kafka详解(二)--kafka为什么快
前言
Kafka 有多快呢?我们可以使用 OpenMessaging Benchmark Framework 测试框架方便地对 RocketMQ、Pulsar、Kafka、RabbitMQ 等消息系统进行对比测试,因为暂时没有测试条件(后续补上),我直接用这篇文章的测试结果(Benchmarking Kafka vs. Pulsar vs. RabbitMQ: Which is Fastest?),可以看到,在某种条件下,Kafka 写入速度比 RabbitMQ 快 15 倍,比 Pulsar 快 2 倍,在最高吞吐量下仍保持低延迟。

那么,为什么 Kafka 可以那么快呢?这里我先简单总结,后面会展开分析。
- 从磁盘中顺序读写 event。
- 通过批处理减少大量小 I/O。
- 从文件到 socket 之间数据零拷贝。
- 基于分区的横向扩展。
ps:[本系列](博客后台 - 博客园 (cnblogs.com))博客将持续更新。
顺序读写磁盘
Kafka 严重依赖文件系统来读写 event。我们不禁会问,磁盘不是很慢吗?Kafka 真的能提供很好的性能吗?
事实上,磁盘比人们预期的要慢得多,也快得多,这取决于它们的使用方式。在这篇文章中(ACM Queue article)可以发现,在某些情况下,顺序磁盘访问可能比随机内存访问更快。这要得益于现代操作系统对磁盘读写进行的大量的优化,包括 read-ahead 和 write-behind 技术,当我们顺序读取磁盘时,更多时候访问的不是磁盘,而是内存--pagecache。
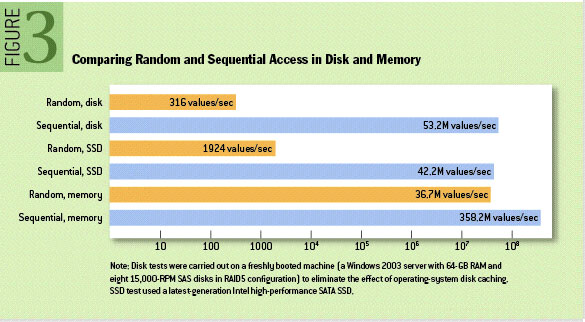
因此,只要顺序访问文件系统,磁盘也可以很快。Kafka 的 event 组织方式以及应用场景,天然地支持了顺序读写,并且 Kafka 也为此做了许多努力,例如批处理、追加写入等。
此外,相比主动将 event 维护在内存,采用文件系统还有以下好处:
可以缓存更多的数据。在 JVM 中,维护对象的内存开销将是实际数据大小的两倍甚至更糟,随着堆内数据的增加,gc 将愈发频繁。而使用文件系统可以在 pagecache 中缓存更多更紧凑的数据,而不需要考虑 gc 问题。
重启后恢复更快。由于数据缓存在 pagecache,进程重启,这部分缓存仍然可以保持 warn 的状态,如果在进程内存中维护这些数据的话,每次启动都需要重建(对于 10GB 缓存可能需要 10 分钟)。
数据不会丢失。如果数据维护在内存中,需要考虑定期将数据持久化到磁盘,一致性和性能的权衡将是一个比较麻烦的问题,即便如此,我们也不能保证数据不会丢失,例如 redis 可能损失几秒的数据,甚至更多。在理论上,Kafka 就不会出现数据丢失的情况。
大大简化了代码。用于维护缓存和文件系统之间一致性的所有逻辑现在都在操作系统中,而操作系统往往更高效、更正确。
通过批处理减少小I/O
小 I/O 操作发生在客户端和服务端之间的数据传输以及服务端自身的持久化操作。
为了避免小 I/O 操作,Kafka 是以批的形式来操作 event,而不是一次发送一条消息。producer 会尝试在内存中积累数据,并在单个请求中发送更大的批,当然,这种方式是牺牲少量额外延迟以获得更好的吞吐量,我们可以配置累积数量和等待时间来平衡。同理,consumer 读取数据时也会尝试一次读取更多。
批处理可以产生较大顺序磁盘操作和连续内存块,不过也产生了较大的网络数据包,相应地,Kafaka 会将消息压缩后发送,当消息写入日志时仍然是压缩形式,仅由使用者解压缩。
数据零拷贝
另一个问题是过多的字节复制。//zzs001
一般情况下,数据从文件传输到 socket 的数据路径为:磁盘 -》内核的 pagecache -》用户空间缓冲区 -》内核的 socket 缓冲区 -》NIC 缓冲区。
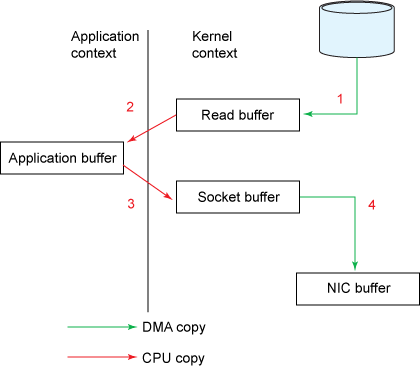
显然,这是非常低效的,有四个副本和两个系统调用。Kafka 使用 sendfile,允许操作系统将数据从 pagecache 直接发送到网络,即磁盘 -》内核的 pagecache-》NIC 缓冲区。从而避免这种重复复制和系统调用。更多关于 sendfile 的内容可以参考Efficient data transfer through zero copy。
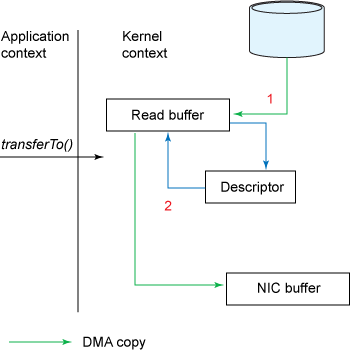
需要注意的是,由于 TLS/SSL 库是工作在用户空间的,所以,当启用了 SSL,sendfile 将不能使用。
基于分区的横向扩展
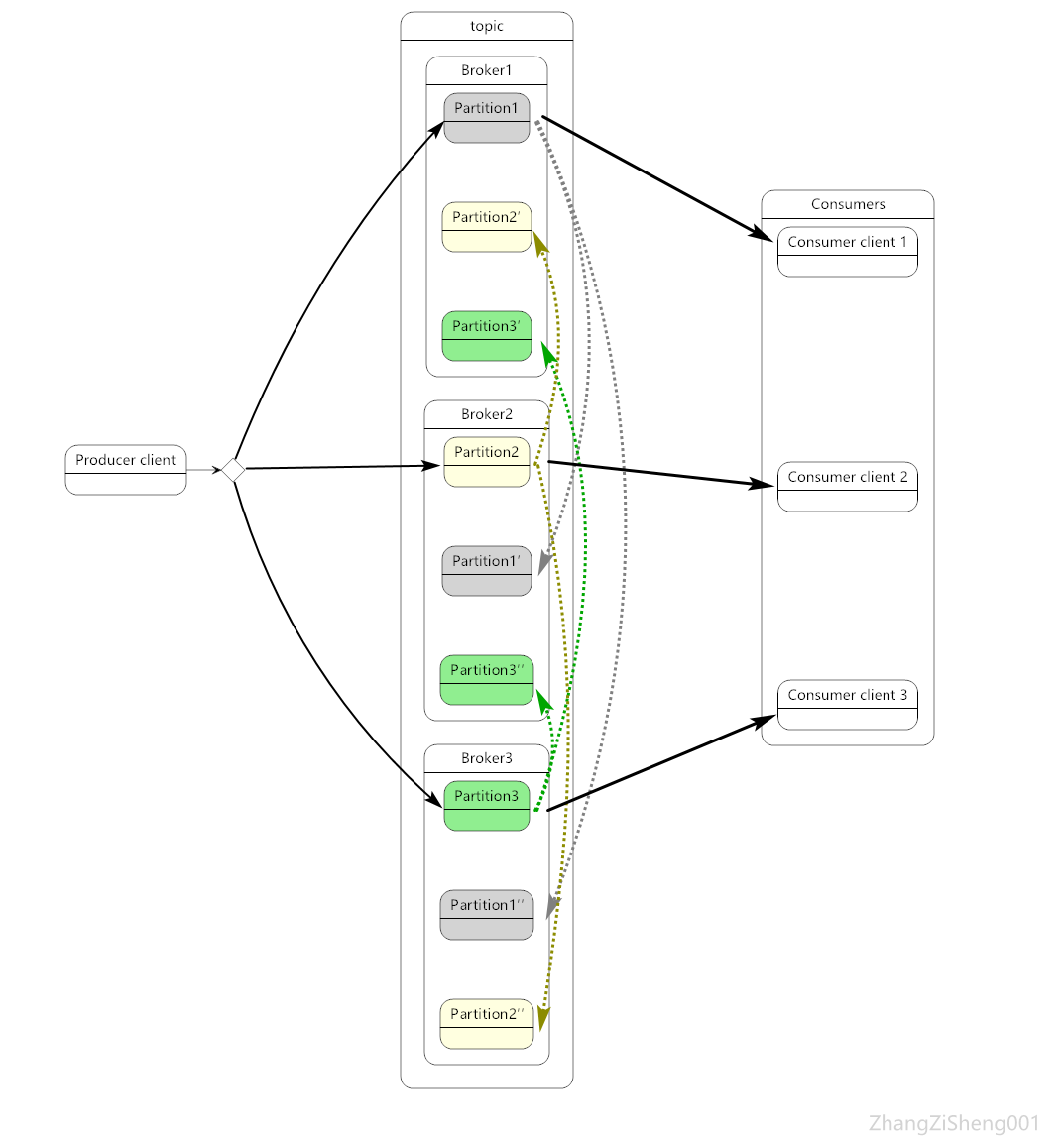
关于这一点,在上一篇博客中其实已经提到过。首先,一个 topic 会划分成一个或多个 partition,这些 partition 一般分布在不同的 broker 实例。producer 发布的 event 会根据某种策略分配到不同的 partition,这样做的好处是,consumer 可以同时从多台 broker 读取 event,从而大大提高吞吐量。另外,为了高可用,同一个 partition 还会有多个副本,它们分布在不同的 broker 实例,和很多传统的消息系统不同,Kafka 的副本是可读的,即 consumer 不仅可以从主 partition 读取 event,也可以从副本读取。//zzs001
结语
以上内容是最近学习 Kafka 的一些思考和总结(主要参考官方文档),如有错误,欢迎指正。
任何的事物,都可以被更简单、更连贯、更系统地了解。希望我的文章能够帮到你。
最后,感谢阅读。
参考资料
Benchmarking Kafka vs. Pulsar vs. RabbitMQ: Which is Fastest?
The OpenMessaging Benchmark Framework
The Pathologies of Big Data - ACM Queue
Efficient data transfer through zero copy - IBM Developer
本文为原创文章,转载请附上原文出处链接:https://www.cnblogs.com/ZhangZiSheng001/p/16788561.html
kafka详解(二)--kafka为什么快的更多相关文章
- Kafka详解二:如何配置Kafka集群
问题导读1.Kafka有哪几种配制方法?2.如何启动一个Consumer实例来消费消息? Kafka集群配置比较简单,为了更好的让大家理解,在这里要分别介绍下面三种配置 单节点:一个broker的集群 ...
- kafka详解(一)--kafka是什么及怎么用
kafka是什么 在回答这个问题之前,我们需要先了解另一个东西--event streaming. 什么是event streaming 我觉得,event streaming 是一个动态的概念,它描 ...
- .NET DLL 保护措施详解(二)关于性能的测试
先说结果: 加了缓存的结果与C#原生代码差异不大了 我对三种方式进行了测试: 第一种,每次调用均动态编译 第二种,缓存编译好的对象 第三种,直接调用原生C#代码 .net dll保护系列 ------ ...
- PopUpWindow使用详解(二)——进阶及答疑
相关文章:1.<PopUpWindow使用详解(一)——基本使用>2.<PopUpWindow使用详解(二)——进阶及答疑> 上篇为大家基本讲述了有关PopupWindow ...
- Android 布局学习之——Layout(布局)详解二(常见布局和布局参数)
[Android布局学习系列] 1.Android 布局学习之——Layout(布局)详解一 2.Android 布局学习之——Layout(布局)详解二(常见布局和布局参数) 3.And ...
- logback -- 配置详解 -- 二 -- <appender>
附: logback.xml实例 logback -- 配置详解 -- 一 -- <configuration>及子节点 logback -- 配置详解 -- 二 -- <appen ...
- 爬虫入门之urllib库详解(二)
爬虫入门之urllib库详解(二) 1 urllib模块 urllib模块是一个运用于URL的包 urllib.request用于访问和读取URLS urllib.error包括了所有urllib.r ...
- [转]文件IO详解(二)---文件描述符(fd)和inode号的关系
原文:https://www.cnblogs.com/frank-yxs/p/5925563.html 文件IO详解(二)---文件描述符(fd)和inode号的关系 ---------------- ...
- Android View 的绘制流程之 Layout 和 Draw 过程详解 (二)
View 的绘制系列文章: Android View 的绘制流程之 Measure 过程详解 (一) Android View 绘制流程之 DecorView 与 ViewRootImpl 在上一篇 ...
随机推荐
- qbxt五一数学Day2
目录 1. 判断素数(素性测试) 1. \(O(\sqrt n)\) 试除 2. Miller-Rabin 素性测试 * 欧拉函数 2. 逆元 3. exgcd(扩展欧几里得) 4. 离散对数(BSG ...
- windows下memcache安装
Windows下的Memcache安装:1. 下载memcache的windows稳定版,解压放某个盘下面,比如在c:memcached2. 在终端(也即cmd命令界面)下输入 'c:memcache ...
- 后端编写Swagger接口管理文档
Swagger接口管理文档 访问接口文档的网页:http://localhost:8080/swagger-ui/index.html 导入依赖 <dependency> <grou ...
- Ray类定义
定义光线,书中已经有原理. 类声明: #ifndef __RAY_HEADER__ #define __RAY_HEADER__ #include "geometry.h" cla ...
- MySQL通配符与正则表达式
通配符 通配符必须全文匹配时才为真,使用LIKE关键字 字符 示例 含义 _ "a_b" 任意一个字符"axb",其中x可以使任意字符,包括汉字 % " ...
- Luogu2343 宝石管理系统(平衡树)
平衡树维护总第K大:插入 #include <iostream> #include <cstdio> #include <cstring> #include < ...
- SP104 Highways (矩阵树,高斯消元)
矩阵树定理裸题 //#include <iostream> #include <cstdio> #include <cstring> #include <al ...
- Mysql和Redis数据如何保持一致
先阐明一下Mysql和Redis的关系:Mysql是数据库,用来持久化数据,一定程度上保证数据的可靠性:Redis是用来当缓存,用来提升数据访问的性能. 关于如何保证Mysql和Redis中的数据一致 ...
- 如何免费申请js.org二级域名
最近看到很多人都去申请了js.org的域名,我就来写个教程吧! (本教程只注重于申请域名,而不是如何使用Github) 看看成品:https://butterfly.js.org/ 官网是这么写的: ...
- openstack 搭建详细步骤
该博文转载于(https://www.cnblogs.com/whwh/p/16200004.html) 一.openstack单点部署 1.配置虚拟机NAT网络连接 查看vmware的NAT网络默认 ...