x.reshape(3,4)
同样的功能。
使用tensor.zeros()创建全0的tensor,括号内指定该全0的tensor的形状,如:
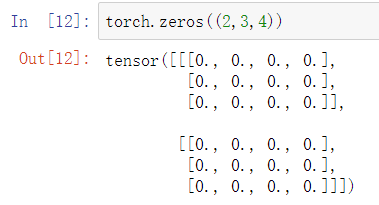
上面的例子创建了一个形状为(2,3,4)的tensor。全1同理:

使用torch.randn()创建均值为0,方差为1的标准正态分布张量,括号内同样是指定张量的形状,如:

还可以用python的列表来为张量指定值和形状,写法为:torch.tensor() :

可以使用torch.zeros_like(y)创建与y同形状的全0张量:

可以使用shape查看张量的形状:
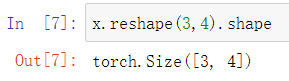
注意,shape的发起者一定也是张量。比如这里的x.reshape(3,4)是shape动作的发起者,它是一个三行四列的张量。
2.Tensor的基本计算
加、减、乘、除、乘方、幂指这些运算,都可以直接用在张量上,表示按元素的计算(element-wise):


使用torch.exp()对张量的每一个元素做以e为底的幂指运算,括号内是某个张量:

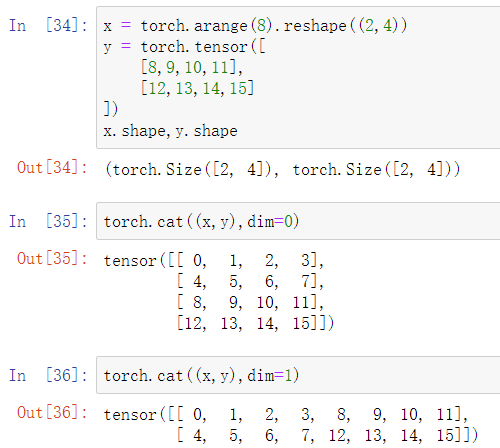
使用torch.cat()拼接两个张量。括号中指出要拼接的两个张量以及dim的值,dim=0是竖着拼,dim=1是横着拼:
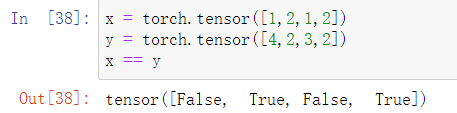
使用“==”对张量中的每一个数值判等,运算结果是一个布尔值构成的张量:
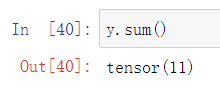
对张量中的所有元素进行求和,会产生一个单元素张量:
广播机制如下面的例子:
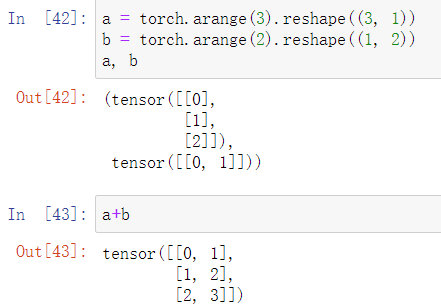
矩阵a将复制自身的列,矩阵b将复制自身的行,然后对应元素相加。
可以使用索引来访问tensor的元素,下面的例子中,X的是2维的,它的每一个元素是一个向量,X[0]访问第一个向量,
X[0,0]访问第一个向量中的第一个值:

特别地,可以用-1访问最后一个元素,用冒号":"进行连续访问:

这里面的"1:3"表示访问“下标”为1的元素(即第二个元素)开始的,连续的元素,一直到下标为3的元素(不包括3,前闭后开)。
还有以下的用法,将矩阵后两行全部赋值0:

将矩阵所有元素赋值0:

3.一个节省内存的方法
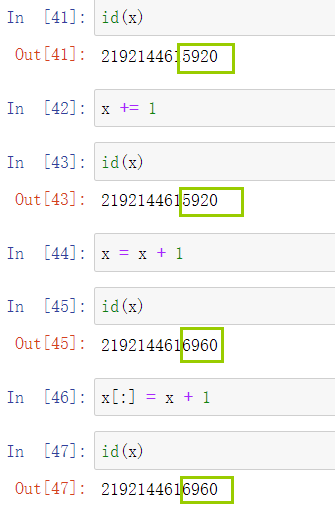
在为张量更新值的时候,如果只是简单的使用“x = expression”这样更新,则会为x分配一个新的内存。这样有两个不好的地方:
1. 机器学习中数据量很大,节约内存是有必要的。
2. 如果我们不原地更新,其他引用仍然可能指向旧的内存,这样可能会导致某些代码指向旧的参数。
原地更新的方法是:使用如x += 1代替x = x + 1 或使用切片:
4.Tensor与其他Python对象的转换
Pytorch的张量与Numpy的张量(ndarray)很容易相互转换:

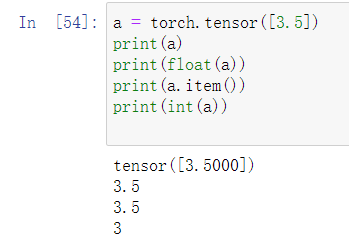
Pytorch的只有一个元素,大小为1的张量同样可以很轻松地转换为python标量,可以使用item()函数,或强制类型转换,
如float(),int()等:
Pytorch数据操作的更多相关文章
- pytorch 数据操作
数据操作 在深度学习中,我们通常会频繁地对数据进行操作.作为动手学深度学习的基础,本节将介绍如何对内存中的数据进行操作. 在PyTorch中,torch.Tensor是存储和变换数据的主要工具.如果你 ...
- 【转载】PyTorch系列 (二):pytorch数据读取
原文:https://likewind.top/2019/02/01/Pytorch-dataprocess/ Pytorch系列: PyTorch系列(一) - PyTorch使用总览 PyTorc ...
- Pytorch数据读取框架
训练一个模型需要有一个数据库,一个网络,一个优化函数.数据读取是训练的第一步,以下是pytorch数据输入框架. 1)实例化一个数据库 假设我们已经定义了一个FaceLandmarksDataset数 ...
- PyTorch数据加载处理
PyTorch数据加载处理 PyTorch提供了许多工具来简化和希望数据加载,使代码更具可读性. 1.下载安装包 scikit-image:用于图像的IO和变换 pandas:用于更容易地进行csv解 ...
- PyTorch 数据并行处理
PyTorch 数据并行处理 可选择:数据并行处理(文末有完整代码下载) 本文将学习如何用 DataParallel 来使用多 GPU. 通过 PyTorch 使用多个 GPU 非常简单.可以将模型放 ...
- StackExchange.Redis帮助类解决方案RedisRepository封装(字符串类型数据操作)
本文版权归博客园和作者本人共同所有,转载和爬虫请注明原文链接 http://www.cnblogs.com/tdws/tag/NoSql/ 目录 一.基础配置封装 二.String字符串类型数据操作封 ...
- hive数据操作
mdl是数据操作类的语言,包括向数据表加载文件,写查询结果等操作 hive有四种导入数据的方式 >从本地加载数据 LOAD DATA LOCAL INPATH './examples/files ...
- Dapper 数据操作框架
数据操作DapperFrom NuGet:Install-Package DapperorInstall-Package Dapper.StrongName微型ORM:PetaPoco获得PetaPo ...
- Django数据操作F和Q、model多对多操作、Django中间件、信号、读数据库里的数据实现分页
models.tb.objects.all().using('default'),根据using来指定在哪个库里查询,default是settings中配置的数据库的连接名称. 外话:django中引 ...
- coreData数据操作
// 1. 建立模型文件// 2. 建立CoreDataStack// 3. 设置AppDelegate 接着 // // CoreDataStack.swift // CoreDataStackDe ...
随机推荐
- Jmeter--请求结果写入文件并生成报告
一.数据写入文件 Jmeter中监听器控件中,都可以将"所有数据写入一个文件",且文件形式有:xml\jtl\csv 在需要写入的监听器下点击"浏览"按钮,选择 ...
- 用VUE框架开发的准备
使用VUE框架编写项目的准备工作 防止我几天不打代码,忘记怎么打了 下载小乌龟拉取码云项目文件,用于码云仓库代码提交与拉取(可以不安装) 小乌龟要设置你的码云账号 密码 在控制面版 中 凭证里可以修改 ...
- python selenium 操作文件上传,并发操作时,文件选择窗口混乱解决方案
上传文件 使用的是 python + autoit 模块,这种方式有一个问题,当出现多条任务同时选择文件上传的时候,无法判断那个文件选择窗口的归属,从而出现上传了错误的文件! 解决方法: 要上载文件而 ...
- jdk8 stream部分排序方法
List<类> list; 代表某集合 //返回 对象集合以类属性一升序排序 list.stream().sorted(Comparator.comparing(类::属性一)); ...
- 在jsp页面int和String类型的相互转换
浅浅地来做一个对比吧! .java文件 int转成string类型:String s=String.valueOf(int m); String转成int类型:int m=Integer.parseI ...
- 17.explicit关键字
c++提供了关键字explicit,禁止通过构造函数进行的隐式转换.声明为explicit的构造函数不能在隐式转换中使用. [explicit注意] ● explicit用于修饰构造函数,防止隐式转化 ...
- 什么是mvvm?简单介绍它的概念、原理及实现
1.MVVM的概念 model-view-viewModel,通过数据劫持+发布订阅模式来实现. mvvm是一种设计思想.Model代表数据模型,可以在model中定义数据修改和操作的业务逻辑;vie ...
- 创建镜像发布到镜像仓库【不依赖docker环境】
image 工具背景 如今,docker镜像常用于工具的分发,demo的演示,第一步就是得创建docker镜像.一般入门都会安装docker,然后用dockerFile来创建镜像,除此以外你还想过有更 ...
- 有执行语句:console.log(fn2(2)[3]),补充函数,使执行结果为"hello"
function fn2(a){ return [1,2,3,"hello"];}console.log(fn2(2)[3])//hello 这个2是混淆视线的,即使没有这个2.函 ...
- Oracle_表空间
Oracle 表空间 在执行具体的操作之前,由于Oracle不允许删除现有临时表空间,所以在删除现有临时表空间时要终止现有的实时会话. 查询Oracle表空间名称,表空间物理文件路径 查询临时表空间: ...