week_6
Andrew Ng 机器学习笔记 ---By Orangestar
Week_6 (1)
In Week 6, you will be learning about systematically improving your learning algorithm. The videos for this week will teach you how to tell when a learning algorithm is doing poorly, and describe the 'best practices' for how to 'debug' your learning algorithm and go about improving its performance.
1. Deciding What to Try Next
如何改进算法?
- 使用更多样本
- 尝试更少的特征参数
- 尝试用更多的特征参数
- 尝试多元参数
- 试着降低或者升高正则参数
但是,选择一种有效的方法是困难的
所以,我们需要评估一个机器学习算法的性能的方法
Machine learning diagnostic
定义:

2. Evaluating a Hypothesis
如何评估假设函数以及避免过拟合和欠拟合?
如何评价假设函数?
将数据分割:按照某个比例
1.常用训练集
2.测试集
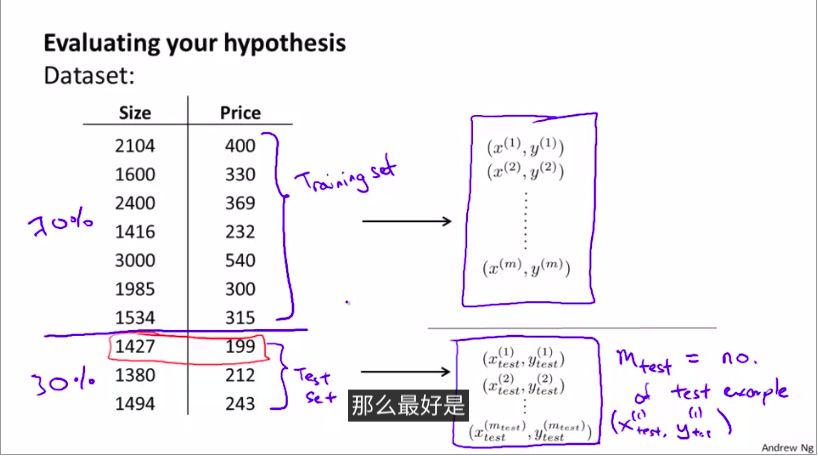
基本步骤:
- (回归问题):(线性回归)

(分类问题):(逻辑回归)
差不多,用测试集评估。
问题是:如何计算error(0/1)?
其实和之前差不多,要定义决策界限

用0/1错分率来定义error
总结:

3. Model Selection and Train/Validation /Test Sets
模型选择问题//训练集//验证集//测试集
模型选择:

还需要选择一个参数d. 也就是最高次数。
可以逐个选择,然后逐个算出测试集的误差函数。
然后观察哪个最小。
而且,这样选出的模型,可能仅仅是可以很好的拟合测试集,但是其他的说不定。所以,我们仅仅是用测试集来拟合样本。不公平!
所以,我们可以用 交叉验证集!cross validation set

现在把数据集分为3个部分:

就是说,验证是最好的模型,可以用交叉验证集来检验!然后,就没有和测试集进行拟合,回避了测试集的嫌疑

一般的比例为:

4. Diagnosing Bias vs. Variance
如何判断一个算法,是和方差有问题还是和偏差有问题?
用图像来直观理解
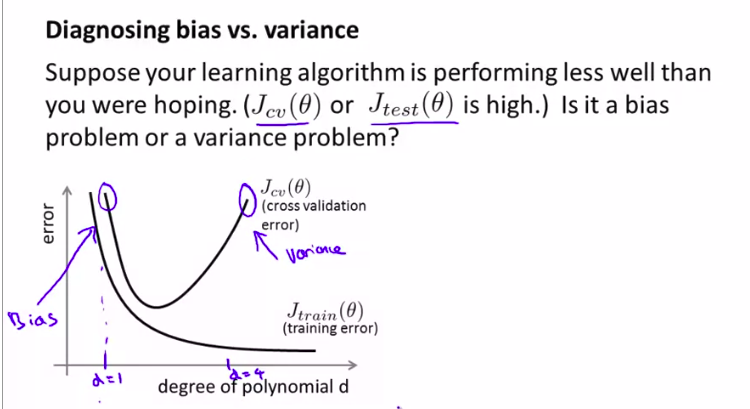
注意理解bias error 和 variance error
也就是,区分过拟合和欠拟合的情况

当然,这两种情况都是不好的!
5. Regularization and Bias / Variance
更深入地 探讨一下偏差和方差的问题 讨论一下两者之间 是如何相互影响的 以及和算法的正则化之间的相互关系
首先,我们来看一下正则项:
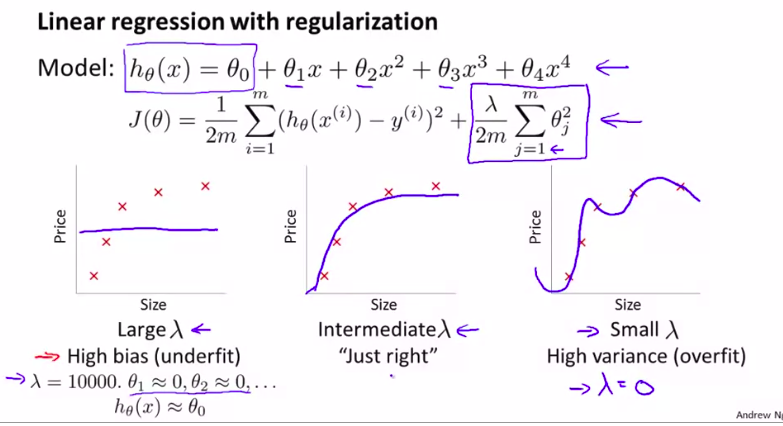
当然,我们需要先用交叉验证集上进行选择模型
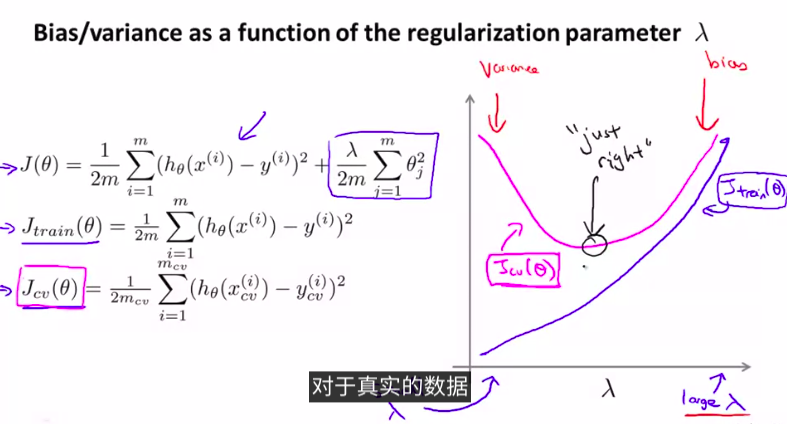
再试着用哪一个正则项更好。来得到最小的J_train_
如图:
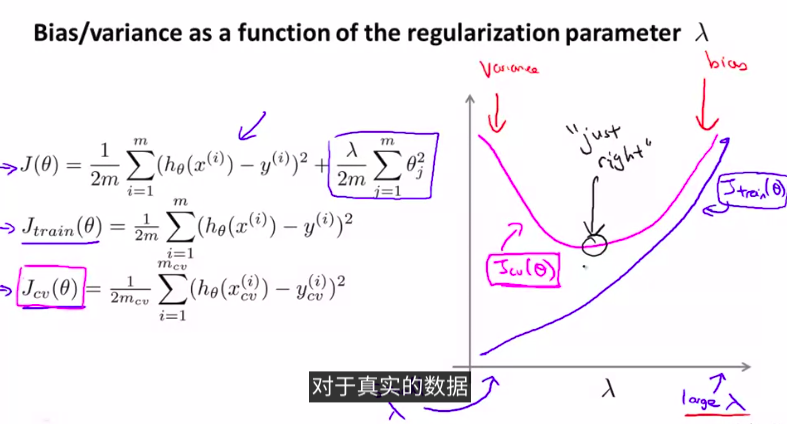
总结步骤:

- for each λ go through all the models to learn some Θ.
- without regularization or λ = 0
以上两点很重要
6. 学习曲线learning curves
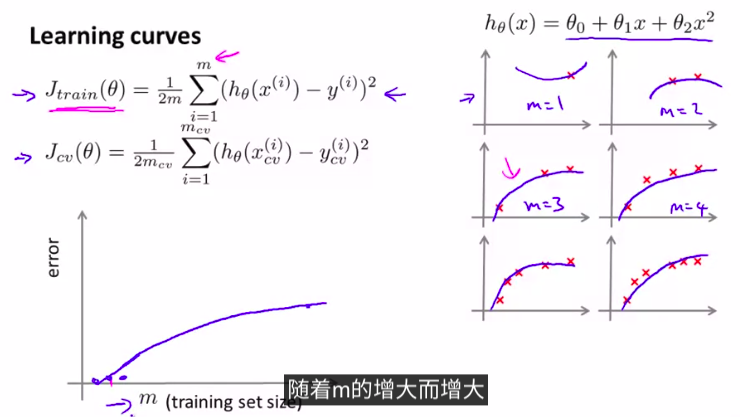
一种模型,当训练集的样本增加的时候,error是越来越大的
- 高偏差情况high bias(欠拟合)
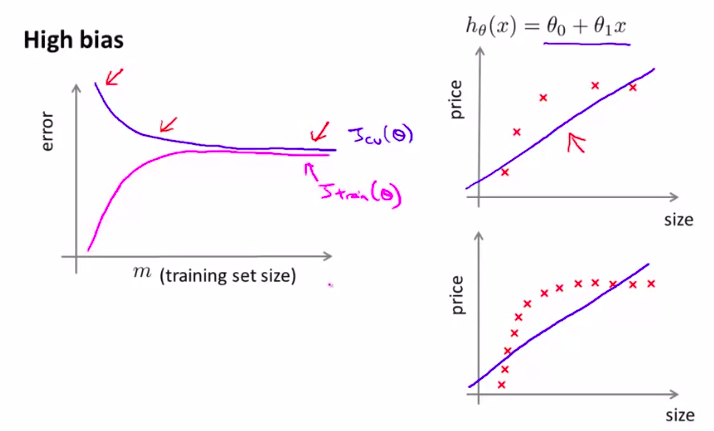
结论:

所以,如果模型是高偏差,再多的样本来拟合,也不太会管用
- 高方差情况high variance(过拟合)
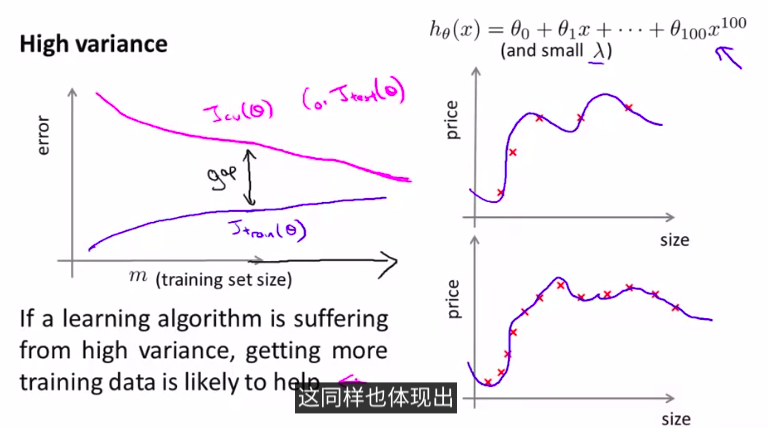
这种情况下,使用更多的样本是有帮助的
总结:
画出曲线,可以更容易看出是高偏差还是高方差的问题,然后来选择改进算法




7. Deciding What to Do Next Revisited
当我们发现方差或者偏差出了问题,我们应该怎么做?

如何和神经网络联系/
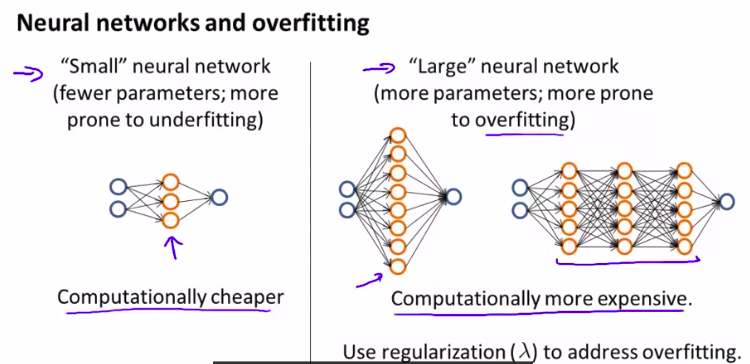
如果发生过拟合,可以使用正则化
但是,计算量更大。如何选择hiding layer?
想用多个隐藏层。可以尝试着数据分割。
总结:
Our decision process can be broken down as follows:
Getting more training examples: Fixes high variance
Trying smaller sets of features: Fixes high variance
Adding features: Fixes high bias
Adding polynomial features: Fixes high bias
Decreasing λ: Fixes high bias
Increasing λ: Fixes high variance.
Diagnosing Neural Networks
- A neural network with fewer parameters is prone to underfitting. It is also computationally cheaper.
- A large neural network with more parameters is prone to overfitting. It is also computationally expensive. In this case you can use regularization (increase λ) to address the over-fitting.
Using a single hidden layer is a good starting default. You can train your neural network on a number of hidden layers using your cross validation set. You can then select the one that performs best.
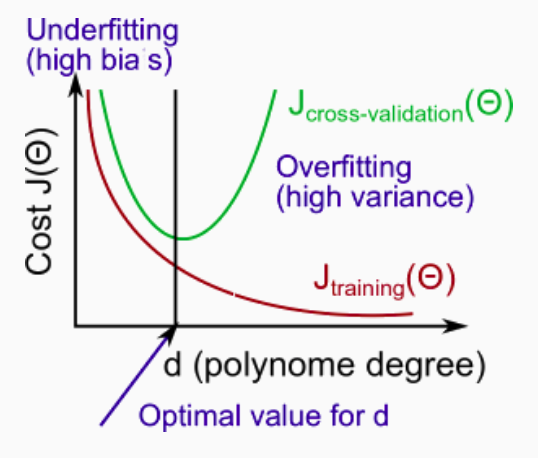
Model Complexity Effects:
- Lower-order polynomials (low model complexity) have high bias and low variance. In this case, the model fits poorly consistently.
- Higher-order polynomials (high model complexity) fit the training data extremely well and the test data extremely poorly. These have low bias on the training data, but very high variance.
- In reality, we would want to choose a model somewhere in between, that can generalize well but also fits the data reasonably well.
week_6的更多相关文章
随机推荐
- 打造企业自己代码规范IDEA插件(上)
"交流互鉴是文明发展的本质要求.只有同其他文明交流互鉴.取长补短,才能保持旺盛生命活力." 这说的是文明,但映射到计算机技术本身也是相通的,开源代码/项目就是一种很好的技术交流方式 ...
- C++运算符重载(简单易懂)
转载:https://www.cnblogs.com/liuchenxu123/p/12538623.html 运算符重载,就是对已有的运算符重新进行定义,赋予其另一种功能,以适应不同的数据类型. 你 ...
- Period of an Infinite Binary Expansion 题解
Solution 简单写一下思考过程,比较水的数论题 第一个答案几乎已经是可以背下来的,在此不再赘述 考虑我们已经知道了\((p,q)\),其中\((p \perp q) \wedge (q \per ...
- 齐博x1小程序集群一个重要功能升级,可以根据圈子会员组显示不同的菜单。
如下图所示,虽然之前圈子小程序可以自定义会员中心菜单,但是存在一个问题,就是所有会员,比如圈主与普通会员的菜单都将是一样的. 现在升级后,就可以设置不同的圈子会员组,拥有不同的菜单. 比如一个商家,店 ...
- JavaScript基础复盘补缺
语法规范 JavaScript严格区分大小写,对空格.换行.缩进不敏感,建议语句结束加':' JavaScript 会忽略多个空格.您可以向脚本添加空格,以增强可读性. JavaScript 程序员倾 ...
- 题解 AT2361 [AGC012A] AtCoder Group Contest
\(\sf{Solution}\) 显然要用到贪心的思想. 既然最终的结果只与每组强度第二大选手有关,那就考虑如何让他的值尽可能大. 其实,从小到大排个序就能解决,越靠后的值越大,使得每组强度第二大选 ...
- 三、celery执行定时任务
三.Celery执行定时任务 设定时间让celery执行一个 定时任务,product_task.py from celery_task import send_email from datetime ...
- 一次 Java log4j2 漏洞导致的生产问题
一.问题 近期生产在提交了微信小程序审核后(后面会讲到),总会出现一些生产告警,而且持续时间较长.我们查看一些工具和系统相关的,发现把我们的 gateway 差不多打死了. 有一些现象. 网关有很多接 ...
- java代码整洁之道
package Day01;import org.junit.Test;import java.text.NumberFormat;import java.util.Scanner;public cl ...
- 【题解】CF631B Print Check
题面传送门 解决思路: 首先考虑到,一个点最终的情况只有三种可能:不被染色,被行染色,被列染色. 若一个点同时被行.列染色多次,显示出的是最后一次被染色的结果.所以我们可以使用结构体,对每一行.每一列 ...