week_6
Andrew Ng 机器学习笔记 ---By Orangestar
Week_6 (1)
In Week 6, you will be learning about systematically improving your learning algorithm. The videos for this week will teach you how to tell when a learning algorithm is doing poorly, and describe the 'best practices' for how to 'debug' your learning algorithm and go about improving its performance.
1. Deciding What to Try Next
如何改进算法?
- 使用更多样本
- 尝试更少的特征参数
- 尝试用更多的特征参数
- 尝试多元参数
- 试着降低或者升高正则参数
但是,选择一种有效的方法是困难的
所以,我们需要评估一个机器学习算法的性能的方法
Machine learning diagnostic
定义:

2. Evaluating a Hypothesis
如何评估假设函数以及避免过拟合和欠拟合?
如何评价假设函数?
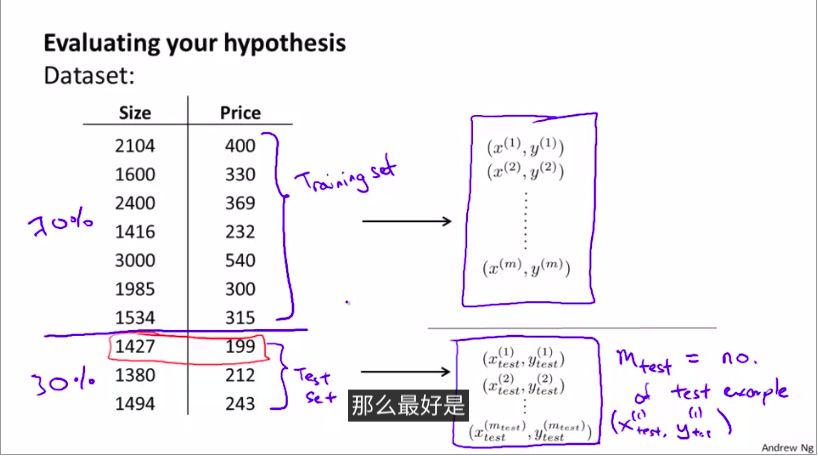
将数据分割:按照某个比例
1.常用训练集
2.测试集
基本步骤:
- (回归问题):(线性回归)

(分类问题):(逻辑回归)
差不多,用测试集评估。
问题是:如何计算error(0/1)?
其实和之前差不多,要定义决策界限

用0/1错分率来定义error
总结:

3. Model Selection and Train/Validation /Test Sets
模型选择问题//训练集//验证集//测试集
模型选择:

还需要选择一个参数d. 也就是最高次数。
可以逐个选择,然后逐个算出测试集的误差函数。
然后观察哪个最小。
而且,这样选出的模型,可能仅仅是可以很好的拟合测试集,但是其他的说不定。所以,我们仅仅是用测试集来拟合样本。不公平!
所以,我们可以用 交叉验证集!cross validation set

现在把数据集分为3个部分:

就是说,验证是最好的模型,可以用交叉验证集来检验!然后,就没有和测试集进行拟合,回避了测试集的嫌疑

一般的比例为:

4. Diagnosing Bias vs. Variance
如何判断一个算法,是和方差有问题还是和偏差有问题?
用图像来直观理解
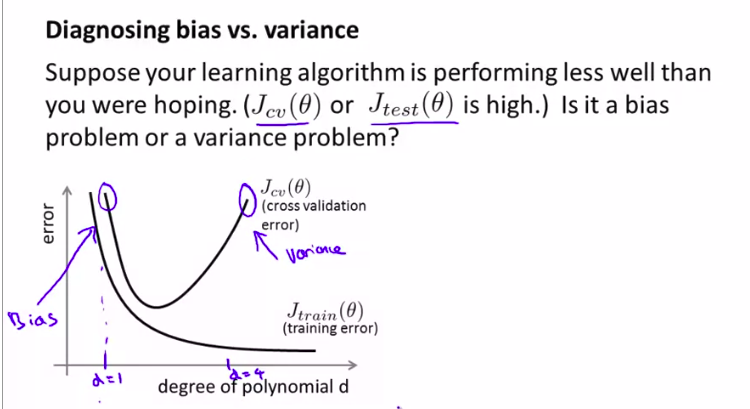
注意理解bias error 和 variance error
也就是,区分过拟合和欠拟合的情况

当然,这两种情况都是不好的!
5. Regularization and Bias / Variance
更深入地 探讨一下偏差和方差的问题 讨论一下两者之间 是如何相互影响的 以及和算法的正则化之间的相互关系
首先,我们来看一下正则项:
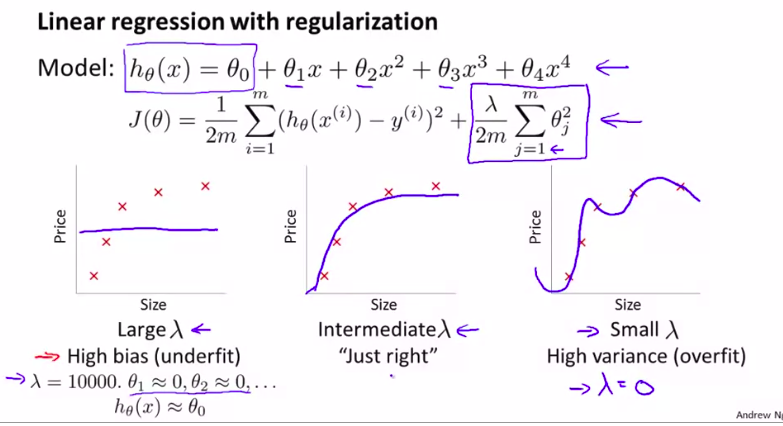
当然,我们需要先用交叉验证集上进行选择模型
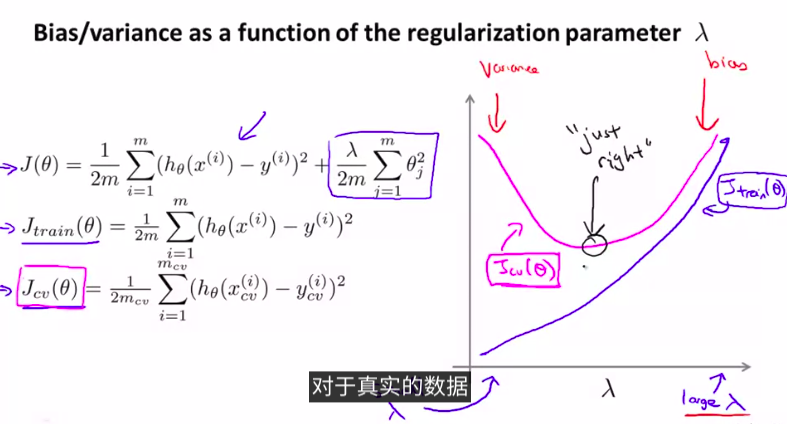
再试着用哪一个正则项更好。来得到最小的J_train_
如图:
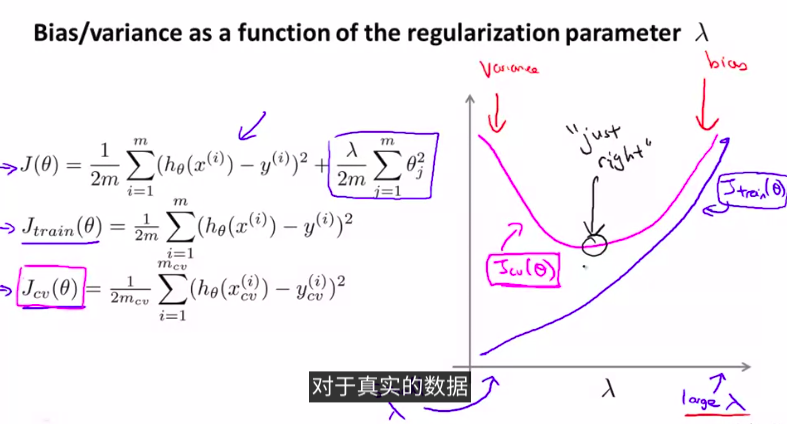
总结步骤:

- for each λ go through all the models to learn some Θ.
- without regularization or λ = 0
以上两点很重要
6. 学习曲线learning curves
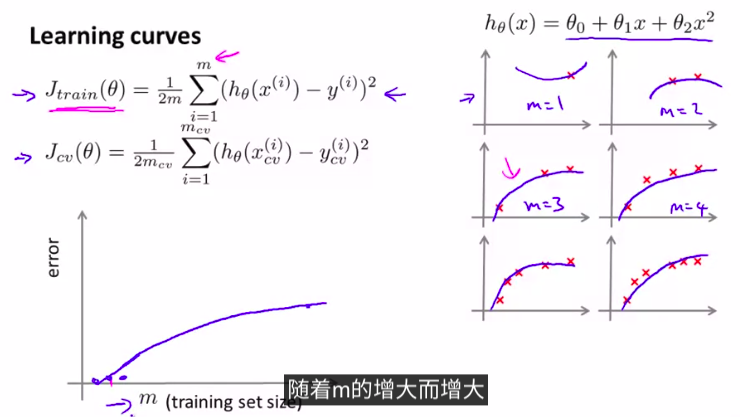
一种模型,当训练集的样本增加的时候,error是越来越大的
- 高偏差情况high bias(欠拟合)
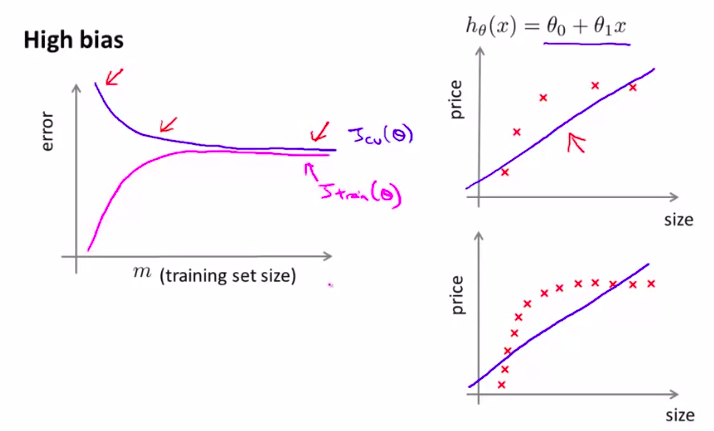
结论:

所以,如果模型是高偏差,再多的样本来拟合,也不太会管用
- 高方差情况high variance(过拟合)
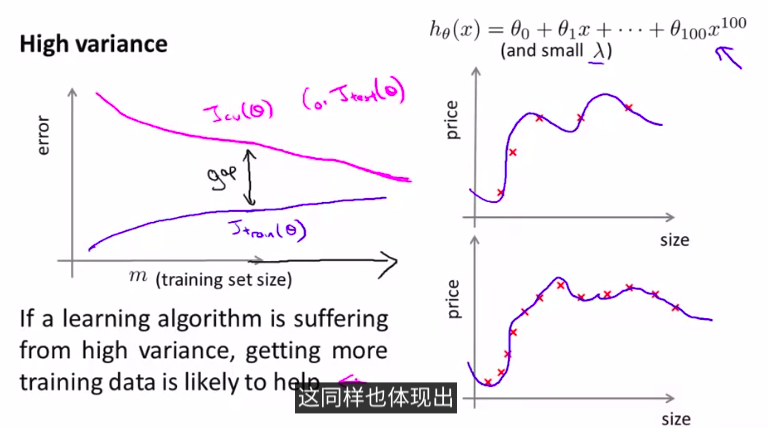
这种情况下,使用更多的样本是有帮助的
总结:
画出曲线,可以更容易看出是高偏差还是高方差的问题,然后来选择改进算法




7. Deciding What to Do Next Revisited
当我们发现方差或者偏差出了问题,我们应该怎么做?

如何和神经网络联系/
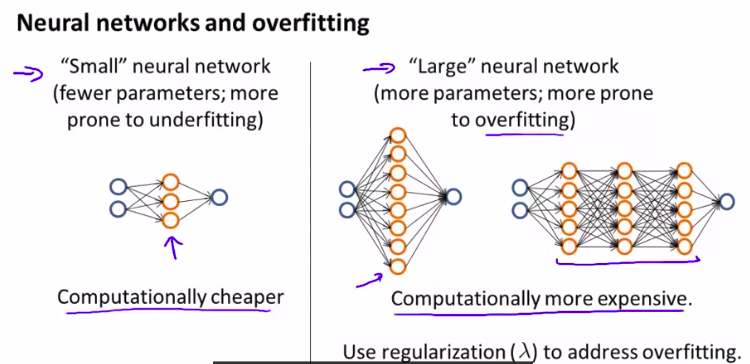
如果发生过拟合,可以使用正则化
但是,计算量更大。如何选择hiding layer?
想用多个隐藏层。可以尝试着数据分割。
总结:
Our decision process can be broken down as follows:
Getting more training examples: Fixes high variance
Trying smaller sets of features: Fixes high variance
Adding features: Fixes high bias
Adding polynomial features: Fixes high bias
Decreasing λ: Fixes high bias
Increasing λ: Fixes high variance.
Diagnosing Neural Networks
- A neural network with fewer parameters is prone to underfitting. It is also computationally cheaper.
- A large neural network with more parameters is prone to overfitting. It is also computationally expensive. In this case you can use regularization (increase λ) to address the over-fitting.
Using a single hidden layer is a good starting default. You can train your neural network on a number of hidden layers using your cross validation set. You can then select the one that performs best.
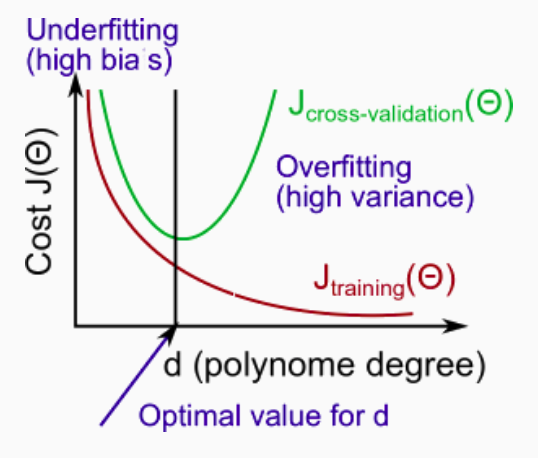
Model Complexity Effects:
- Lower-order polynomials (low model complexity) have high bias and low variance. In this case, the model fits poorly consistently.
- Higher-order polynomials (high model complexity) fit the training data extremely well and the test data extremely poorly. These have low bias on the training data, but very high variance.
- In reality, we would want to choose a model somewhere in between, that can generalize well but also fits the data reasonably well.
week_6的更多相关文章
随机推荐
- js移除style样式
removeAttribute() 例: <button @click="edit" type="button" disabled id="bt ...
- Charles的安装与使用
Charles是一款抓包工具,可以用来截取和发送手机APP上的各种请求 在windows上安装Charles,确保手机和电脑在同一个WIFI下,加上一些配置,就可以抓取手机上的APP请求 有能力的同学 ...
- vim编译器
光标移动,模式切换,删除,查找,复制,粘贴,撤销 vim的三种模式(重点) vim存在的三种模式 命令模式,编辑模式,尾行模式 命令 模式:不能直接编辑.但是可以用快捷键进行一些操作(删除,复制,移动 ...
- Day2:基本的Dos命令
打开CMD的方式 开始+系统+命令提示符(右键以管理员身份运行可拿到最高权限) Win键+R 输入 cmd打开控制台(推荐使用) 桌面上按住shift+鼠标右键,打开powershell窗口 文件搜索 ...
- MYSQL一键导库脚本
上周完成了一个性能测试环境搭建,有富余时间的同时研究了一个一键导库的脚本,一周的开始先马住!!! 一.思路 准备:54.158服务器上分别已经装好了MYSQL数据库 目的:把部分库从54导出并导入到1 ...
- 微信小程序的学习(二)
一.数据绑定 1.数据绑定的基本原则 在 data 中定义数据 在 wxml 中使用数据 2.如何在 data 里面定义数据? 在页面对应的 .js 文件中,把数据定义到 data 对象中即可: 3. ...
- xmind下载安装破解版激活教程思维导图软件获取
1.xmind下载解压压缩包就可以看到里面的文件,然后双击安装文件就可以开始安装了 2.安装Xmind程序双击之后会出现下面的流程,照着截图操作,不要乱点哈 切记切记!!这一步直接点击next,不要修 ...
- C#.NET实现二分查找
二分搜索法 定义 二分法查找,也称为折半法,是一种在有序数组中查找特定元素的搜索算法. 适用范围 当数据量很大并且有序时,适宜采用该方法. 基本思想 假设数据是按升序排序的,对于给定值key,从序列的 ...
- ARMv8之memory model和Observability(四)
最近在学习整理ARMv8的memory 相关知识,对memory的各种概念搞的头痛,太难读了!!有幸看看窝窝大神整理了部分知识,关键是讲解的地道,透彻.因此在这里学习并转载一下,也希望能够和大家一起探 ...
- Redux 的困扰与如何技术选型
文章的名字我想了很久,备选项有"我再不推荐 Redux","Redux 为什么令我头疼","Redux 进化启示录"等等.通过这一系列名字我 ...